 Online Python Console
Online Python Console One-time Donation
One-time Donation


17. Beamforming & direction d’arrivée¶
Ce chapitre aborde les concepts de formation de faisceaux ou beamforming, de direction d’arrivée (DOA = Direction Of Arrival) et d’antennes à commande de phase. Il compare les différents types et géométries d’antennes et explique l’importance de l’espacement des éléments. Des techniques telles que MVDR/Capon et MUSIC sont présentées et illustrées par des simulations en Python.
Présentation du Beamforming¶
Un réseau d’antennes à commande de phase, également appelé réseau à balayage électronique, est un ensemble d’antennes utilisables en émission ou en réception dans les systèmes de communication et radar. On trouve des réseaux d’antennes à commande de phase sur des systèmes terrestres, aéroportés et satellitaires. Les antennes qui composent un réseau sont généralement appelées “éléments”, et le réseau lui-même est parfois désigné comme un “capteur”. Ces éléments sont le plus souvent des antennes omnidirectionnelles, équidistantes horizontalement ou verticalement.
Le beamforming aussi appelé formation de faisceau est une opération de traitement du signal utilisée avec les réseaux d’antennes pour créer un filtre spatial ; il élimine les signaux provenant de toutes les directions sauf celle(s) souhaitée(s). Le beamforming permet d’améliorer le rapport signal/bruit des signaux utiles, d’annuler les interférences, de modeler les diagrammes de rayonnement, voire de transmettre/recevoir simultanément plusieurs flux de données à la même fréquence. Le beamforming utilise des pondérations (ou coefficients) appliquées à chaque élément du réseau, soit numériquement, soit par un circuit analogique. Nous ajustons les pondérations pour former le ou les faisceaux de l’antenne, d’où le nom de formation de faisceaux ! Nous pouvons orienter ces faisceaux (et les zones d’annulation) extrêmement rapidement, bien plus rapidement que les antennes à cardan mécanique, qui peuvent être considérées comme une alternative aux antennes à commande de phase. Nous aborderons généralement la formation de faisceaux dans le contexte d’une liaison de communication, où le récepteur vise à capter un ou plusieurs signaux avec le meilleur rapport signal/bruit possible. Les antennes jouent également un rôle crucial en radar, où l’objectif est de détecter et de suivre des cibles.

Les techniques beamforming se répartissent en trois catégories : /conventionnelle/, /adaptative/ et /aveugle/. La formation de faisceaux conventionnelle est particulièrement utile lorsque la direction d’arrivée du signal d’intérêt est connue. Le processus consiste alors à pondérer les signaux afin de maximiser le gain de l’antenne dans cette direction. Cette méthode peut être utilisée aussi bien en réception qu’en émission. La formation de faisceaux adaptative, quant à elle, ajuste généralement les pondérations en fonction des données reçues, afin d’optimiser certains critères (par exemple, éliminer un signal interférent, obtenir plusieurs faisceaux principaux, etc.). Du fait de son fonctionnement en boucle fermée et de sa nature adaptative, la formation de faisceaux adaptative est généralement utilisée uniquement en réception. Dans ce cas, les données reçues constituent les “entrées du formateur de faisceaux”, et la formation de faisceaux adaptative ajuste les pondérations en fonction des statistiques de ces données.
La taxonomie suivante vise à catégoriser les différents domaines de la formation de faisceaux et propose des exemples de techniques_:

La direction d’arrivée¶
en traitement numérique du signal (DSP) et en radio logicielle (SDR) désigne le processus utilisant un réseau d’antennes pour détecter et estimer la direction d’arrivée d’un ou plusieurs signaux reçus par ce réseau (contrairement à la formation de faisceaux, qui vise à recevoir un signal en minimisant le bruit et les interférences). Bien que la DOA relève du domaine de la formation de faisceaux, la distinction entre les deux termes peut être source de confusion. Certaines techniques, comme la formation de faisceaux conventionnelle et MVDR, peuvent s’appliquer à la fois à la DOA et à la formation de faisceaux, car la même méthode est utilisée pour la DOA : balayer l’angle d’intérêt et effectuer l’opération de formation de faisceaux à chaque angle, puis rechercher les pics dans le résultat (chaque pic représente un signal, mais on ignore s’il s’agit du signal recherché, d’une interférence ou d’un signal réfléchi par trajets multiples). On peut considérer ces techniques de DOA comme une surcouche à un formateur de faisceaux spécifique. D’autres techniques de formation de faisceaux ne peuvent pas être simplement intégrées à une routine DOA, notamment en raison d’entrées supplémentaires non disponibles dans le contexte du DOA. Il existe également des techniques DOA telles que MUSIC et ESPIRT, spécifiquement dédiées au DOA et qui ne sont pas des techniques de formation de faisceaux. La plupart des techniques de formation de faisceaux supposant la connaissance de l’angle d’arrivée du signal d’intérêt, si la cible ou le réseau d’antennes se déplace, il sera nécessaire d’effectuer un DOA en continu comme étape intermédiaire, même si l’objectif principal est la réception et la démodulation du signal.
Les réseaux d’antennes à commande de phase et la formation de faisceaux/DOA trouvent des applications dans de nombreux domaines, notamment les radars, les nouvelles normes Wi-Fi, les communications millimétriques 5G, les communications par satellite et le brouillage. De manière générale, toute application nécessitant une antenne à gain élevé, ou une antenne à gain élevé à déplacement rapide, est une bonne candidate pour les réseaux d’antennes à commande de phase. Types de réseaux d’antennes
Différents types de réseaux¶
Les réseaux d’antennes à commande de phase se divisent en trois catégories : 1. Analogiques, également appelés réseaux passifs à balayage électronique (PESA) ou réseaux à commande de phase traditionnels, utilisent des déphaseurs analogiques pour orienter le faisceau. À la réception, tous les éléments sont additionnés après déphasage (et éventuellement gain ajustable) et convertis en un canal de signal, puis abaissés en fréquence avant d’être reçus. À l’émission, le processus est inverse : un signal numérique unique est émis par la partie numérique, tandis que des déphaseurs et des étages de gain sont utilisés côté analogique pour produire le signal destiné à chaque antenne. Ces déphaseurs numériques ont une résolution limitée en bits et contrôlent la latence. 2. Numériques, également appelés réseaux actifs à balayage électronique (AESA), où chaque élément possède son propre étage d’entrée RF et où la formation du faisceau est entièrement réalisée numériquement. Cette approche est la plus coûteuse, car les composants RF sont onéreux, mais elle offre une flexibilité et une vitesse bien supérieures aux PESA. Les antennes numériques sont couramment utilisées avec les SDR, bien que le nombre de canaux de réception ou d’émission du SDR limite le nombre d’éléments de l’antenne. 3. Hybrides, composés de nombreux sous-réseaux qui, individuellement, ressemblent à des antennes analogiques, chaque sous-réseau possédant son propre étage d’entrée RF, comme pour les antennes numériques. Ils constituent l’approche la plus courante pour les antennes à commande de phase modernes. Elles offrent en effet le meilleur des deux mondes.Il convient de noter que les termes PESA et AESA sont principalement utilisés dans le contexte des radars, et leur définition exacte reste parfois ambiguë. Par conséquent, l’utilisation des termes « antenne analogique/numérique/hybride » est plus claire et applicable à tout type d’application.
Un exemple concret pour chaque type est présenté ci-dessous :

En plus de ces trois types, il faut également considérer la géométrie d’un réseau. La géométrie la plus simple est le réseau linéaire uniforme (ULA = Uniform Linear Array), où les antennes sont alignées et équidistantes (c’est-à-dire disposées selon une seule dimension). Les ULA souffrent d’une ambiguïté de 180 degrés, que nous aborderons plus loin. Une solution consiste à disposer les antennes en cercle : on parle alors de réseau circulaire uniforme (Uniform Circular Array). Enfin, pour les faisceaux 2D, on utilise généralement un réseau rectangulaire uniforme (URA = Uniform Rectangular Array), où les antennes sont disposées en grille. Dans ce chapitre, nous nous concentrons sur les réseaux numériques, car ils sont plus adaptés à la simulation et au traitement numérique du signal (DSP), mais les concepts s’appliquent également aux réseaux analogiques et hybrides. Le chapitre suivant sera consacré à la manipulation du SDR « Phaser » d’Analog Devices, qui intègre un réseau analogique de 8 éléments fonctionnant à 10 GHz, avec des déphaseurs et des convertisseurs de gain, connecté à un Pluto et un Raspberry Pi. Nous nous concentrerons également sur la géométrie ULA car elle offre les mathématiques et le code les plus simples, mais tous les concepts s’appliquent à d’autres géométries, et à la fin du chapitre, nous aborderons la géométrie UCA.
Exigences relatives aux SDR¶
Les antennes réseau à commande de phase analogiques utilisent un déphaseur (et souvent un étage de gain ajustable) par canal/élément, implémenté dans des circuits RF analogiques. Cela signifie qu’une antenne réseau à commande de phase analogique est un composant matériel dédié qui doit être utilisé avec un SDR, ou conçu spécifiquement pour une application particulière. En revanche, tout SDR comportant plusieurs canaux peut être utilisé comme une antenne réseau numérique sans matériel supplémentaire, à condition que les canaux soient cohérents en phase et échantillonnés sur la même horloge, ce qui est généralement le cas pour les SDR disposant de plusieurs canaux de réception intégrés. De nombreuses SDR possèdent deux canaux de réception, comme l’Ettus USRP B210 et l’Analog Devices Pluto (le deuxième canal est accessible via un connecteur uFL sur la carte). Malheureusement, l’utilisation de plus de deux canaux implique de passer à la catégorie des SDR à plus de 10 000 € (prix constaté en 2024), comme l’Ettus USRP N310 ou l’Analog Devices QuadMXFE (16 canaux). Le principal défi réside dans l’impossibilité, pour les SDR économiques, de les chaîner afin d’augmenter le nombre de canaux. Font exception les KerberosSDR (4 canaux) et KrakenSDR (5 canaux), qui utilisent plusieurs SDR RTL partageant un oscillateur local pour former un réseau numérique économique. Leur principal inconvénient est la fréquence d’échantillonnage très limitée (jusqu’à 2,56 MHz) et la plage de fréquences très restreinte (jusqu’à 1766 MHz). La carte KrakenSDR et un exemple de configuration d’antenne sont présentés ci-dessous.

Dans ce chapitre, nous n’utilisons aucun SDR spécifique ; nous simulons plutôt la réception des signaux à l’aide de Python, puis nous passons en revue le DSP utilisé pour effectuer la formation de faisceaux/DOA pour les réseaux numériques.
Introduction aux calculs matriciels en Python/Numpy¶
Python présente de nombreux avantages par rapport à MATLAB : il est gratuit et open source, offre une grande diversité d’applications, une communauté dynamique, les indices commencent à 0 comme dans tous les langages, il est utilisé en IA/ML et il existe une bibliothèque pour presque tout. Cependant, son point faible réside dans la manière dont la manipulation des matrices est codée/représentée (en termes de performances, c’est très rapide, grâce à des fonctions implémentées efficacement en C/C++). Le fait qu’il existe plusieurs façons de représenter les matrices en Python, la méthode np.matrix étant obsolète et remplacée par np.ndarray, n’arrange rien. Dans cette section, nous proposons une brève introduction aux calculs matriciels en Python avec NumPy, afin que vous soyez plus à l’aise avec les exemples DOA.
Commençons par aborder l’aspect le plus complexe des calculs
matriciels avec NumPy ; Les vecteurs sont traités comme des tableaux unidimensionnels (1D), il est donc impossible de distinguer un vecteur ligne d’un vecteur colonne (par défaut, il sera traité comme un vecteur ligne). En revanche, en MATLAB, un vecteur est un objet bidimensionnel (2D). En Python, vous pouvez créer un nouveau vecteur
avec a = np.array([2,3,4,5]) ou convertir une liste en vecteur avec mylist = [2, 3, 4, 5] puis a = np.asarray(mylist). Cependant, dès que vous effectuez des calculs matriciels, l’orientation est importante et les vecteurs seront interprétés comme des vecteurs lignes. Transposer ce vecteur, par exemple avec a.T, ne le transformera pas en vecteur colonne !
Pour convertir un vecteur a en vecteur colonne, utilisez a = a.reshape(-1,1). Le paramètre -1 indique à NumPy de calculer automatiquement la taille de cette dimension, tout en conservant la longueur de la seconde dimension égale à 1. Techniquement, cela crée un tableau 2D, mais comme la seconde dimension est de longueur 1, il s’agit essentiellement d’un tableau 1D d’un point de vue mathématique. Cela ne représente qu’une ligne supplémentaire, mais peut considérablement perturber le flux de code lors de calculs matriciels.
Voici un exemple rapide de calcul matriciel en Python : multiplions une matrice 3x10 par une matrice 10x1. Rappelons que 10x1 signifie 10 lignes et 1 colonne, soit un vecteur colonne puisqu’il ne contient qu’une seule colonne. Depuis nos premières années d’école, nous savons que cette multiplication matricielle est valide car les dimensions internes correspondent et la matrice résultante a la même taille que les dimensions externes, soit 3x1. Par commodité, nous utiliserons np.random.randn() pour créer le tableau 3x10 et np.arange() pour créer le tableau 10x1 :
A = np.random.randn(3,10) # 3x10
B = np.arange(10) # Tableau 1D de longueur 10
B = B.reshape(-1,1) # 10x1
C = A @ B # Multiplication matricielle
print(C.shape) # 3x1
C = C.squeeze() # voir la sous-section suivante
print(C.shape) # Tableau 1D de longueur 3, plus pratique pour les
graphiques et autres opérations Python non-matricielles
Après avoir effectué des calculs matriciels, votre résultat pourrait
ressembler à ceci : [[ 0. 0.125 0.251 -0.376 -0.251 ...]]. Ce tableau ne contient qu’une seule dimension de données, mais si vous tentez de le représenter graphiquement, vous obtiendrez soit une erreur, soit un graphique incohérent. Le résultat ne s’affiche pas. En effet, il s’agit techniquement d’un tableau 2D, qu’il faut convertir en tableau 1D à l’aide de a.squeeze(). Cette fonction supprime les dimensions de longueur 1 et s’avère très utile pour les calculs matriciels en Python. Dans l’exemple ci-dessus, le résultat serait : [ 0. 0.125 0.251 -0.376 -0.251 ...] (notez l’absence des deuxièmes parenthèses). Ce tableau peut être tracé ou utilisé dans d’autres portions de code Python qui attendent des données 1D.
Lors de la programmation de calculs matriciels, la meilleure vérification consiste à afficher les dimensions (avec A.shape) pour s’assurer qu’elles correspondent à vos attentes. Pensez à ajouter la forme du tableau en commentaire après chaque ligne pour vous y référer ultérieurement ; cela facilitera la vérification des dimensions lors de multiplications matricielles ou élément par élément.
Voici quelques opérations courantes en MATLAB et en Python, sous forme de pense-bête :
Vecteur de direction¶
Pour passer à la partie intéressante, il nous faut aborder quelques notions mathématiques. La section suivante est rédigée de manière à ce que les calculs restent relativement simples et soient accompagnés de schémas. Seules les propriétés trigonométriques et exponentielles les plus élémentaires sont utilisées. Il est important de comprendre les bases mathématiques qui sous-tendent les opérations que nous effectuerons en Python pour calculer la direction d’arrivée (DOA).
Considérons un réseau unidimensionnel à trois éléments uniformément espacés :

Dans cet exemple, un signal arrive par la droite et atteint donc d’abord l’élément le plus à droite. Calculons le délai entre le moment où le signal atteint ce premier élément et celui où il atteint le suivant. Pour ce faire, nous pouvons formuler le problème trigonométrique suivant. Essayez de visualiser comment ce triangle a été formé à partir du schéma ci-dessus. Le segment en rouge représente la distance que le signal doit parcourir après avoir atteint le premier élément avant d’atteindre le suivant.

Si vous vous souvenez de SOH CAH TOA, dans ce cas, nous nous intéressons au côté “adjacent” et nous connaissons la longueur de l’hypoténuse (\(d\)). Nous devons donc utiliser le cosinus :
Nous devons isoler le côté adjacent, car c’est ce qui nous indiquera la distance que le signal doit parcourir entre l’impact sur le premier et le deuxième élément. On obtient donc : \(= d \cos(90 - \theta)\). Une identité trigonométrique nous permet ensuite de convertir cette expression en : \(= d \sin(\theta)\). Il s’agit cependant d’une distance ; nous devons la convertir en temps, en utilisant la vitesse de la lumière : \(= d \sin(\theta) / c\) secondes. Cette équation s’applique entre tous les éléments adjacents de notre tableau. Cependant, pour calculer la distance entre des éléments non adjacents, puisqu’ils sont uniformément espacés, on peut multiplier l’ensemble par un entier (nous le verrons plus tard).
Appliquons maintenant ces notions de trigonométrie et de vitesse de la lumière au traitement du signal. Notons notre signal d’émission en bande de base : \(x(t)\) ; il est émis à une fréquence porteuse : \(f_c\) ; le signal d’émission est donc : \(x(t) e^{2j \pi f_c t}\). Nous utiliserons : \(d_m\) pour désigner l’espacement des antennes en mètres. Supposons que ce signal atteigne le premier élément à l’instant : t = 0 ; il atteindra donc l’élément suivant après : \(d_m \sin(\theta) / c\) secondes, comme calculé précédemment. Cela signifie que le deuxième élément reçoit :
Rappelons que lorsqu’il y a un décalage temporel, celui-ci est soustrait de l’argument temporel.
Lorsque le récepteur ou le SDR effectue la conversion de fréquence pour recevoir le signal, il le multiplie essentiellement par la porteuse, mais en sens inverse. Après la conversion, le récepteur voit donc :
On peut maintenant utiliser une petite astuce pour simplifier encore davantage cette expression ; Considérons comment, lors de l’échantillonnage d’un signal, on peut modéliser le processus en remplaçant \(t\) par \(nT\), où \(T\) est la période d’échantillonnage et \(n\) prend simplement les valeurs 0, 1, 2, 3… En substituant ces valeurs, on obtient : \(x(nT - Δt) e^{-2j π f_c Δt}\). Or, \(nT\) est tellement supérieur à Δt que l’on peut négliger le premier terme \(Δt\) et obtenir : \(x(nT) e^{-2j π f_c Δt}\). Si la fréquence d’échantillonnage devient un jour suffisamment rapide pour approcher la vitesse de la lumière sur une distance infime, on pourra réexaminer ce point. Mais n’oublions pas que notre fréquence d’échantillonnage doit seulement être légèrement supérieure à la bande passante du signal d’intérêt.
Continuons avec ces calculs, mais nous allons commencer à représenter les termes de manière discrète afin de mieux les rapprocher de notre code Python. La dernière équation peut être représentée comme suit ; remplaçons \(\Delta t\) :
Nous avons presque terminé, mais heureusement, il nous reste une simplification à effectuer. Rappelons la relation entre la fréquence centrale et la longueur d’onde : \(\lambda = \frac{c}{f_c}\), ou inversement, \(f_c = \frac{c}{\lambda}\). En remplaçant ces valeurs, on obtient :
En formation de faisceaux et en orientation de la direction d’arrivée (DOA), on préfère représenter la distance entre éléments adjacents, \(d\), comme une fraction de longueur d’onde (plutôt qu’en mètres). La valeur la plus courante de \(d\) lors de la conception d’un réseau d’antennes est la moitié de la longueur d’onde. Quelle que soit la valeur de \(d\), nous la représenterons désormais comme une fraction de longueur d’onde plutôt qu’en mètres, ce qui simplifie les équations et le code. Autrement dit, \(d\) (sans l’indice \(m\)) représente la distance normalisée et est égal à \(d = d_m / \lambda\). Cela signifie que nous pouvons simplifier l’équation ci-dessus comme suit :
Cette équation est spécifique aux éléments adjacents. Pour le signal reçu par le k-ième élément, il suffit de multiplier d par k :
Considérons maintenant la convention de coordonnées que nous souhaitons utiliser. Dans cet ouvrage, 0 degré représentera la tangente à la matrice (c’est-à-dire la ligne sur laquelle se trouvent les éléments), comme illustré dans le schéma ci-dessus, et θ augmentera dans le sens horaire. L’élément de référence sera l’élément le plus à gauche, et chaque élément suivant sera situé à une distance d_m vers la droite. Ceci est l’inverse de notre diagramme précédent, nous devons donc inverser le sens du déphasage, c’est-à-dire supprimer le signe négatif :
Nous pouvons représenter cela sous forme matricielle en réarrangeant simplement l’équation ci-dessus pour tous les Nr éléments du tableau, de \(k = 0, 1, ... , N-1\) :
où \(x\) est le vecteur ligne unidimensionnel contenant le signal émis, et le vecteur colonne est ce que l’on appelle le « vecteur de direction » (souvent noté \(s\) et s dans le code). Ce vecteur est représenté par un tableau, par exemple un tableau unidimensionnel pour un réseau d’antennes unidimensionnel. Comme \(e^{0} = 1\), le premier élément du vecteur de direction vaut toujours 1, et les suivants représentent les déphasages relatifs. Au premier élément :
Et voilà ! Ce vecteur est celui que vous rencontrerez dans les articles sur l’optimisation par déplacement d’atomes (DOA) et les implémentations d’automates linéaires universels (ULA) ! Vous pouvez également le rencontrer avec \(2\pi\sin(\theta)\) exprimé sous la forme \(\psi\), auquel cas le vecteur directeur serait simplement \(e^{jd\psi}\), qui est la forme plus générale (nous n’utiliserons cependant pas cette forme). En Python, s s’écrit :
s = [np.exp(2j*np.pi*d*0*np.sin(theta)), np.exp(2j*np.pi*d*1*np.sin(theta)), np.exp(2j*np.pi*d*2*np.sin(theta)), ...] # notez l'augmentation de k
# ou
s = np.exp(2j * np.pi * d * np.arange(Nr) * np.sin(theta)) # où Nr est le nombre d'éléments de l'antenne de réception
Remarquez que l’élément 0 donne 1+0j (car \(e^{0}=1\)) ; cela est logique car tout ce qui précède était relatif à ce premier élément, qui reçoit donc le signal tel quel, sans déphasage relatif. C’est ainsi que fonctionnent les calculs ; en réalité, n’importe quel élément pourrait servir de référence, mais comme vous le verrez plus loin dans notre code, ce qui importe, c’est la différence de phase/amplitude reçue entre les éléments. Tout est relatif.
N’oubliez pas que notre \(d\) est exprimé en longueurs d’onde, et non en mètres !
Réception d’un signal¶
Utilisons le concept de vecteur de direction pour simuler un signal arrivant sur un réseau d’antennes. Pour le signal d’émission, nous utiliserons simplement une tonalité pour l’instant :
import numpy as np
import matplotlib.pyplot as plt
sample_rate = 1e6
N = 10000 # nombre d'échantillons à simuler
# Creation d'une tonalité qui servira de signal émetteur
t = np.arange(N)/sample_rate # vecteur temps
f_tone = 0.02e6
tx = np.exp(2j * np.pi * f_tone * t)
Simulons maintenant un réseau de trois antennes omnidirectionnelles
alignées, séparées par une demi-longueur d’onde (ou « espacement d’une
demi-longueur d’onde »). Nous simulerons le signal de l’émetteur
arrivant sur ce réseau sous un angle donné, θ. La compréhension du
vecteur de direction s (voir le code ci-dessous) justifie tous les
calculs précédents.
d = 0.5 # espacement d'une demi-longueur d'onde
Nr = 3
theta_degrees = 20 # direction d'arrivée (N'hésitez pas à modifier cela, c'est arbitraire.)
theta = theta_degrees / 180 * np.pi # convertion en radians
s = np.exp(2j * np.pi * d * np.arange(Nr) * np.sin(theta)) # Vecteur
de direction
print(s) # Notez qu'il comporte 3 éléments, qu'il est complexe et que le premier élément est 1+0j1+0j
Pour appliquer le vecteur directeur, nous devons effectuer une multiplication matricielle de s et tx. Commençons donc par convertir les deux en 2D, en utilisant la méthode vue précédemment lors de notre révision des calculs matriciels en Python. Nous allons d’abord les transformer en vecteurs lignes à l’aide de ourarray.reshape(-1,1). Nous effectuons ensuite la multiplication matricielle, indiquée par le symbole @. Nous devons également convertir tx d’un vecteur ligne en un vecteur colonne en utilisant
une transposition (imaginez une rotation de 90 degrés) afin que les dimensions internes de la multiplication matricielle correspondent.
s = s.reshape(-1,1) # modifie s en vecteur colonne
print(s.shape) # 3x1
tx = tx.reshape(1,-1) # modifie tx en vecteur ligne
print(tx.shape) # 1x10000
X = s @ tx # Simuler le signal reçu X par multiplication matricielle
print(X.shape) # 3x10000. X sera désormais un tableau 2D, 1D représentant le temps et 1D la dimension spatiale.
À ce stade, X est un tableau 2D de taille 3 x 10 000, car nous avons trois éléments et 10 000 échantillons simulés. Nous utilisons la majuscule X pour indiquer qu’il s’agit de la combinaison (empilement) de plusieurs signaux reçus. Nous pouvons extraire chaque signal individuellement et tracer les 200 premiers échantillons ; ci-dessous, nous ne représenterons que la partie réelle, mais il existe également une partie imaginaire, comme pour tout signal en bande de base. Un aspect fastidieux du calcul matriciel en Python est la nécessité d’utiliser la fonction .squeeze(), qui supprime toutes les dimensions de longueur 1, pour obtenir un tableau NumPy 1D standard, compatible avec les tracés et autres opérations.
plt.plot(np.asarray(X[0,:]).squeeze().real[0:200]) # l' asarray et le
squeeze ne sont que des désagréments que nous devons subit car l'on
provient d'une matrice
plt.plot(np.asarray(X[1,:]).squeeze().real[0:200])
plt.plot(np.asarray(X[2,:]).squeeze().real[0:200])
plt.show()

Observez les déphasages entre les éléments, comme prévu (sauf si le signal arrive dans l’axe de visée, auquel cas il atteindra tous les éléments simultanément et il n’y aura pas de déphasage ; fixez θ à 0 pour le constater). Essayez de modifier l’angle et observez le résultat.
Enfin, ajoutons du bruit à ce signal reçu, car tout signal que nous traiterons comporte un certain niveau de bruit. Nous souhaitons appliquer le bruit après l’application du vecteur de direction, car chaque élément subit un signal de bruit indépendant (cela est possible car un signal AWGN (Arbitrary White Gaussion Noise = Bruit blanc gaussien arbitraire) avec déphasage reste un signal AWGN).

Formation conventionnelle de faisceaux (conventionnal beamforming) et direction d’arrivée (DOA)¶
Nous allons maintenant traiter ces échantillons X, en supposant que nous ignorons l’angle d’arrivée, et effectuer le calcul de la direction d’arrivée (DOA). Cette opération consiste à estimer le ou les angles d’arrivée à l’aide d’un traitement numérique du signal (DSP) et d’un peu de code Python. Comme évoqué précédemment dans ce chapitre, la formation de faisceaux et le calcul du DOA sont très similaires et reposent souvent sur les mêmes techniques. Dans la suite de ce chapitre, nous étudierons différents formateurs de faisceaux. Pour chacun d’eux, nous commencerons par le code mathématique qui calcule les pondérations, \(w\). Ces pondérations peuvent être appliquées au signal entrant X grâce à la simple équation suivante : \(w^H X\), ou, en Python, à w.conj().T @ X. Dans l’exemple ci-dessus, X est une matrice 3x10000, mais après application des pondérations, il ne reste qu’une matrice 1x10000, comme si notre récepteur ne possédait qu’une seule antenne. Nous pouvons alors utiliser un DSP RF classique pour traiter le signal. Une fois le formateur de faisceaux développé, nous l’appliquerons au problème du DOA.
Nous allons commencer par l’approche de formation de faisceau « classique », également appelée formation de faisceau par sommation et retard. Notre vecteur de pondération w doit être un tableau unidimensionnel pour un réseau linéaire uniforme ; dans notre exemple à trois éléments, w est un tableau 3x1 de pondérations complexes. Avec la formation de faisceau classique, nous laissons l’amplitude des pondérations à 1 et ajustons les phases afin que le signal s’additionne de manière constructive dans la direction du signal souhaité, que nous appellerons : \(\theta\). Il s’avère que c’est exactement le même calcul que celui effectué précédemment : nos pondérations constituent notre vecteur de direction !
ou en Python:
w = np.exp(2j * np.pi * d * np.arange(Nr) * np.sin(theta)) # Formation de faisceaux conventionnelle ou à sommation et delai
X_weighted = w.conj().T @ X # Exemple d'application des pondérations au signal reçu (formation de faisceau)
print(X_weighted.shape) # 1x10000
où Nr est le nombre d’éléments de notre réseau linéaire uniforme avec un espacement de d fractions de longueur d’onde (généralement ~0,5). Comme vous pouvez le constater, les pondérations ne dépendent que de la géométrie du réseau et de l’angle d’intérêt. Si notre réseau nécessitait un étalonnage de phase, nous inclurions également les valeurs d’étalonnage correspondantes. L’équation de w vous a peut-être permis de remarquer que les pondérations sont complexes et que leurs magnitudes sont toutes égales à un.
Mais comment déterminer l’angle d’intérêt theta ? Il faut commencer par effectuer une analyse de la direction d’arrivée (DOA), qui consiste à balayer (échantillonner) toutes les directions d’arrivée de -π à +π (-180° à +180°), par exemple par incréments de 1°. Pour chaque direction, nous calculons les pondérations à l’aide d’un formateur de faisceau ; nous commencerons par utiliser le formateur de faisceau conventionnel. L’application des pondérations à notre signal X nous donne un tableau unidimensionnel d’échantillons, comme si nous l’avions reçu avec une antenne directionnelle. Nous pouvons ensuite calculer la puissance du signal en calculant sa variance avec np.var(), et répéter l’opération pour chaque angle de balayage. Nous visualiserons les résultats graphiquement, mais la plupart des logiciels de traitement numérique du signal RF déterminent l’angle de puissance maximale (grâce à un algorithme de détection de pics) et l’appellent l’estimation de la direction d’arrivée (DOA).
theta_scan = np.linspace(-1*np.pi, np.pi, 1000) # 1000 thetas
différents compris entre -180 et +180 degrés
results = []
for theta_i in theta_scan:
w = np.exp(2j * np.pi * d * np.arange(Nr) * np.sin(theta_i)) #
Conventionnel, c'est à dire délai et addition, beamformer
X_weighted = w.conj().T @ X # application des poids. rappelez-vous X est 3x10000
results.append(10*np.log10(np.var(X_weighted))) # puissance du signal, en dB ainsi c'est plus facile d'observer les lobes petits et grands en même temps
results -= np.max(results) # normalize (optional)
# affichage de l'angle qui nous donne la valeur maximale
print(theta_scan[np.argmax(results)] * 180 / np.pi) # 19.99999999999998
plt.plot(theta_scan*180/np.pi, results) # affichons l'angle en degrés
plt.xlabel("Theta [Degrees]")
plt.ylabel("DOA Metric")
plt.grid()
plt.show()

Nous avons trouvé notre signal ! Vous commencez sans doute à comprendre le principe du réseau à balayage électrique. Essayez d’augmenter le niveau de bruit pour pousser le système à ses limites ; il vous faudra peut-être simuler la réception d’un plus grand nombre d’échantillons pour les faibles rapports signal/bruit. Essayez également de modifier la direction d’arrivée.
Si vous préférez visualiser les résultats de la direction d’arrivée sur un diagramme polaire, utilisez le code suivant :
fig, ax = plt.subplots(subplot_kw={'projection': 'polar'})
ax.plot(theta_scan, results) # SOYEZ SURE D'UTILISEZTO USE RADIAN FOR POLAR
ax.set_theta_zero_location('N') # Orienter le point 0 degré vers le haut
ax.set_theta_direction(-1) # Augmenter theta dans le sens horaire
ax.set_rlabel_position(55) # Déplacement des étiquettes de la grille
loin des autres étiquettes.
plt.show()

Nous observerons régulièrement ce phénomène de boucle angulaire, nécessitant une méthode de calcul des pondérations de formation de faisceau, puis leur application au signal reçu. Dans la méthode de formation de faisceau suivante (MVDR), nous utiliserons notre signal reçu X dans le calcul des pondérations, ce qui en fera une technique adaptative. Mais auparavant, nous examinerons certains phénomènes intéressants liés aux réseaux d’antennes à commande de phase, notamment l’origine de ce second pic à 160 degrés.
Examinons l’origine de ce second pic à 160 degrés ; la DOA simulée était de 20 degrés, mais le fait que 180 - 20 = 160 n’est pas fortuit. Imaginez trois antennes omnidirectionnelles alignées sur une table. L’axe de visée du réseau est perpendiculaire à celui-ci, comme indiqué sur le premier schéma de ce chapitre. Imaginons maintenant l’émetteur placé devant les antennes, également sur la (très grande) table, de sorte que son signal arrive avec un angle de +20 degrés par rapport à l’axe de visée. Le réseau subit le même effet, que le signal arrive par l’avant ou par l’arrière : le déphasage est identique, comme illustré ci-dessous avec les éléments du réseau en rouge et les deux directions d’arrivée possibles de l’émetteur en vert. Par conséquent, lors de l’exécution de l’algorithme de détermination de la direction d’arrivée (DOA), une ambiguïté de 180 degrés de ce type apparaîtra toujours. La seule solution consiste à utiliser un réseau 2D, ou un second réseau 1D positionné à un angle différent par rapport au premier. Vous vous demandez peut-être si cela signifie qu’il est plus simple de ne calculer que l’intervalle de -90 à +90 degrés afin d’économiser des cycles de calcul, et vous avez tout à fait raison !

Essayons de faire varier l’angle d’arrivée (AoA) de -90 à +90 degrés au lieu de le maintenir constant à 20 :
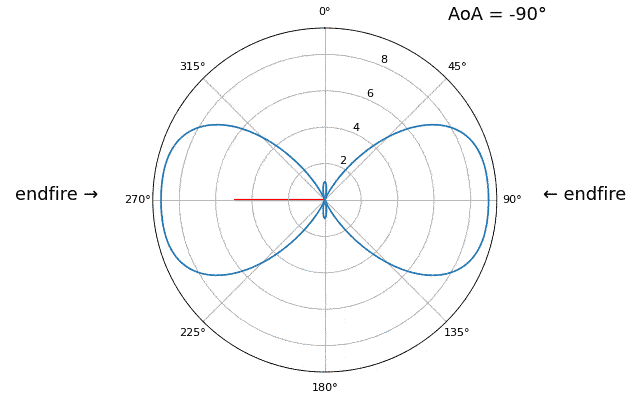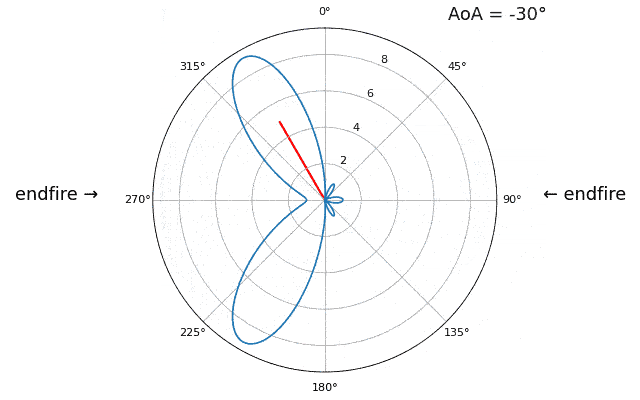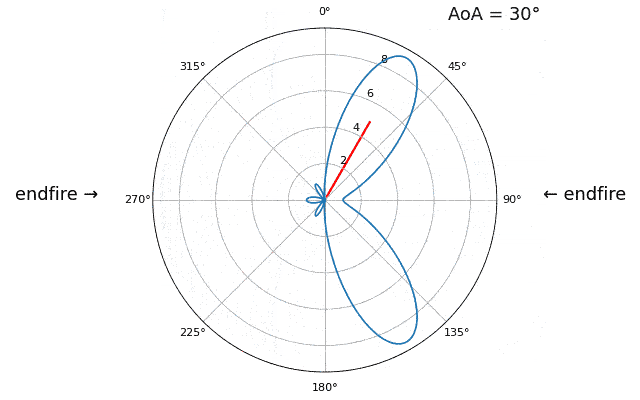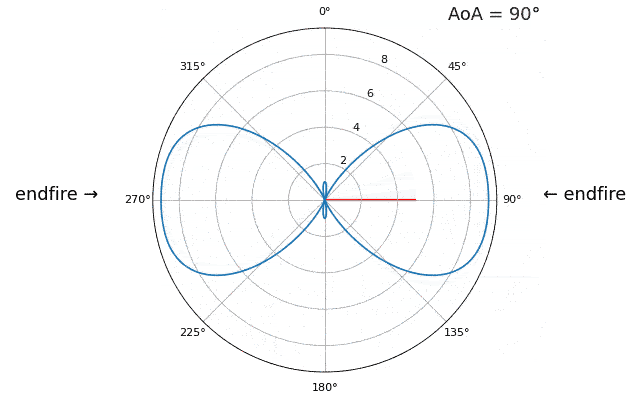
À l’approche de l’axe du réseau (lorsque le signal arrive sur ou près de cet axe), les performances diminuent. On observe deux dégradations principales : 1) le lobe principal s’élargit et 2) une ambiguïté apparaît, empêchant de déterminer si le signal provient de la gauche ou de la droite. Cette ambiguïté s’ajoute à l’ambiguïté à 180° évoquée précédemment, où un lobe supplémentaire apparaît à 180° - θ, ce qui peut entraîner, pour certains angles d’arrivée, la présence de trois lobes de taille sensiblement égale. Cette ambiguïté liée à l’axe du réseau est toutefois logique : les déphasages entre les éléments sont identiques, que le signal arrive de la gauche ou de la droite par rapport à l’axe du réseau. Tout comme pour l’ambiguïté à 180°, la solution consiste à utiliser un réseau 2D ou deux réseaux 1D positionnés à des angles différents. En général, la formation de faisceau est optimale lorsque l’angle est proche de l’axe de visée.
À partir de maintenant, nous n’afficherons que les degrés -90 à +90 dans nos graphiques polaires, car le motif sera toujours symétrique par rapport à l’axe du réseau, du moins pour les réseaux linéaires 1D (qui sont tous ceux que nous abordons dans ce chapitre).
Les graphiques présentés jusqu’à présent correspondent aux résultats de la direction d’arrivée (DOA) ; ils représentent la puissance reçue à chaque angle après application du formateur de faisceau. Ils étaient spécifiques à un scénario où les émetteurs arrivaient de certains angles. Mais nous pouvons également observer le diagramme de rayonnement lui-même, avant toute réception de signal. On parle alors de « diagramme de rayonnement au repos » ou de « réponse du réseau ».
Rappelons que notre vecteur de pointage, que nous voyons régulièrement,
np.exp(2j * np.pi * d * np.arange(Nr) * np.sin(theta))
encapsule la géométrie du réseau linéaire uniforme (ULA), et son seul autre paramètre est la direction de pointage souhaitée. Nous pouvons calculer et tracer le diagramme de rayonnement au repos (réponse du réseau) lorsqu’il est pointé dans une direction donnée, ce qui nous indiquera la réponse naturelle du réseau si nous n’effectuons aucun formage de faisceau supplémentaire. Ceci peut être réalisé en effectuant la FFT des poids complexes conjugués ; aucune boucle n’est nécessaire ! La difficulté réside dans le remplissage pour augmenter la résolution et dans la conversion des intervalles de la sortie FFT en angles en radians ou en degrés, ce qui implique un arcsinus comme vous pouvez le voir dans l’exemple complet ci-dessous :
Nr = 3
d = 0.5
N_fft = 512
theta_degrees = 20 # il n'y a pas de SOI (Signal d'Intérêt), nous ne traitons pas d'échantillons, il s'agit simplement de la direction vers laquelle nous voulons pointer
theta = theta_degrees / 180 * np.pi
w = np.exp(2j * np.pi * d * np.arange(Nr) * np.sin(theta)) # beamformer classique
w_padded = np.concatenate((w, np.zeros(N_fft - Nr))) # zero padding à N_fft élements pour obtenir une meilleure résolution dans la FFT
w_fft_dB = 10*np.log10(np.abs(np.fft.fftshift(np.fft.fft(w_padded)))**2) # amplitude de la FFT en dB
w_fft_dB -= np.max(w_fft_dB) # normalisation à 0 dB au niveau du pic
# Mapper les bins de la FFT aux angles en radians
theta_bins = np.arcsin(np.linspace(-1, 1, N_fft)) # in radians
# trouver la valeur maximale afin de l'ajouter au graphique
theta_max = theta_bins[np.argmax(w_fft_dB)]
fig, ax = plt.subplots(subplot_kw={'projection': 'polar'})
ax.plot(theta_bins, w_fft_dB) # ASSUREZ-VOUS D'UTILISER LE RADIAN POUR LES POINTS POLAIRES
ax.plot([theta_max], [np.max(w_fft_dB)],'ro')
ax.text(theta_max - 0.1, np.max(w_fft_dB) - 4, np.round(theta_max * 180 / np.pi))
ax.set_theta_zero_location('N') # Orienter le point 0 degré vers le haut
ax.set_theta_direction(-1) # Augmenter dans le sens horaire
ax.set_rlabel_position(55) # Éloignez les étiquettes de la grille des autres étiquettes.
ax.set_thetamin(-90) # Afficher uniquement la moitié supérieure
ax.set_thetamax(90)
ax.set_ylim([-30, 1]) # Comme il n'y a pas de bruit, on ne baisse que de 30 dB
plt.show()

Notez que tous les poids ont une magnitude unitaire (ils restent sur le cercle unité) et que les éléments de numéro le plus élevé « tournent » plus vite. En observant attentivement, vous remarquerez qu’à 0 degré, ils sont tous alignés ; leur déphasage est alors nul (1+0j).
Pour les plus curieux, il existe des équations permettant d’approximer la largeur du faisceau du lobe principal en fonction du nombre d’éléments, bien qu’elles ne soient précises que pour un grand nombre d’éléments (par exemple, 8 ou plus). La largeur du faisceau à mi-puissance (HPBW) est définie comme la largeur à 3 dB en dessous du pic du lobe principal et est approximativement égale à \(\frac{0,9 \lambda}{N_rd\cos(\theta)}\) [1], ce qui, pour un espacement d’une demi-longueur d’onde, se simplifie à :
La première largeur de faisceau nul (FNBW), la largeur du lobe principal d’un point nul à un autre, est approximativement \(\frac{2\lambda}{N_rd}\) [1], ce qui, pour un espacement d’une demi-longueur d’onde, se simplifie en :
Utilisons le code précédent, mais augmentons Nr à 16 éléments. D’après les équations ci-dessus, la largeur de faisceau à mi-puissance (HPBW) pour un angle de 20 degrés (0,35 radian) devrait être d’environ 0,12 radian, soit 6,8 degrés. La largeur de faisceau au point mort haut (FNBW) devrait être d’environ 0,25 radian, soit 14,3 degrés. Effectuons une simulation pour vérifier la précision des résultats. Pour visualiser les largeurs de faisceau, nous utilisons généralement des graphiques rectangulaires plutôt que polaires. Les résultats sont présentés ci-dessous, la HPBW est indiquée en vert et la FNBW en rouge :

Il est peut-être difficile de le voir sur le graphique, mais en zoomant fortement, on constate que la largeur de bande à mi-puissance (HPBW) est d’environ 6,8 degrés et la largeur de bande à mi-puissance (FNBW) d’environ 15,4 degrés, ce qui est très proche de nos calculs, surtout pour la HPBW !
Jusqu’à présent, nous avons utilisé une distance entre les éléments, d, égale à une demi-longueur d’onde. Par exemple, un réseau conçu pour le Wi-Fi 2,4 GHz avec un espacement de λ/2 aurait un espacement de 3 × 10⁸ / 2,4 × 10⁹ / 2 = 12,5 cm, soit environ 5 pouces. Cela signifie qu’un réseau 4 × 4 éléments aurait des dimensions d’environ 15 pouces × 15 pouces × la hauteur des antennes. Il arrive qu’un réseau ne puisse pas atteindre exactement un espacement de λ/2, par exemple lorsque l’espace est limité ou lorsque le même réseau doit fonctionner sur différentes fréquences porteuses.
Examinons le cas où l’espacement est supérieur à λ/2, c’est-à-dire un espacement excessif, en faisant varier d entre λ/2 et 4λ. Nous supprimerons la moitié inférieure du diagramme polaire puisqu’elle est de toute façon l’image miroir de la partie supérieure.
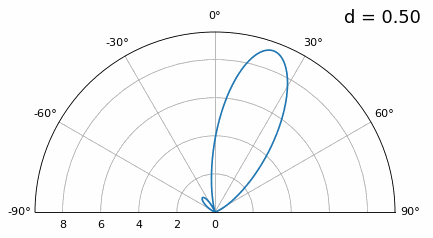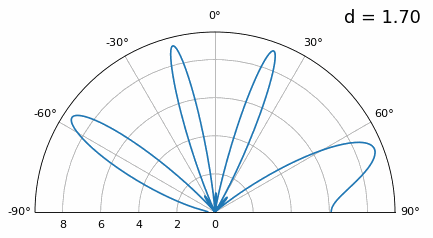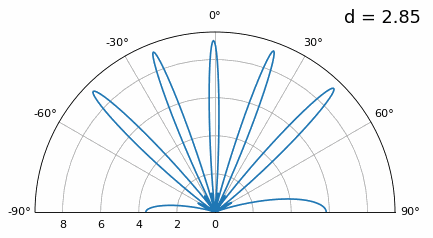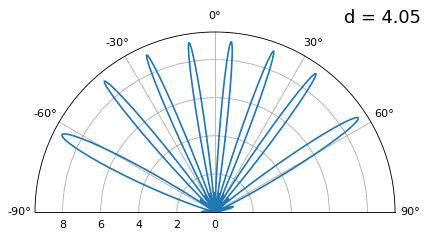
Comme vous pouvez le constater, outre l’ambiguïté à 180 degrés évoquée précédemment, une ambiguïté supplémentaire apparaît, qui s’aggrave lorsque d augmente (apparition de lobes supplémentaires ou incorrects). Ces lobes supplémentaires, appelés lobes de réseau, résultent du repliement de spectre spatial. Comme nous l’avons vu dans le chapitre sur échantillonnage IQ, un échantillonnage insuffisant entraîne un repliement de spectre. Le même phénomène se produit dans le domaine spatial : si les éléments ne sont pas suffisamment espacés par rapport à la fréquence porteuse du signal observé, l’analyse aboutit à des résultats erronés. On peut assimiler l’espacement des antennes à l’espace d’échantillonnage ! Dans cet exemple, les lobes de réseau ne posent pas de problème majeur tant que d > λ, mais ils apparaissent dès que l’espacement dépasse λ/2. En effet, le théorème de Nyquist stipule qu’il faut échantillonner au moins deux fois plus vite que le signal observé, soit deux échantillons par cycle. Nous mesurons notre taux d’échantillonnage spatial en échantillons par mètre, et comme l’équivalent de la fréquence radiane dans l’espace est de 2π/λ radians par mètre, et sachant qu’il y a 2π radians (360 degrés) dans un cycle, nous devons échantillonner l’espace au moins à :
ou en terme de distance entre les éléments, \(d\), ce qui correspond essentiellement à des mètres par échantillon spatial :
Tant que \(d \leq λ/2\), il n’y aura pas de lobes de réseau !
Que se passe-t-il lorsque d est inférieur à λ/2, par exemple lorsqu’il faut intégrer le réseau dans un espace réduit ? On sait qu’il n’y aura pas de lobes de réseau, mais un autre phénomène se produit… Répétons la même simulation en commençant par 0,5λ et en diminuant d.
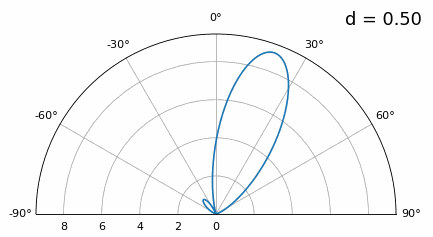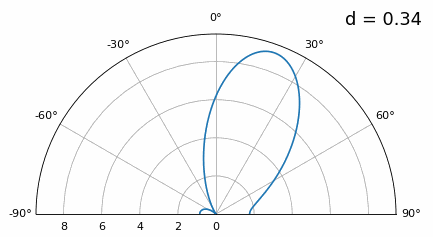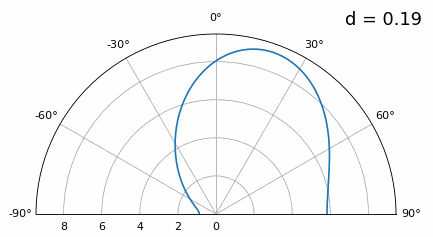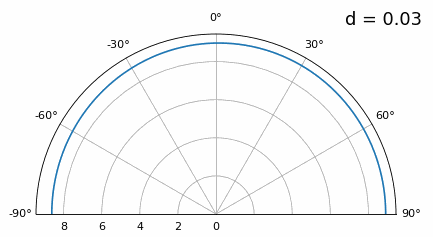
Bien que le lobe principal s’élargisse lorsque d diminue, il présente toujours un maximum à 20 degrés, et il n’y a pas de lobes de réseau. En théorie, cela fonctionnerait donc (du moins à un rapport signal/bruit élevé et si le couplage mutuel ne devient pas un problème majeur). Pour mieux comprendre ce qui se produit lorsque d devient trop petit, répétons l’expérience en ajoutant un signal supplémentaire provenant de -40 degrés :
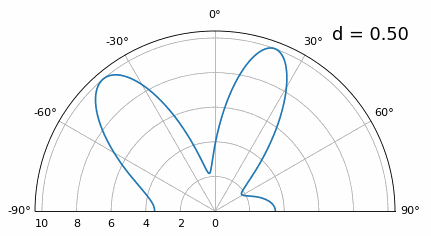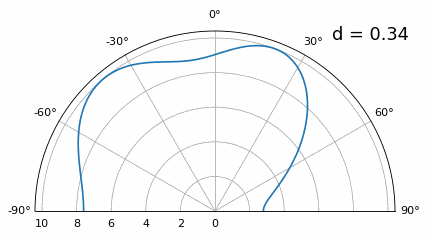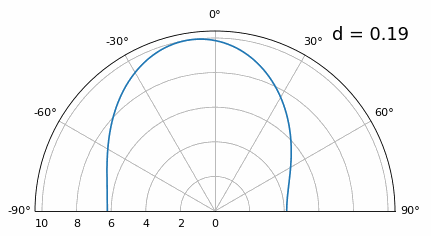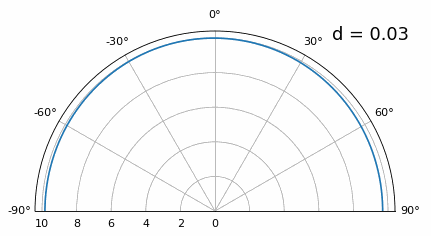
En dessous de λ/4, il n’est plus possible de distinguer les deux trajets, et le réseau d’antennes est fortement dégradé. Comme nous le verrons plus loin dans ce chapitre, il existe des techniques de formation de faisceaux plus précises que les techniques conventionnelles, mais maintenir d aussi proche que possible de λ/2 restera un principe fondamental.
Ajustement spatial¶
L’ajustement spatial est une technique utilisée conjointement avec le formateur de faisceau conventionnel. Elle consiste à ajuster l’amplitude des pondérations pour obtenir des caractéristiques spécifiques. Même si vous n’utilisez pas le formateur de faisceau conventionnel, il est important de comprendre le concept d’ajustement. Rappelons que le calcul des pondérations du formateur de faisceau conventionnel s’effectuait à l’aide d’une série de nombres complexes dont l’amplitude était égale à un. Avec l’ajustement spatial, nous multiplions les pondérations par des scalaires afin de modifier leur amplitude. Voyons ce qui se passe si nous multiplions les pondérations par des valeurs aléatoires comprises entre 0 et 1 :
Nous allons simuler la réception d’un signal dans l’axe de visée (0 degré) avec un rapport signal/bruit élevé afin d’observer le résultat. Notez que ce processus est équivalent et produira les mêmes résultats que la simulation du diagramme de rayonnement d’antenne au repos pour les pondérations données, comme nous l’expliquons à la fin de ce chapitre.
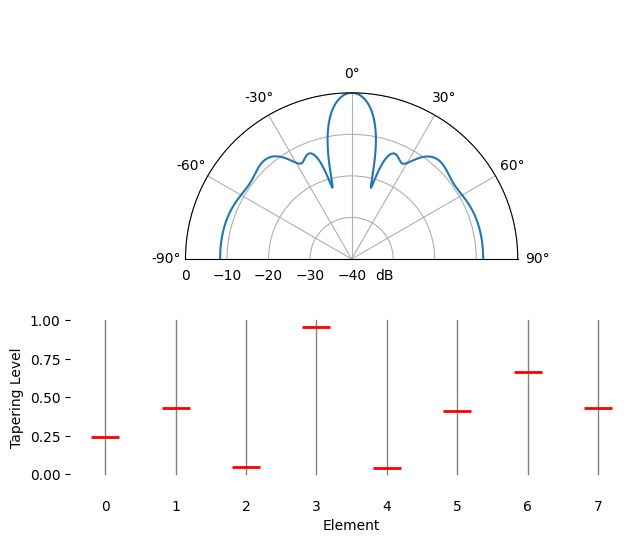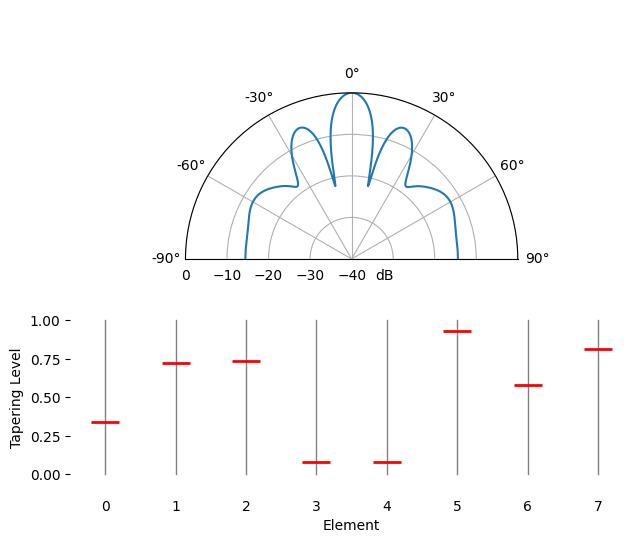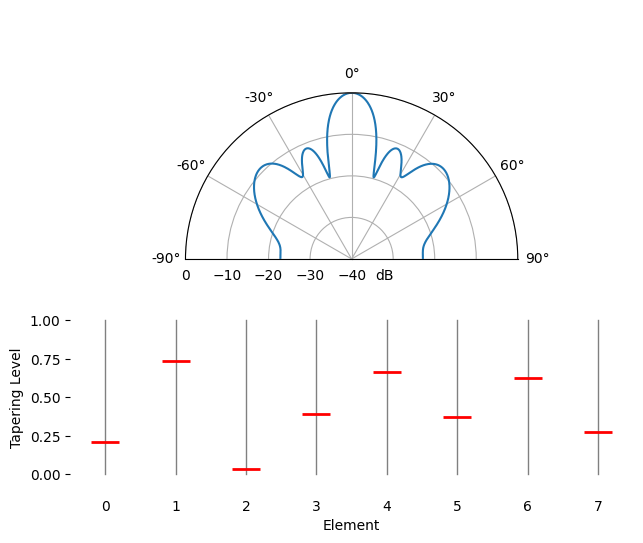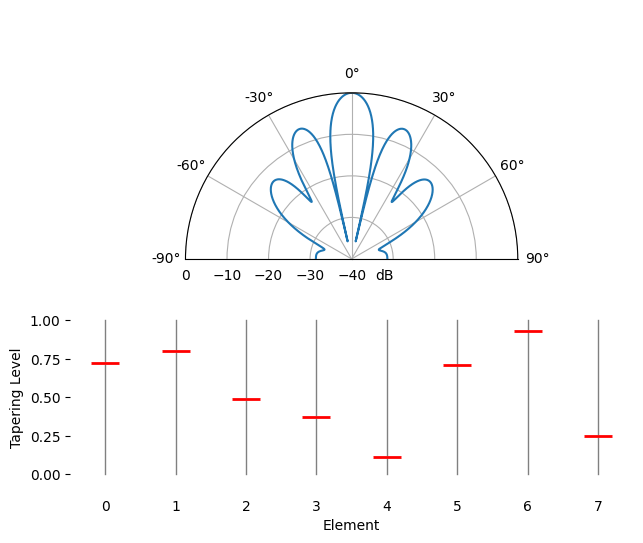
Observez la largeur du lobe principal et la position des zéros.
Il s’avère que l’atténuation permet de réduire les lobes secondaires, ce qui est souvent souhaitable, en diminuant l’amplitude des pondérations aux bords du réseau. Par exemple, une fonction fenêtre de Hamming peut être utilisée comme valeur de pondération, comme suit :
Pour le plaisir, nous allons comparer l’utilisation d’une fenêtre rectangulaire (sans fenêtre) et d’une fenêtre de Hamming comme fonction de pondération :
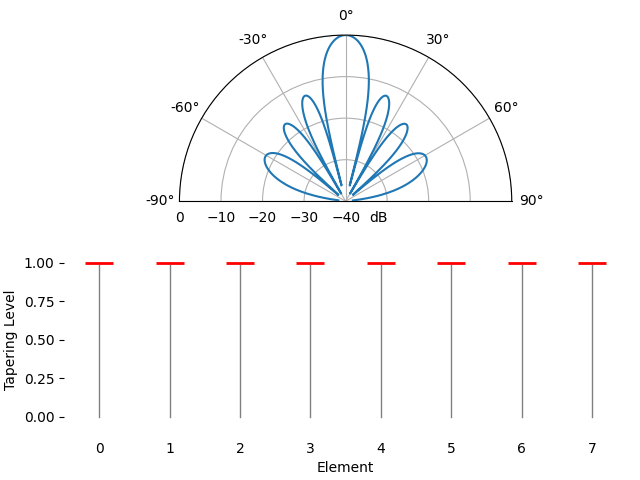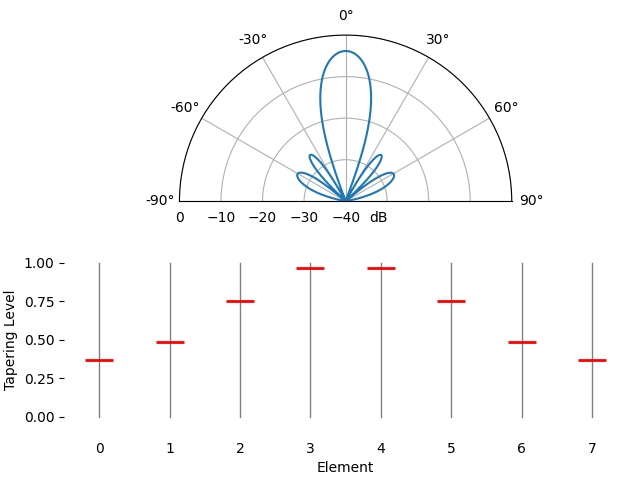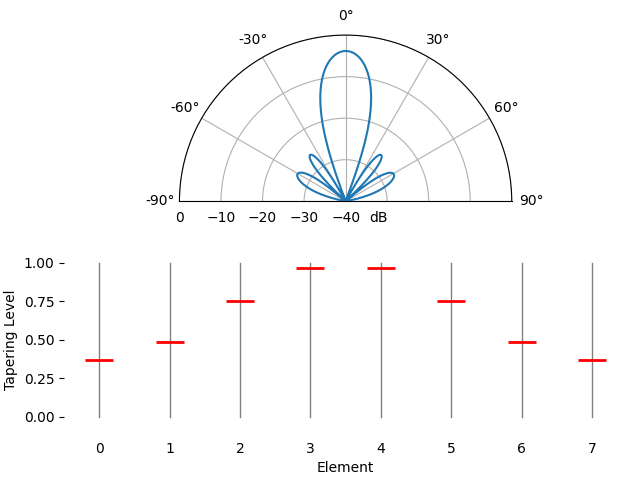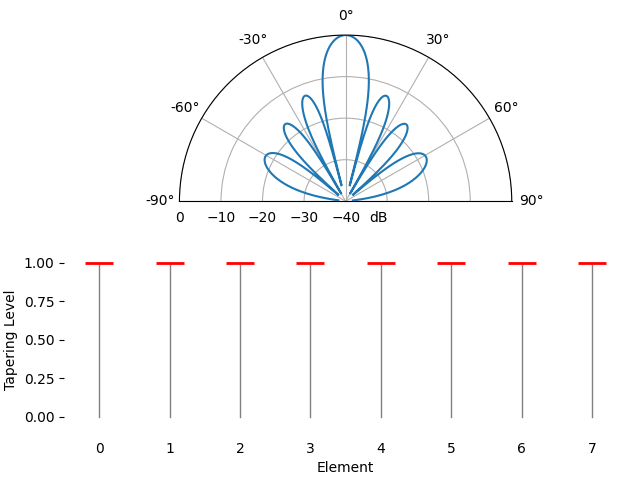
On observe deux différences. Premièrement, la largeur du lobe principal peut être augmentée ou diminuée selon la fonction de pondération utilisée (moins de lobes secondaires entraînent généralement un lobe principal plus large). Une pondération rectangulaire (c’est-à-dire sans pondération) produira le lobe principal le plus étroit, mais les lobes secondaires les plus larges. Deuxièmement, nous constatons que le gain du lobe principal diminue lorsqu’on applique un facteur d’atténuation. Cela s’explique par le fait que l’énergie du signal reçue est moindre, car le gain maximal de tous les éléments n’est pas utilisé. Ce phénomène peut s’avérer très problématique en cas de très faible rapport signal/bruit.
Si vous vous demandez pourquoi on observe autant de lobes secondaires avec une fenêtre rectangulaire (sans facteur d’atténuation), c’est pour la même raison qu’une fenêtre rectangulaire dans le domaine temporel induit une fuite spectrale dans le domaine fréquentiel. La transformée de Fourier d’une fenêtre rectangulaire est une fonction sinus cardinal, \(sin(x)/x\), dont les lobes secondaires tendent vers l’infini. Avec les réseaux d’antennes, l’échantillonnage est effectué dans le domaine spatial, et le diagramme de rayonnement est la transformée de Fourier de cet échantillonnage spatial, pondérée par les facteurs. C’est pourquoi nous avons pu visualiser le diagramme de rayonnement à l’aide d’une FFT plus tôt dans ce chapitre. Rappelons que dans la section consacrée au fenêtrage du chapitre sur le domaine fréquentiel, nous avons comparé la réponse fréquentielle de chaque type de fenêtre :

Modification manuelle des pondérations¶
Le formateur de faisceau classique nous fournit une équation pour calculer les pondérations afin de pointer dans une direction spécifique. Mais imaginons un instant que nous n’ayons aucune méthode de calcul des pondérations et que nous les modifions manuellement (amplitude et phase) pour observer les résultats. Ci-dessous se trouve une petite application écrite en JavaScript qui simule le diagramme de rayonnement d’un réseau à 8 éléments, avec des curseurs pour contrôler le gain et la phase de chaque élément. Vous pouvez essayer d’ajouter un effet de transition ou de simuler moins de 8 éléments en annulant l’amplitude d’un ou plusieurs d’entre eux.
Element Magnitude (Gain) Phase
Formation de faisceaux adaptative¶
Le formateur de faisceaux conventionnel présenté précédemment est une méthode simple et efficace, mais il présente certaines limitations. Par exemple, il est peu performant en présence de plusieurs signaux provenant de directions différentes ou lorsque le niveau de bruit est élevé. Dans ces cas, il est nécessaire d’utiliser des techniques de formation de faisceaux plus avancées, souvent qualifiées de « adaptatives ». Le principe de la formation de faisceaux adaptative est d’utiliser le signal reçu pour calculer les pondérations, au lieu d’utiliser un ensemble fixe de pondérations comme avec le formateur de faisceaux conventionnel. Cela permet au formateur de faisceaux de s’adapter à l’environnement et d’offrir de meilleures performances, car les pondérations sont désormais basées sur les statistiques des données reçues.
Les techniques de formation de faisceaux adaptatives se divisent en deux catégories : les méthodes classiques et les méthodes basées sur les sous-espaces. Les méthodes de sous-espaces telles que MUSIC et ESPRIT sont très puissantes, mais elles nécessitent d’estimer le nombre de signaux présents et requièrent au moins trois éléments pour fonctionner (quatre étant recommandés).
La première technique de formation de faisceaux adaptatifs que nous allons étudier est MVDR, qui tend à être l’algorithme de référence lorsque l’on parle de formation de faisceaux adaptatifs.
Formateur de faisceau MVDR/Capon¶
Nous allons maintenant examiner un formateur de faisceau légèrement plus complexe que la technique conventionnelle de sommation et de retard, mais généralement beaucoup plus performant : le formateur de faisceau à réponse sans distorsion à variance minimale (MVDR), également appelé formateur de faisceau Capon. Rappelons que la variance d’un signal correspond à sa puissance. Le principe du MVDR est de maintenir le signal à l’angle d’intérêt avec un gain fixe de 1 (0 dB), tout en minimisant la variance/puissance totale du signal formé. Si le signal d’intérêt est maintenu fixe, minimiser la puissance totale revient à minimiser autant que possible les interférences et le bruit. On le qualifie souvent de formateur de faisceau « statistiquement optimal ».
Le formateur de faisceau MVDR/Capon peut être résumé par l’équation suivante :
Le vecteur \(s\) est le vecteur de direction correspondant à la direction souhaitée et a été présenté au début de ce chapitre. \(R\) est l’estimation de la matrice de covariance spatiale basée sur nos échantillons reçus, obtenue à l’aide de \(R = np.cov(X)\) ou calculée manuellement en multipliant \(X\) par sa transposée conjuguée complexe, c’est-à-dire \(R = X X^H\). La matrice de covariance spatiale est une matrice de taille \(Nr\) x \(Nr\) (3x3 dans les exemples précédents) qui indique la similarité des échantillons reçus des trois éléments. Bien que cette équation puisse paraître complexe au premier abord, il est utile de savoir que le dénominateur sert principalement à la mise à l’échelle, et que le numérateur, qui correspond à la matrice de covariance inversée multipliée par le vecteur de direction, est l’élément essentiel sur lequel il faut se concentrer. Cela étant dit, il est nécessaire d’inclure le dénominateur ; il agit comme une constante de normalisation afin que, lorsque \(R\) varie au fil du temps, les poids conservent leur amplitude.
Sortie du beamforming - La sortie du beamformer utilisant un vecteur de pondération \(\mathbf{w}\) est donnée par :
Problème d’optimisation - L’objectif est de déterminer les pondérations du beamforming qui minimisent la puissance de sortie tout en assurant une réponse sans distorsion dans la direction souhaitée \(\theta_0\). Formellement, le problème peut être exprimé comme suit :
où :
- \(\mathbf{R} = E[\mathbf{X}\mathbf{X}^H]\) est la matrice de covariance des signaux reçus
- \(\mathbf{s}\) est le vecteur de direction vers la direction du signal souhaité \(\theta_0\)
Méthode Lagrangienne - Introduisons un multiplieur lagrangien \(\lambda\) et construisons le lagrangien :
Résolution de l’optimisation - En dérivant le lagrangien par rapport à \(\mathbf{w^H}\) et en annulant la dérivée, on obtient :
Pour résoudre \(\lambda\), appliquons la contrainte \(\mathbf{w}^H \mathbf{s} = 1\):
Pour effectuer une détermination de la direction d’arrivée (DOA) avec le formateur de faisceaux MVDR, il suffit de répéter le calcul MVDR en balayant tous les angles d’intérêt. Autrement dit, on considère que le signal provient de l’angle \(\theta\), même si ce n’est pas le cas. Pour chaque angle, nous calculons les pondérations MVDR, puis nous les appliquons au signal reçu, et enfin nous calculons la puissance du signal. L’angle qui nous donne la puissance la plus élevée correspond à notre estimation de la direction d’arrivée (DOA). Mieux encore, nous pouvons tracer la puissance en fonction de l’angle pour visualiser le diagramme de rayonnement, comme nous l’avons fait précédemment avec le formateur de faisceau conventionnel. Ainsi, nous n’avons pas besoin de supposer le nombre de signaux présents.
En Python, nous pouvons implémenter le formateur de faisceau MVDR/Capon comme suit, sous forme de fonction pour faciliter son utilisation ultérieure :
# theta est la direction d'intérêt, en radians, et X est notre signal reçu
def w_mvdr(theta, X):
s = np.exp(2j * np.pi * d * np.arange(Nr) * np.sin(theta)) # Vecteur de direction dans la direction souhaitée theta
s = s.reshape(-1,1) # Transformation en vecteur colonne (taille 3x1)
R = (X @ X.conj().T)/X.shape[1] # Calcul de la matrice de covariance. Donne une matrice de covariance Nr x Nr des échantillons
Rinv = np.linalg.pinv(R) # 3x3. La pseudo-inverse est généralement plus performante/rapide qu'une véritable inverse.
w = (Rinv @ s)/(s.conj().T @ Rinv @ s) # Équation MVDR/Capon ! Le numérateur est de dimension 3x3 * 3x1, le dénominateur de dimension 1x3 * 3x3 * 3x1, ce qui donne un vecteur de pondération 3x1.
return w
En utilisant ce formateur de faisceau MVDR dans le contexte de la DOA, on obtient l’exemple Python suivant :
theta_scan = np.linspace(-1*np.pi, np.pi, 1000) # 1000 valeurs de theta différentes entre -180 et +180 degrés
results = []
for theta_i in theta_scan:
w = w_mvdr(theta_i, X) # 3x1
X_weighted = w.conj().T @ X # application des pondérations
power_dB = 10*np.log10(np.var(X_weighted)) # puissance du signal, en dB, pour faciliter la visualisation simultanée des lobes de petite et de grande taille
results.append(power_dB)
results -= np.max(results) # normalisation
Appliquée à l’exemple de simulation DOA précédent, cette méthode donne le résultat suivant :

Cela semble fonctionner correctement, mais pour comparer cette technique à d’autres, il nous faut créer un problème plus intéressant. Créons une simulation avec un réseau de 8 éléments recevant trois signaux provenant d’angles différents : 20°, 25° et 40°. Le signal à 40° est reçu à une puissance bien inférieure aux deux autres, afin de complexifier la simulation. Notre objectif est de détecter les trois signaux, c’est-à-dire de repérer des pics significatifs (suffisamment élevés pour être extraits par un algorithme de détection de pics). Le code permettant de générer ce nouveau scénario est le suivant :
Nr = 8 # 8 éléments
theta1 = 20 / 180 * np.pi # conversion en radians
theta2 = 25 / 180 * np.pi
theta3 = -40 / 180 * np.pi
s1 = np.exp(2j * np.pi * d * np.arange(Nr) * np.sin(theta1)).reshape(-1,1) # 8x1
s2 = np.exp(2j * np.pi * d * np.arange(Nr) * np.sin(theta2)).reshape(-1,1)
s3 = np.exp(2j * np.pi * d * np.arange(Nr) * np.sin(theta3)).reshape(-1,1)
# Nous utiliserons 3 fréquences différentes. 1xN
tonalité1 = np.exp(2j*np.pi*0.01e6*t).reshape(1,-1)
tonalité2 = np.exp(2j*np.pi*0.02e6*t).reshape(1,-1)
tonalité3 = np.exp(2j*np.pi*0.03e6*t).reshape(1,-1)
X = s1@tone1 + s2@tone2 + 0.1 * s3@tone3 # notez que la dernière valeur représente 1/10e de la puissance
n = np.random.randn(Nr, N) + 1j*np.random.randn(Nr, N)
X = X + 0.05*n # 8xN
Vous pouvez placer ce code en haut de votre script, car nous générons un signal différent de celui de l’exemple original. Si nous appliquons notre formateur de faisceau MVDR à ce nouveau scénario, nous obtenons les résultats suivants :

Il fonctionne plutôt bien : nous pouvons observer les deux signaux reçus, séparés de seulement 5 degrés, ainsi que le troisième signal (à -40° ou 320°) reçu à une puissance dix fois inférieure à celle des autres. Appliquons maintenant le formateur de faisceau conventionnel à ce même scénario :
Bien que la forme du faisceau soit plutôt esthétique, il ne détecte pas du tout les trois signaux… En comparant ces deux résultats, nous pouvons constater l’avantage.
Pour information, il est possible d’optimiser le calcul de la DOA avec MVDR grâce à une astuce. Rappelons que la puissance d’un signal est calculée en prenant sa variance, qui est la moyenne du carré de son amplitude (en supposant que la valeur moyenne de nos signaux est nulle, ce qui est presque toujours le cas pour les signaux RF en bande de base). On peut représenter la puissance de notre signal après pondération par l’équation suivante :
Si l’on remplace la sommation par l’opérateur d’espérance et que l’on substitue l’équation des poids MVDR, on obtient :
Ce qui signifie que nous n’avons pas besoin d’appliquer les pondérations. Cette dernière équation de puissance ci-dessus peut être utilisée directement dans notre analyse DOA, ce qui nous permet d’économiser des calculs :
def power_mvdr(theta, X):
s = np.exp(2j * np.pi * d * np.arange(r.shape[0]) * np.sin(theta)) # vecteur de direction dans la direction souhaitée theta
s = s.reshape(-1,1) # transformation en vecteur colonne (taille 3x1)
R = (X @ X.conj().T)/X.shape[1] # Calcul de la matrice de covariance. Donne une matrice de covariance Nr x Nr des échantillons
Rinv = np.linalg.pinv(R) # 3x3. La pseudo-inverse est généralement plus performante que l'inverse exacte.
return 1/(s.conj().T @ Rinv @ s).squeeze()
Pour utiliser cette fonction dans la simulation précédente, au sein de la boucle for, il suffit d’effectuer le calcul suivant 10*np.log10(). C’est terminé ! Aucun poids n’est à appliquer ; nous avons omis de les calculer.
Il existe de nombreux autres formateurs de faisceaux, mais nous allons maintenant examiner l’influence du nombre d’éléments sur la formation de faisceaux et la détermination de la direction d’arrivée (DOA).
Matrice de covariance¶
Prenons un instant pour aborder la matrice de covariance spatiale, concept clé du beamforming adaptatif. Une matrice de covariance est une représentation mathématique de la similarité entre paires d’éléments d’un vecteur aléatoire (dans notre cas, les éléments de notre réseau, d’où le terme de matrice de covariance spatiale). Une matrice de covariance est toujours carrée, et les valeurs de sa diagonale correspondent à la covariance de chaque élément avec lui-même. Nous calculons une estimation de la matrice de covariance spatiale ; il ne s’agit que d’une estimation, compte tenu du nombre limité d’échantillons.
De manière générale, la matrice de covariance est définie comme suit : \(\mathrm{cov}(X) = E \left[ (X - E[X])(X - E[X])^H \right]\)
for wireless signals at baseband, \(E[X]\) is typically zero or very close to zero, so this simplifies to:
\(\mathrm{cov}(X) = E[X X^H]\)
Given a limited number of IQ samples, \(\boldsymbol{X}\), we can estimate this covariance, which we will denote as \(\hat{R}\):
where \(N\) is the number of samples (not the number of elements). In Python this looks like:
R = (X @ X.conj().T)/X.shape[1]
Alternatively, we can use the built-in NumPy function:
R = np.cov(X)
As an example, we will look at the spatial covariance matrix for the scenario where we only had one transmitter and three elements:
[[ 1.494+0.j 0.486+0.881j -0.543+0.839j]
[ 0.486-0.881j 1.517 +0.j 0.483+0.886j]
[-0.543-0.839j 0.483-0.886j 1.499+0.j ]]
Remarquez que les éléments diagonaux sont réels et sensiblement identiques. En effet, ils indiquent uniquement la puissance du signal reçu à chaque élément, qui sera sensiblement la même d’un élément à l’autre puisque leur gain est identique. Les éléments hors diagonale contiennent les valeurs importantes, même si l’examen des valeurs brutes ne nous apprend pas grand-chose, si ce n’est une forte corrélation entre les éléments.
Dans le cadre de la formation de faisceaux adaptative, vous observerez un motif où l’on calcule l’inverse de la matrice de corrélation spatiale. Cette inverse indique la relation entre deux éléments après avoir éliminé l’influence des autres éléments. On l’appelle « matrice de précision » en statistiques et « matrice de blanchiment » en radar.
Formateur de faisceaux LCMV¶
Bien que le MVDR soit puissant, que se passe-t-il si nous avons plusieurs signaux d’intérêts (SOI) ? Heureusement, grâce à une légère modification du MVDR, nous pouvons implémenter un schéma gérant plusieurs SOI, appelé formateur de faisceau à variance minimale contrainte linéaire (LCMV). Il s’agit d’une généralisation du MVDR, où l’on spécifie la réponse souhaitée pour plusieurs directions, un peu comme une version spatiale de la fonction firwin2() de SciPy pour ceux qui la connaissent. Le vecteur de pondération optimal pour le formateur de faisceau LCMV peut être résumé par l’équation suivante :
où \(C\) est une matrice comprenant les vecteurs de direction des SOI et des interférents correspondants, et \(f\) est le vecteur de réponse souhaité. Le vecteur \(f\) d’une ligne donnée prend la valeur 0 lorsque le vecteur de direction correspondant doit être annulé, et la valeur 1 lorsqu’un faisceau doit être dirigé vers cette ligne. Par exemple, avec deux sources d’intérêt et deux sources d’interférence, on peut définir \(f = [1,1,0,0]\). Le formateur de faisceaux LCMV est un outil puissant permettant de supprimer les interférences et le bruit provenant de plusieurs directions, tout en amplifiant le signal d’intérêt provenant également de plusieurs directions. Cependant, le nombre total d’annulations et de faisceaux pouvant être formés simultanément est limité par la taille du réseau (le nombre d’éléments). De plus, il est nécessaire de définir le vecteur de direction pour chaque source d’intérêt et chaque interféreur, ce qui n’est pas toujours possible en pratique. L’utilisation d’estimations peut dégrader les performances du formateur de faisceaux LCMV. C’est pourquoi nous préférons orienter les zones d’interférence nulle (ou « nulls ») à l’aide de la matrice de covariance spatiale \(R\) (basée sur les statistiques du signal reçu), plutôt que de les « coder en dur » en estimant l’angle d’arrivée (AoA) de l’interférent (ce qui peut engendrer des erreurs) et en construisant le vecteur de direction dans cette direction, en ajoutant un 0 à \(f\).
L’implémentation de LCMV en Python est très similaire à celle de MVDR, mais nous devons spécifier \(C\), composé de plusieurs vecteurs de direction potentiels, et \(f\), un tableau unidimensionnel de 1 et de 0, comme mentionné précédemment. L’extrait de code suivant illustre l’implémentation du formateur de faisceau LCMV pour deux angles d’incidence (15° et 60°). Rappelons que MVDR ne prend en charge qu’un seul angle d’incidence à la fois. Par conséquent, notre \(f\) est initialisé à \([1; 1]\) sans zéros, car nous n’incluons aucune zone d’interférence nulle « codée en dur ». Nous allons simuler un scénario avec quatre interférents arrivant d’angles de -60, -30, 0 et 30 degrés.
# Pointons vers le SOI à 15° et un autre SOI potentiel, non simulé, à 60°.
soi1_theta = 15 / 180 * np.pi # Conversion en radians
soi2_theta = 60 / 180 * np.pi
# Poids LCMV
R_inv = np.linalg.pinv(np.cov(X)) # 8x8
s1 = np.exp(2j * np.pi * d * np.arange(Nr) * np.sin(soi1_theta)).reshape(-1,1) # 8x1
s2 = np.exp(2j * np.pi * d * np.arange(Nr) * np.sin(soi2_theta)).reshape(-1,1) # 8x1
C = np.concatenate((s1, s2), axis=1) # 8x2
f = np.ones(2).reshape(-1,1) # 2x1
# Équation LCMV
# 8x8 8x2 2x8 8x8 8x2 2x1
w = R_inv @ C @ np.linalg.pinv(C.conj().T @ R_inv @ C) @ f # Sortie : 8x1
Nous pouvons tracer le diagramme de rayonnement de w à l’aide de la méthode FFT présentée précédemment :

Comme vous pouvez le constater, nous avons des faisceaux pointant dans les deux directions d’intérêt. Des points nuls sont ajoutés aux emplacements des interférents (comme pour le MVDR, il n’est pas nécessaire de spécifier la position des émetteurs ; le logiciel la détermine à partir du signal reçu). Des points verts et rouges sont ajoutés au graphique pour indiquer les angles d’arrivée (AoA) des SOI et des interférents, respectivement.
# Simulation du signal reçu
Nr = 8 # 8 éléments
theta1 = -60 / 180 * np.pi # Conversion en radians
theta2 = -30 / 180 * np.pi
theta3 = 0 / 180 * np.pi
theta4 = 30 / 180 * np.pi
s1 = np.exp(2j * np.pi * d * np.arange(Nr) * np.sin(the)
s2 = np.exp(2j * np.pi * d * np.arange(Nr) * np.sin(theta2)).reshape(-1,1)
s3 = np.exp(2j * np.pi * d * np.arange(Nr) * np.sin(theta3)).reshape(-1,1)
s4 = np.exp(2j * np.pi * d * np.arange(Nr) * np.sin(theta4)).reshape(-1,1)
# we'll use 3 different frequencies. 1xN
tone1 = np.exp(2j*np.pi*0.01e6*t).reshape(1,-1)
tone2 = np.exp(2j*np.pi*0.02e6*t).reshape(1,-1)
tone3 = np.exp(2j*np.pi*0.03e6*t).reshape(1,-1)
tone4 = np.exp(2j*np.pi*0.04e6*t).reshape(1,-1)
X = s1 @ tone1 + s2 @ tone2 + s3 @ tone3 + s4 @ tone4
n = np.random.randn(Nr, N) + 1j*np.random.randn(Nr, N)
X = X + 0.5*n # 8xN
# Prenons comme exemples le SOI à 15 degrés, et un autre SOI potentiel que nous n'avons pas simulé à 60 degrés.
soi1_theta = 15 / 180 * np.pi # conversion en radians
soi2_theta = 60 / 180 * np.pi
# Poids du LCMV
R_inv = np.linalg.pinv(np.cov(X)) # 8x8
s1 = np.exp(2j * np.pi * d * np.arange(Nr) * np.sin(soi1_theta)).reshape(-1,1) # 8x1
s2 = np.exp(2j * np.pi * d * np.arange(Nr) * np.sin(soi2_theta)).reshape(-1,1) # 8x1
C = np.concatenate((s1, s2), axis=1) # 8x2
f = np.ones(2).reshape(-1,1) # 2x1
# Équation du LCMV
# 8x8 8x2 2x8 8x8 8x2 2x1
w = R_inv @ C @ np.linalg.pinv(C.conj().T @ R_inv @ C) @ f # la sortie est 8x1
# Tracé du diagramme de rayonnement
w = w.squeeze() # reduction à un tableau 1D
N_fft = 1024
w_padded = np.concatenate((w, np.zeros(N_fft - Nr))) # zero pad à N_fft éléments pour obtenir un meilleur résolution dans la FFT
w_fft_dB = 10*np.log10(np.abs(np.fft.fftshift(np.fft.fft(w_padded)))**2) # amplitude de la FFT en dB
w_fft_dB -= np.max(w_fft_dB) # normalisation à 0 dB au maximum
theta_bins = np.arcsin(np.linspace(-1, 1, N_fft)) # Associer les échantillons de la FFT à des angles en radians
fig, ax = plt.subplots(subplot_kw={'projection': 'polar'})
ax.plot(theta_bins, w_fft_dB) # MAKE SURE TO USE RADIAN FOR POLAR
# Add dots where interferers and SOIs are
ax.plot([theta1], [0], 'or')
ax.plot([theta2], [0], 'or')
ax.plot([theta3], [0], 'or')
ax.plot([theta4], [0], 'or')
ax.plot([soi1_theta], [0], 'og')
ax.plot([soi2_theta], [0], 'og')
ax.set_theta_zero_location('N') # Orienter 0 degré vers le haut
ax.set_theta_direction(-1) # Incrémenter dans le sens horaire
ax.set_thetagrids(np.arange(-90, 105, 15)) # c'est en degrés
ax.set_rlabel_position(55) # Éloigner les étiquettes de la grille des autres étiquettes
ax.set_thetamin(-90) # Afficher uniquement la moitié supérieure
ax.set_thetamax(90)
ax.set_ylim([-30, 1]) # En l'absence de bruit, réduire de 30 dB seulement
plt.show()
Il existe un cas d’utilisation particulier de LCMV auquel vous avez peut-être déjà pensé : supposons qu’au lieu de pointer le faisceau principal à exactement 20 degrés, vous souhaitiez un faisceau plus large que celui fourni par un formateur de faisceau classique. Pour ce faire, définissez le vecteur de réponse souhaité f comme un vecteur de 1 sur une plage d’angles (par exemple, plusieurs valeurs entre 10 et 30 degrés) et de 0 ailleurs. Cet outil puissant permet de créer un diagramme de rayonnement plus large que le lobe principal d’un formateur de faisceau classique, ce qui est toujours un avantage dans les situations réelles où l’angle d’arrivée exact est inconnu. La même approche peut être utilisée pour créer un zéro dans une direction spécifique, réparti sur une plage d’angles relativement large. N’oubliez pas que cela nécessite plusieurs degrés de liberté ! À titre d’exemple, simulons un réseau de 18 éléments et définissons l’angle d’intérêt entre 15 et 30 degrés à l’aide de 4 valeurs différentes de θ, et un angle nul entre 45 et 60 degrés à l’aide de 4 autres valeurs différentes de θ. Nous ne simulerons aucun interférent réel.
Nr = 18
X = np.random.randn(Nr, N) + 1j*np.random.randn(Nr, N) # Simulation d'un signal reçu composé uniquement de bruit.
# Poitons vers le SOI de 15 à 30 degrés en utilisant 4 thetas différents
soi_thetas = np.linspace(15, 30, 4) / 180 * np.pi # conversio en radians
# Let's make a null from 45 to 60 degrees using 4 different thetas
null_thetas = np.linspace(45, 60, 4) / 180 * np.pi # convert to radians
# poids LCMV
R_inv = np.linalg.pinv(np.cov(X))
s = []
for soi_theta in soi_thetas:
s.append(np.exp(2j * np.pi * d * np.arange(Nr) * np.sin(soi_theta)).reshape(-1,1))
for null_theta in null_thetas:
s.append(np.exp(2j * np.pi * d * np.arange(Nr) * np.sin(null_theta)).reshape(-1,1))
C = np.concatenate(s, axis=1)
f = np.asarray([1]*len(soi_thetas) + [0]*len(null_thetas)).reshape(-1,1)
w = R_inv @ C @ np.linalg.pinv(C.conj().T @ R_inv @ C) @ f # LCMV equation
# Tracé du diagramme de rayonnement comme précédemment...

Le faisceau et le point d’annulation sont répartis sur la plage demandée ! Essayez de modifier le nombre de θ pour le faisceau principal et/ou le point d’annulation, ainsi que le nombre d’éléments, afin de vérifier si les pondérations résultantes permettent d’obtenir la réponse souhaitée.
Orientation du point d’annulation¶
Maintenant que nous avons vu le LCMV, il est intéressant d’explorer une technique plus simple, utilisable avec les réseaux analogiques et numériques : l’orientation du point d’annulation. Il s’agit d’une extension du formateur de faisceau classique, permettant non seulement de diriger un faisceau dans la direction souhaitée, mais aussi de placer des points d’annulation à des angles spécifiques. Cette technique n’implique pas de modification des pondérations en fonction du signal reçu (par exemple, le coefficient de réflexion R n’est jamais calculé) et n’est donc pas considérée comme adaptative. Dans la simulation ci-dessous, il n’est même pas nécessaire de simuler un signal : il suffit de paramétrer les poids de notre formateur de faisceau en utilisant la technique de suppression des zéros pour placer des zéros à des angles prédéfinis, puis de visualiser le diagramme de rayonnement.
Les poids pour la suppression des zéros sont calculés en partant d’un formateur de faisceau conventionnel pointé dans la direction souhaitée, puis en utilisant l’équation d’annulation des lobes secondaires pour mettre à jour les poids afin d’inclure les zéros, un à un. L’équation d’annulation des lobes secondaires est :
où \(w_{\text{null}}\) représente le vecteur de direction dans la direction du point nul que l’on souhaite ajouter à \(w_{\text{orig}}\). Les pondérations sont mises à jour en soustrayant le vecteur de direction du point nul, mis à l’échelle, des pondérations actuelles. Le facteur d’échelle est calculé en projetant les pondérations actuelles sur le vecteur de direction du point nul, puis en divisant par la projection de ce vecteur sur lui-même. Cette opération est ensuite répétée pour chaque direction de point nul (\(w_{\text{orig}}\) correspond initialement aux pondérations de formation de faisceau conventionnelles, mais est mis à jour après l’ajout de chaque point nul). Le processus complet se présente comme suit :
Simulons un tableau de 8 éléments et insérons quatre éléments nuls :
d = 0.5
Nr = 8
theta_soi = 30 / 180 * np.pi # convert to radians
nulls_deg = [-60, -30, 0, 60] # degrees
nulls_rad = np.asarray(nulls_deg) / 180 * np.pi
# Start out with conventional beamformer pointed at theta_soi
w = np.exp(2j * np.pi * d * np.arange(Nr) * np.sin(theta_soi)).reshape(-1,1)
# Loop through nulls
for null_rad in nulls_rad:
# weights equal to steering vector in target null direction
w_null = np.exp(2j * np.pi * d * np.arange(Nr) * np.sin(null_rad)).reshape(-1,1)
# scaling_factor (complex scalar) for w at nulled direction
scaling_factor = w_null.conj().T @ w / (w_null.conj().T @ w_null)
print("scaling_factor:", scaling_factor, scaling_factor.shape)
# Update weights to include the null
w = w - w_null @ scaling_factor # sidelobe-canceler equation
# Plot beam pattern
N_fft = 1024
w_padded = np.concatenate((w.squeeze(), np.zeros(N_fft - Nr))) # zero pad to N_fft elements to get more resolution in the FFT
w_fft_dB = 10*np.log10(np.abs(np.fft.fftshift(np.fft.fft(w_padded)))**2) # magnitude of fft in dB
w_fft_dB -= np.max(w_fft_dB) # normalize to 0 dB at peak
theta_bins = np.arcsin(np.linspace(-1, 1, N_fft)) # Map the FFT bins to angles in radians
fig, ax = plt.subplots(subplot_kw={'projection': 'polar'})
ax.plot(theta_bins, w_fft_dB)
# Add dots where nulls and SOI are
for null_rad in nulls_rad:
ax.plot([null_rad], [0], 'or')
ax.plot([theta_soi], [0], 'og')
ax.set_theta_zero_location('N') # make 0 degrees point up
ax.set_theta_direction(-1) # increase clockwise
ax.set_thetagrids(np.arange(-90, 105, 15)) # it's in degrees
ax.set_rlabel_position(55) # Move grid labels away from other labels
ax.set_thetamin(-90) # only show top half
ax.set_thetamax(90)
ax.set_ylim([-40, 1]) # because there's no noise, only go down -40 dB
plt.show()
On obtient le diagramme de rayonnement suivant. Vous remarquerez peut-être des zones sans interférence à des endroits non spécifiés ; c’est normal et dû au nombre limité d’éléments. Avec un nombre d’éléments insuffisant, il se peut également que les zones sans interférence ou le faisceau ne soient pas positionnés exactement comme prévu, ou que le diagramme ne réponde pas du tout aux critères en raison d’un manque de degrés de liberté (nombre d’éléments moins 1).

MUSIC¶
Nous allons maintenant aborder un autre type de formateur de faisceau. Tous les précédents appartenaient à la catégorie « retard et sommation », mais nous allons maintenant explorer les méthodes de « sous-espace ». Celles-ci consistent à diviser le sous-espace du signal et le sous-espace du bruit, ce qui implique d’estimer le nombre de signaux reçus par le réseau pour obtenir un bon résultat. La classification multiple de signaux (MUSIC) est une méthode de sous-espace très répandue qui consiste à calculer les vecteurs propres de la matrice de covariance (une opération gourmande en ressources de calcul). Nous divisons les vecteurs propres en deux groupes : le sous-espace du signal et le sous-espace du bruit, puis nous projetons les vecteurs de direction dans le sous-espace du bruit et nous orientons le faisceau vers les zéros. Cela peut paraître complexe au premier abord, ce qui explique en partie pourquoi MUSIC semble parfois relever de la magie noire !
L’équation fondamentale de MUSIC est la suivante :
où \(V_n\) est la liste des vecteurs propres du sous-espace de bruit mentionnée précédemment (une matrice 2D). On la détermine en calculant d’abord les vecteurs propres de \(R\), ce qui se fait simplement avec w, v = np.linalg.eig(R) en Python, puis en divisant les vecteurs (w) en fonction du nombre de signaux que l’on estime reçus par le réseau. Il existe une astuce pour estimer ce nombre de signaux, que nous aborderons plus loin, mais il doit être compris entre 1 et Nr - 1. Autrement dit, lors de la conception d’un réseau, le nombre d’éléments doit être supérieur de 1 au nombre de signaux attendus. Il est important de noter que, dans l’équation ci-dessus, V_n ne dépend pas du vecteur de direction s ; nous pouvons donc le précalculer avant de parcourir l’angle θ. Voici le code MUSIC complet :
num_expected_signals = 3 # Try changing this!
# part that doesn't change with theta_i
R = np.cov(X) # Calcul de la matrice de covariance gives a Nr x Nr covariance matrix
w, v = np.linalg.eig(R) # Décomposition en valeurs propres, v[:,i] est le vecteur propre correspondant à la valeur propre w[i]
eig_val_order = np.argsort(np.abs(w)) # find order of magnitude of eigenvalues
v = v[:, eig_val_order] # sort eigenvectors using this order
# We make a new eigenvector matrix representing the "noise subspace", it's just the rest of the eigenvalues
V = np.zeros((Nr, Nr - num_expected_signals), dtype=np.complex64)
for i in range(Nr - num_expected_signals):
V[:, i] = v[:, i]
theta_scan = np.linspace(-1*np.pi, np.pi, 1000) # -180 to +180 degrees
results = []
for theta_i in theta_scan:
s = np.exp(2j * np.pi * d * np.arange(Nr) * np.sin(theta_i)) # Steering Vector
s = s.reshape(-1,1)
metric = 1 / (s.conj().T @ V @ V.conj().T @ s) # The main MUSIC equation
metric = np.abs(metric.squeeze()) # take magnitude
metric = 10*np.log10(metric) # convert to dB
results.append(metric)
results /= np.max(results) # normalize
En appliquant cet algorithme au scénario complexe que nous avons utilisé, nous obtenons les résultats très précis suivants, qui démontrent la puissance de MUSIC :

Et si l’on ignorait le nombre de signaux présents ? Il existe une astuce : trier les amplitudes des valeurs propres par ordre décroissant et les représenter graphiquement (en dB, cela peut être utile).
plot(10*np.log10(np.abs(w)),'.-')

Les valeurs propres associées au sous-espace de bruit seront les plus petites et tendront toutes vers la même valeur. On peut donc considérer ces faibles valeurs comme un « plancher de bruit », et toute valeur propre supérieure à ce plancher représente un signal. Ici, on observe clairement la réception de trois signaux, et l’algorithme MUSIC doit être ajusté en conséquence. Si le nombre d’échantillons IQ à traiter est faible ou si le rapport signal/bruit (SNR) des signaux est faible, leur nombre peut être moins évident. N’hésitez pas à expérimenter en ajustant num_expected_signals entre 1 et 7. Vous constaterez qu’une sous-estimation entraînera la perte de signaux, tandis qu’une surestimation n’aura qu’un impact mineur sur les performances.
Une autre expérience intéressante à tenter avec MUSIC consiste à déterminer la distance angulaire minimale à laquelle deux signaux peuvent arriver tout en conservant leur distinction ; les techniques de sous-espace sont particulièrement performantes dans ce cas. L’animation ci-dessous illustre un exemple, avec un signal à 18 degrés et un autre dont l’angle d’arrivée varie lentement.
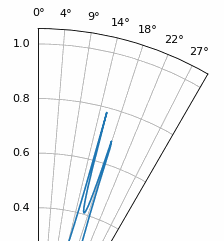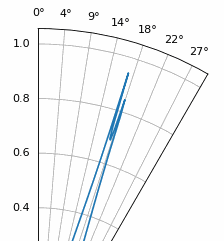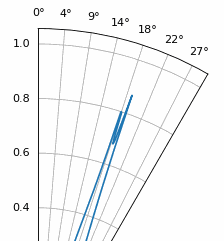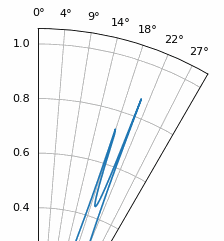
LMS¶
Le formateur de faisceau LMS (Least Mean Squares) est un formateur de faisceau à faible complexité introduit par Bernard Widrow. Il se distingue des autres formateurs de faisceau présentés jusqu’ici par deux aspects : 1) il requiert la connaissance du signal d’intérêt (SOI), ou au moins d’une partie de celui-ci (par exemple, une séquence de synchronisation, des signaux pilotes, etc.) ; 2) il est itératif, ce qui signifie que les pondérations sont affinées au fil d’un certain nombre d’itérations. Son fonctionnement repose sur la minimisation de l’erreur quadratique moyenne entre le signal désiré (le SOI) et la sortie du formateur de faisceau (c’est-à-dire les pondérations appliquées aux échantillons reçus). L’implémentation classique du LMS consiste à traiter chaque échantillon reçu comme une nouvelle étape du processus itératif, en appliquant les pondérations actuelles à cet échantillon et en calculant l’erreur. Cette erreur sert ensuite à affiner les pondérations, et le processus se répète. Le formateur de faisceau LMS peut être utilisé aussi bien pour la formation de faisceaux analogiques que numériques. L’algorithme LMS est défini par l’équation suivante :
où \(w_n\) représente le vecteur de poids à l’itération/échantillon \(n\), \(\mu\) est le pas d’intégration, \(x_n\) est l’échantillon reçu à \(n\), \(y_n\) est la valeur attendue à cette itération (c’est-à-dire le SOI connu), et est le conjugué complexe. Ne vous laissez pas impressionner par \(w_{n}^H x_n\), il s’agit simplement de l’application des poids actuels au signal d’entrée, ce qui correspond à l’équation standard de formation de faisceau. Le pas d’intégration \(\mu\) contrôle la vitesse de convergence des poids vers leurs valeurs optimales. Une petite valeur \(\mu\) de ce pas entraînera une convergence lente (par exemple, vous risquez de ne pas atteindre les poids optimaux avant la disparition du signal connu), tandis qu’une grande valeur peut engendrer une instabilité de l’algorithme. L’algorithme LMS est un outil puissant pour la formation de faisceaux adaptative, mais il présente certaines limitations. Il nécessite un SOI connu, qui n’est pas toujours disponible en pratique, et une synchronisation temporelle et fréquentielle est nécessaire dans le cadre du processus LMS afin que le modèle du SOI soit aligné avec les échantillons reçus.
Dans l’exemple de code Python ci-dessous, nous simulons un réseau à 8 éléments avec un signal d’intérêt (SOI) composé d’un code Gold répétitif transmis en BPSK. Les codes Gold sont utilisés en 5G et GPS et possèdent d’excellentes propriétés de corrélation croisée, ce qui les rend idéaux pour les signaux de synchronisation. La simulation inclut également deux sources d’interférence tonale, à 60° et -50°. Notez que cette simulation ne prend pas en compte les décalages temporels ou fréquentiels ; si tel était le cas, une synchronisation au SOI serait nécessaire dans le cadre du processus LMS (c’est-à-dire une formation de faisceau conjointe avec synchronisation). L’animation suivante illustre le balayage de l’angle d’arrivée du SOI et la représentation du diagramme de rayonnement généré par LMS après 10 000 échantillons. Observez comment LMS maintient le gain vers le SOI à 0 dB (sauf en présence d’une source d’interférence), tout en créant des zéros au niveau des sources d’interférence.
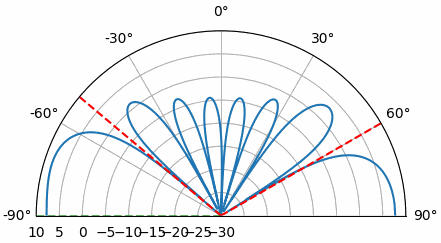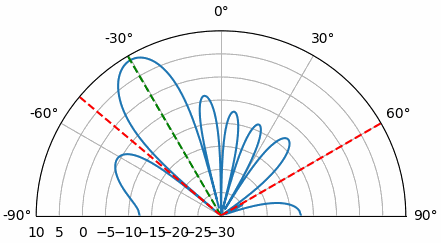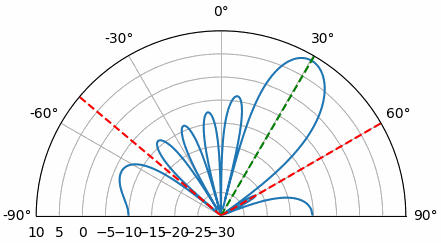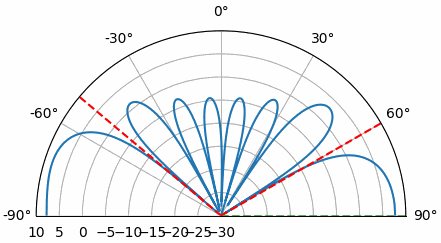
# Scénario
sample_rate = 1e6
d = 0.5 # espacement d'une demi longueur d'onde
N = 100000 # nombre d'échantillons à simuler
Nr = 8 # éléments
theta_soi = 20 / 180 * np.pi # conversion en radians
theta2 = 60 / 180 * np.pi
theta3 = -50 / 180 * np.pi
t = np.arange(N)/sample_rate # vecteur temps
s1 = np.exp(2j * np.pi * d * np.arange(Nr) * np.sin(theta_soi)).reshape(-1,1) # 8x1
s2 = np.exp(2j * np.pi * d * np.arange(Nr) * np.sin(theta2)).reshape(-1,1)
s3 = np.exp(2j * np.pi * d * np.arange(Nr) * np.sin(theta3)).reshape(-1,1)
# SOI est un gold_code, répété , de longueur 127
gold_code = np.array([-1, 1, 1, -1, 1, 1, 1, 1, -1, -1, -1, 1, 1, -1, -1, -1, -1, -1, 1, 1, 1, -1, -1, 1, 1, 1, -1, 1, 1, 1, 1, 1, 1, -1, -1, -1, 1, 1, 1, -1, -1, 1, 1, -1, -1, 1, -1, 1, -1, -1, 1, -1, -1, -1, -1, -1, -1, 1, 1, -1, 1, -1, 1, -1, 1, 1, -1, -1, -1, -1, 1, 1, 1, -1, 1, -1, 1, 1, 1, 1, 1, -1, -1, -1, -1, 1, 1, 1, -1, 1, -1, -1, -1, 1, 1, 1, 1, -1, 1, 1, 1, -1, 1, -1, -1, -1, -1, 1, -1, 1, 1, -1, -1, -1, -1, 1, -1, 1, 1, -1, -1, -1, -1, -1, -1, 1, 1])
soi_samples_per_symbol = 8
soi = np.repeat(gold_code, soi_samples_per_symbol)
num_sequence_repeats = int(N / soi.shape[0]) + 1 # nombre de fois où répéter la séquence pour N échantillons
soi = np.tile(soi, num_sequence_repeats)[:N] # répétition de la séquence pour remplir le temps simulé, puis tronquez-la.
soi = soi.reshape(1, -1) # 1xN
# Interférences, par exemple brouilleurs de tonalité, provenant de différentes directions
tone2 = np.exp(2j*np.pi*0.02e6*t).reshape(1,-1)
tone3 = np.exp(2j*np.pi*0.03e6*t).reshape(1,-1)
# simulation du signal reçu
r = s1 @ soi + s2 @ tone2 + s3 @ tone3
n = np.random.randn(Nr, N) + 1j*np.random.randn(Nr, N)
r = r + 0.5*n # 8xN
# LMS, ne connaissant pas la direction du SOI mais connaissant le signal SOI lui-même
mu = 0.5e-5 # taille du pas LMS
w_lms = np.zeros((Nr, 1), dtype=np.complex128) # commencer par des zéros
# Boucle sur les échantillons reçus
error_log = []
for i in range(N):
r_sample = r[:, i].reshape(-1, 1) # 8x1
soi_sample = soi[0, i] # scalar
y = w_lms.conj().T @ r_sample # application des poids
y = y.squeeze() # conversion en scalaire
error = soi_sample - y
error_log.append(np.abs(error)**2)
w_lms += mu * np.conj(error) * r_sample # Les poids restent de taille 8x1
w_lms /= np.linalg.norm(w_lms) # normalisation des poids
plt.plot(error_log)
plt.xlabel('Iteration')
plt.ylabel('Erreur des Moindre carrés')
plt.show()
# Tracer le diagramme de rayonnement comme indiqué précédemment
Essayez de modifier theta_soi, la quantité de bruit (c’est-à-dire 0.5*n) et la taille du pas mu pour voir comment l’algorithme LMS fonctionne.
Données d’entraînement¶
Dans le cadre du traitement d’antennes, le concept d’« entraînement » consiste à établir la matrice de covariance R avant l’apparition potentielle d’une source d’intérêt (SOI). Cette approche est particulièrement utile en radar, où, la plupart du temps, aucune SOI n’est présente et où le processus de détection repose sur le test d’une série d’angles pour vérifier sa présence. Le calcul de R avant l’apparition de la SOI permet de calculer les pondérations, à l’aide de méthodes telles que MVDR, en ne considérant dans la matrice de covariance que les interférences et le bruit ambiant. Ainsi, MVDR ne risque pas de placer un zéro à proximité de la direction de la SOI. Les pondérations sont ensuite appliquées au signal reçu pour déterminer si la SOI est présente à cet angle.
Pour illustrer l’intérêt des données d’entraînement, nous appliquerons MVDR à un enregistrement provenant d’une antenne réelle à 16 éléments (utilisant la plateforme QUAD-MxFE d’Analog Devices). Nous commencerons par effectuer une analyse MVDR classique, en utilisant l’intégralité du signal reçu pour calculer R et les pondérations. Nous utiliserons ensuite un enregistrement distinct, effectué avant l’activation du SOI, pour calculer R et les pondérations.
Ces enregistrements ont été réalisés à une fréquence radio de 3,3 GHz, avec un réseau d’antennes espacées de 0,045 mètre, soit d = 0,495. Une fréquence d’échantillonnage de 30 MHz a été utilisée. Nous désignerons les trois signaux par A, B et C. Le signal C correspond au SOI, tandis que les signaux A et B représentent les interférences. Par conséquent, nous avons besoin d’un enregistrement contenant uniquement les séquences A et B afin de créer les données d’entraînement, sans que A et B ne se déplacent entre l’acquisition des données d’entraînement et l’enregistrement incluant C. Vous trouverez ci-dessous les liens vers les deux enregistrements nécessaires :
https://github.com/777arc/777arc.github.io/raw/master/3p3G_A_B.npy
https://github.com/777arc/777arc.github.io/raw/master/3p3G_A_B_C.npy
Commençons par effectuer une reconstruction multivariée (MVDR) classique avec l’enregistrement A_B_C. Nous pouvons charger cet enregistrement, au format np.save(), contenant un tableau 2D. La première dimension correspond au nombre d’éléments du tableau, et la seconde au nombre d’échantillons.
import matplotlib.pyplot as plt
import numpy as np
# Array params
center_freq = 3.3e9
sample_rate = 30e6
d = 0.045 * center_freq / 3e8
print("d:", d)
# Incluant les trois signaux, nous appellerons C notre SOI
filename = '3p3G_A_B_C.npy'
X = np.load(filename)
Nr = X.shape[0]
Nous allons ensuite effectuer une analyse DOA de base avec MVDR, afin d’identifier les angles d’arrivée des trois signaux :
# Perform DOA to find angle of arrival of C
theta_scan = np.linspace(-1*np.pi/2, np.pi/2, 10000) # between -90 and +90 degrees
results = []
R = X @ X.conj().T # Calc covariance matrix. gives a Nr x Nr covariance matrix of the samples
Rinv = np.linalg.pinv(R) # pseudo-inverse tends to work better than a true inverse
for theta_i in theta_scan:
a = np.exp(2j * np.pi * d * np.arange(X.shape[0]) * np.sin(theta_i)) # steering vector in the desired direction theta_i
a = a.reshape(-1,1) # make into a column vector
power = 1/(a.conj().T @ Rinv @ a).squeeze() # MVDR power equation
power_dB = 10*np.log10(np.abs(power)) # power in signal, in dB so its easier to see small and large lobes at the same time
results.append(power_dB)
results -= np.max(results) # normalize to 0 dB at peak
Dans ce cas précis, il est plus simple d’utiliser un diagramme rectangulaire plutôt qu’un diagramme polaire. Nous avons nommé les signaux A, B et C.

Ensuite, si nous voulons appeler C notre SOI et utiliser MVDR pour créer des pondérations qui annuleront A et B tout en préservant C, nous devons connaître l’angle d’arrivée exact de C. Nous allons le faire en utilisant un argmax sur les résultats DOA que nous venons de créer, mais seulement après avoir annulé les angles correspondant à A et B (nous faisons cela en fixant les 60 % supérieurs de nos résultats DOA à une valeur très faible).
# Pull out angle of C, after zeroing out the angles that include the interferers
results_temp = np.array(results)
results_temp[int(len(results)*0.4):] = -9999*np.ones(int(len(results)*0.6))
max_angle = theta_scan[np.argmax(results_temp)] # radians
print("max_angle:", max_angle)
Il s’avère que C vaut -0,3407 radians ; c’est donc cette valeur qu’il faut utiliser pour calculer les pondérations MVDR. Vous avez déjà effectué cette opération à maintes reprises, il s’agit simplement de l’équation MVDR.
# Calcul des poids MVDR
s = np.exp(2j * np.pi * d * np.arange(Nr) * np.sin(max_angle)) # steering vector in the desired direction theta
s = s.reshape(-1,1) # make into a column vector
w = (Rinv @ s)/(s.conj().T @ Rinv @ s) # MVDR/Capon equation
Enfin, traçons le diagramme de rayonnement des pondérations MVDR que nous venons de calculer, ainsi que les résultats DOA obtenus précédemment, et une ligne verte pointillée à max_angle:
Expand this for the plotting code (it's nothing new)
# Calcul du modèle de faisceau
w = w.squeeze()
N_fft = 2048
w_padded = np.concatenate((w, np.zeros(N_fft - Nr))) # zero padding à N_fft élémentspour améliorer la résolution de la FFT
w_fft_dB = 10*np.log10(np.abs(np.fft.fftshift(np.fft.fft(w_padded)))**2) # amplitude of fft in dB
w_fft_dB -= np.max(w_fft_dB) # normalisation du maximum à 0 dB
theta_bins = np.arcsin(np.linspace(-1, 1, N_fft)) # Conversion des échantillons de la FFT en angles en radians
# Tracer le diagramme de rayonnement et les résultats de la direction d'arrivée
plt.plot(theta_bins * 180 / np.pi, w_fft_dB) # ASSUREZ-VOUS D'UTILISER LE RADIAN POUR LES REPRESENTATIONS POLAIRES
plt.plot(theta_scan * 180 / np.pi, results, 'r')
plt.vlines(ymax=np.max(results), ymin=np.min(results) , x=max_angle*180/np.pi, color='g', linestyle='--')
plt.xlabel("Angle [deg]")
plt.ylabel("Amplitude [dB]")
plt.title("Diagramme de faisceau et résultats de DOA, sans formation")
plt.grid()
plt.show()

Nous avons réussi à créer des zéros aux points A et B. Au point C (ligne pointillée verte), nous n’observons pas de zéro, ni de lobe principal apparent ; il s’agit plutôt d’un lobe réduit. Ceci est dû en partie à l’absence quasi totale d’énergie provenant des directions autres que A, B et C. Par conséquent, même si certains lobes sont visibles (par exemple autour de -70, 25 et 40 degrés), ils sont négligeables car aucun signal ne provient de cette direction. Une autre raison de la faible intensité du lobe en C est que le lobe principal est en quelque sorte en conflit avec les zéros qui auraient été créés par le MVDR si nous n’avions pas été pointés précisément dans cette direction. Cela étant dit, il serait souhaitable d’avoir un lobe principal marqué à notre position max_angle, et pour ce faire, nous devrons utiliser des données d’entraînement.
Nous allons maintenant charger l’enregistrement des points A et B uniquement, afin de créer les données d’entraînement. Dans une situation radar, cela équivaut à calculer R avant de transmettre une impulsion radar (idéalement, très peu de temps avant).
# Load "training data" which is just A and B, then calc Rinv
filename = '3p3G_A_B.npy'
X_A_B = np.load(filename)
R_training = X_A_B @ X_A_B.conj().T # Calc covariance matrix
Rinv_training = np.linalg.pinv(R_training)
Cette fois, la principale différence réside dans l’utilisation de Rinv_training pour le calcul des poids MVDR. Nous réutiliserons max_angle, valeur déjà déterminée. Ainsi, nous orientons le signal vers C sans pour autant l’intégrer au signal reçu utilisé pour le calcul de R et R_inv.
# Calcul des poids MVDR en utilisant Rinv_training
s = np.exp(2j * np.pi * d * np.arange(Nr) * np.sin(max_angle)) # Vecteur de direction dans la direction souhaitée θ
s = s.reshape(-1,1) # Conversion en vecteur colonne (taille 3x1)
w = (Rinv_training @ s)/(s.conj().T @ Rinv_training @ s) # équation MVDR/Capon
En utilisant la même méthode de représentation graphique, on obtient :

Notez que nous obtenons toujours des zéros provenant de A et B (le zéro de B est plus faible, mais B correspond également à un signal plus faible), mais cette fois-ci, un lobe principal important est dirigé vers notre angle d’intérêt, C. C’est là toute la puissance des données d’apprentissage, et pourquoi elles sont si importantes dans les applications radar.
Simulation d’interférences à large bande¶
La méthode que nous avons utilisée tout au long de ce chapitre pour simuler les signaux atteignant notre réseau depuis un certain angle d’arrivée (en multipliant le vecteur de direction par le signal émis) repose sur une hypothèse de bande étroite : le signal est supposé avoir une seule fréquence, et le vecteur de direction est calculé à cette fréquence. Cette approximation est acceptable pour de nombreux signaux, mais elle ne convient pas aux signaux à large bande, par exemple ceux dont la bande passante est supérieure à environ 5 % de la fréquence centrale. Nous aborderons brièvement une astuce permettant de simuler du bruit à large bande provenant d’une direction donnée (par exemple, un brouillage par barrage provenant d’un seul angle d’arrivée).
Cette méthode fonctionne en construisant une matrice de covariance R obtenue en sommant les contributions de chaque source de bruit à large bande. La matrice racine carrée A est ensuite calculée, et l’ensemble d’échantillons X est généré en « colorant » un bruit gaussien complexe standard avec A. Un paramètre clé est fractional_bw, qui correspond à la bande passante du signal de bruit divisée par sa fréquence centrale. Lorsque fractional_bw = 0, le code suivant devrait reproduire le même résultat que la méthode traditionnelle de simulation des signaux reçus. Le code Python ci-dessous peut être intégré aux exemples précédents pour simuler le signal reçu X.
N = 10 # Nombre d'éléments dans le réseau linéaire uniforme (ULA)
num_samples = 10000
d = 0.5
num_jammers = 3
jammer_pow_dB = np.array([30, 30, 30]) # Puissances des brouilleurs en dB
jammer_aoa_deg = np.array([-70, -20, 40]) # Angles des brouilleurs en degrés
jammer_aoa = np.sin(np.deg2rad(jammer_aoa_deg)) * np.pi
element_gain_dB = np.zeros(N) # Gains en dB pour les éléments du réseau (tous à 0 dB dans notre cas)
element_gain_linear = 10.0 ** (element_gain_dB / 10) # Conversion des gains du réseau en valeurs linéaires
fractional_bw = 0.1 # si ceci Si la valeur est 0, la méthode correspond à la méthode traditionnelle utilisant le facteur de réseau pour simuler les signaux reçus.
# Construction de la matrice de covariance NxN du brouilleur R
R = np.zeros((N, N), dtype=complex)
for m in range(N):
for n in range(N):
for j in range(num_jammers):
total_element_gain = np.sqrt(element_gain_linear[m] * element_gain_linear[n])
sinc_term = np.sinc(0.5 * fractional_bw * (m - n) * jammer_aoa[j] / np.pi)
exp_term = np.exp(1j * (m - n) * jammer_aoa[j])
R[m, n] += 10.0 ** (jammer_pow_dB[j] / 10) * total_element_gain * sinc_term * exp_term
R = np.eye(N, dtype=complex) + R
# Générer les échantillons reçus
A = fractional_matrix_power(R, 0.5) # Calculer la racine carrée de la matrice (factorisation de Cholesky effective)
A = A / np.sqrt(2)
X = np.zeros((N, num_samples), dtype=complex)
for k in range(num_samples):
noise_vec = np.random.randn(N) + 1j * np.random.randn(N) # bruit complexe
X[:, k] = A.conj().T @ noise_vec
Dans les graphiques ci-dessous, les pondérations MVDR sont calculées pour une visée à 20 degrés et affichées en noir, tandis que le formateur de faisceau conventionnel pour 20 degrés est représenté en bleu pointillé. Les trois sources de bruit sont indiquées en rouge. Dans ce premier graphique, une bande passante fractionnelle de 0 est utilisée, ce qui signifie que ces pondérations MVDR devraient correspondre aux scénarios précédents utilisant l’hypothèse de bande étroite. D’après le graphique, tout semble fonctionner correctement. Cependant, si le bruit réel s’avère être à large bande passante (et que votre SOI l’est également, ce qui signifie qu’un simple filtrage du bruit est impossible), la simulation ne correspondra pas à la réalité.

Nous appliquons maintenant une bande passante fractionnelle de 0,1, ce qui répartit les sources de bruit sur une large bande passante et entraîne la création de zones d’annulation beaucoup plus larges par MVDR. Dans de nombreux scénarios réels, cela représente une simulation plus réaliste.

Réseaux circulaires¶
Nous aborderons brièvement le réseau circulaire uniforme (UCA), une géométrie de réseau couramment utilisée pour la détection d’arrivée (DOA) car elle résout le problème d’ambiguïté à 180 degrés des réseaux circulaires uniformes (ULA). Le KrakenSDR, par exemple, est un réseau à 5 éléments, généralement disposés en cercle avec un espacement régulier. En théorie, trois éléments suffisent pour former un UCA, tout comme deux éléments suffisent pour un ULA.
Tout le code étudié jusqu’à présent s’applique aux UCA ; il suffit de remplacer l’équation du vecteur de direction par une équation spécifique aux UCA :
radius = 0.05 # normalisé par la longueur d'onde !
d = np.sqrt(2 * rayon**2 * (1 - np.cos(2*np.pi/Nr)))
sf = 1.0 / (np.sqrt(2.0) * np.sqrt(1.0 - np.cos(2*np.pi/Nr))) # Facteur d'échelle basé sur la géométrie, par exemple 1.0 pour un hexagone
x = d * sf * np.cos(2 * np.pi / Nr * np.arange(Nr))
y = -1 * d * sf * np.sin(2 * np.pi / Nr * np.arange(Nr))
s = np.exp(1j * 2 * np.pi * (x * np.cos(theta) + y * np.sin(theta)))
s = s.reshape(-1, 1) # Nrx1
Enfin, il est conseillé de balayer de 0 à 360 degrés, et non seulement de -90 à +90 degrés comme avec un réseau linéaire uniforme (ULA).
Pour les réseaux 2D (par exemple, rectangulaires), consultez le chapitre 2d-beamforming-chapter.
Conclusion et références¶
L’ensemble du code Python, y compris celui utilisé pour générer les figures et les animations, est disponible sur la page GitHub du manuel :.
- Implémentation DOA dans GNU Radio - https://github.com/EttusResearch/gr-doa
- Implémentation DOA utilisée par KrakenSDR - https://github.com/krakenrf/krakensdr_doa/blob/main/_signal_processing/krakenSDR_signal_processor.py
[1] Mailloux, Robert J. Phased Array Antenna Handbook. Deuxième édition, Artech House, 2005
[2] Van Trees, Harry L. Optimum Array Processing: Part IV of Detection, Estimation, and Modulation Theory. Wiley, 2002.
