 Online Python Console
Online Python Console One-time Donation
One-time Donation


16. DOA en Bundelvorming¶
In dit hoofdstuk behandelen we bundelvorming, direction-of-arrival (DOA, aankomstrichting) en phased arrays in het algemeen. We vergelijken verschillende arraytypen en geometrieen, en laten zien waarom elementafstand een cruciale rol speelt. Technieken zoals MVDR/Capon en MUSIC worden geintroduceerd en gedemonstreerd met Python-simulaties. N.B. Dit hoofdstuk wordt momenteel vertaald en kan nog fouten bevatten.
16.1. Bundelvorming Overzicht¶
Een phased array, ook wel elektronisch gestuurde array genoemd, is een verzameling antennes die je aan zend- en ontvangstzijde kunt gebruiken in communicatie- en radarsystemen. Je ziet phased arrays op de grond, in de lucht en op satellieten. De antennes in de array noemen we meestal elementen, en soms wordt de volledige array ook een sensor genoemd. Deze elementen zijn vaak omnidirectionele antennes, gelijkmatig verdeeld in een lijn of over twee dimensies.
Bundelvorming is een signaalverwerkingstechniek voor antenne-arrays waarmee je een ruimtelijk filter maakt: signalen uit ongewenste richtingen worden onderdrukt en gewenste richtingen versterkt. Je kunt bundelvorming gebruiken om de SNR van gewenste signalen te verhogen, stoorzenders te nullen, bundelpatronen te vormen, of zelfs meerdere datastromen op dezelfde tijd en frequentie te verzenden/ontvangen. Hiervoor gebruiken we gewichten (coefficienten) per array-element, digitaal of analoog. Door deze gewichten te sturen vorm je bundels en nullen, vandaar de naam bundelvorming. Dat sturen gaat extreem snel; veel sneller dan mechanisch gimbal-antennes, die je als alternatief kunt zien. In dit hoofdstuk behandelen we bundelvorming vooral vanuit communicatielinks, waar de ontvanger een of meer signalen met zo hoog mogelijke SNR wil ontvangen. In radar speelt bundelvorming eveneens een grote rol, met als doel detectie en tracking van doelen.

Bundelvormingstechnieken kun je grofweg in drie categorieen indelen: conventioneel, adaptief en blind. Conventionele bundelvorming is vooral nuttig wanneer je de aankomstrichting van het gewenste signaal al kent; je kiest gewichten die de arraygain in die richting maximaliseren. Dat kan aan zend- en ontvangstzijde. Adaptieve bundelvorming past de gewichten aan op basis van de invoer van de bundelvormer om een criterium te optimaliseren (bijvoorbeeld een stoorzender nullen of meerdere hoofdbundels vormen). Door de gesloten lus wordt adaptieve bundelvorming meestal aan ontvangstzijde gebruikt, waarbij de invoer van de bundelvormer simpelweg het ontvangen signaal is, en de gewichten op statistiek van die ontvangen data worden bijgewerkt.
De onderstaande taxonomie probeert de verschillende deelgebieden binnen bundelvorming te ordenen en tegelijk voorbeeldtechnieken te tonen:

16.2. DOA Overzicht¶
Direction-of-Arrival (DOA) in DSP/SDR is het proces waarbij je met een antenne-array de aankomstrichtingen van een of meer ontvangen signalen detecteert en schat. Dat verschilt van bundelvorming, waar de nadruk ligt op het ontvangen van een signaal terwijl ruis en interferentie zo veel mogelijk worden onderdrukt. Hoewel DOA duidelijk onder het bundelvormingsdomein valt, raken de termen in de praktijk snel door elkaar. Sommige technieken, zoals conventionele en MVDR-bundelvorming, kun je zowel voor bundelvorming als DOA gebruiken. Voor DOA sweep je dan over hoeken, voer je per hoek de bundelvormingsstap uit, en zoek je pieken in het resultaat. Elke piek betekent dat er een signaal is, maar niet direct of dit het gewenste signaal, een stoorzender of een multipadreflectie is. Je kunt deze DOA-methoden zien als een omhulsel rond een specifieke bundelvormer. Andere bundelvormers laten zich niet eenvoudig in een DOA-routine verpakken, bijvoorbeeld door extra invoer die je binnen DOA niet beschikbaar hebt. Daarnaast zijn er DOA-methoden zoals MUSIC en ESPRIT die strikt voor DOA bedoeld zijn en geen bundelvormer zijn. Omdat veel bundelvormingsmethoden aannemen dat je de aankomstrichting van het gewenste signaal kent, moet je bij beweging van doel of array continu DOA blijven doen als tussenstap, zelfs als je hoofddoel demodulatie van het gewenste signaal is.
Phased arrays en bundelvorming/DOA worden breed toegepast, maar je ziet ze vooral terug in radarsystemen, nieuwere wifi-standaarden, mmWave binnen 5G, satellietcommunicatie en stoorzenders. Algemeen geldt: toepassingen die een hoge antennegain vereisen, of een snel stuurbare hoge-gain antenne, zijn goede kandidaten voor phased arrays.
16.3. Typen Arrays¶
Phased arrays vallen grofweg in drie typen uiteen:
- Analoog, ook wel passive electronically scanned array (PESA) of traditionele phased array. Hier sturen analoge faseverschuivers de bundel. Aan ontvangstzijde tel je alle elementen op na faseverschuiving (en eventueel regelbare versterking), waarna je naar een enkel kanaal omlaag converteert en ontvangt. Aan zendzijde gebeurt het omgekeerde: een enkel digitaal signaal gaat de analoge keten in, waarna faseverschuivers en gain-trappen het signaal per antenne-element vormen. Digitale faseverschuivers hebben een eindige bitresolutie en besturingslatentie. Een belangrijk voordeel van analoge bundelvorming is dat sterke stoorzenders al voor de ADC kunnen worden genuld, zodat de ontvanger niet verzadigt.
- Digitaal, ook wel active electronically scanned array (AESA), waarbij elk element een eigen RF-front-end heeft en de bundelvorming volledig digitaal plaatsvindt. Dit is doorgaans de duurste aanpak omdat RF-componenten kostbaar zijn, maar je krijgt er veel flexibiliteit en snelheid voor terug, plus toegang tot adaptieve technieken die we later behandelen. Digitale arrays passen goed bij SDR’s, al begrenst het aantal SDR-kanalen het aantal elementen.
- Hybride, waarbij de array uit meerdere subarrays bestaat die afzonderlijk op analoge arrays lijken, terwijl elke subarray wel een eigen RF-front-end heeft zoals bij digitale arrays. Dit is in moderne systemen vaak de meest gebruikte aanpak omdat het een goede balans biedt. Hybride arrays kunnen adaptieve technieken gebruiken en tegelijk sterke interferentie al in het analoge domein onderdrukken voor de ADC, wat vooral in radar en in vijandige RF-omgevingen belangrijk is.
Let op: de termen PESA en AESA worden vooral in radarcontext gebruikt en de precieze afbakening is niet altijd scherp. Daarom zijn de termen analoog/digitaal/hybride vaak duidelijker en breder toepasbaar.
Hieronder vind je een voorbeeld van de drie typen:

Naast deze drie typen is ook de geometrie belangrijk. De eenvoudigste vorm is de uniforme lineaire array (ULA), waarbij antennes op een rechte lijn met gelijke afstand staan (1D). ULA’s hebben een 180-gradenambiguiteit, waar we later op terugkomen. Een oplossing is antennes in een cirkel plaatsen: de uniforme cirkelarray (UCA). Voor 2D-bundels gebruiken we meestal een uniforme rechthoekige array (URA), met een rasterpatroon.
In dit hoofdstuk focussen we op digitale arrays, omdat die beter aansluiten op simulatie en DSP. De concepten gelden echter ook voor analoge en hybride arrays. In het volgende hoofdstuk werken we praktisch met de “Phaser”-SDR van Analog Devices, met een 10 GHz 8-element analoge array met fase- en gain-shifters, gekoppeld aan een Pluto en Raspberry Pi. We focussen hier vooral op ULA-geometrie omdat die de eenvoudigste wiskunde en code geeft, maar de kernideeen gelden ook voor andere geometrieen; aan het einde raken we UCA kort aan.
16.4. Eisen SDR¶
Analoge phased arrays gebruiken per kanaal/element een faseverschuiver (en vaak ook een regelbare gain-trap) in analoge RF-hardware. Dat betekent dat een analoge phased array meestal gespecialiseerde hardware is naast je SDR, of speciaal voor een toepassing wordt ontworpen. Aan de andere kant kan elke SDR met meer dan een kanaal als digitale array werken zonder extra hardware, mits de kanalen fasecoherent zijn en dezelfde klok gebruiken; dat is doorgaans zo bij SDR’s met meerdere ontvangstkanalen op dezelfde print.
Er zijn veel SDR’s met twee ontvangstkanalen, zoals de Ettus USRP B210 en Analog Devices Pluto (waar het tweede kanaal via een uFL-connector op het bord beschikbaar is). Boven twee kanalen kom je helaas vaak in het $10k+-segment terecht (stand 2023), zoals de Ettus USRP N310 of Analog Devices QuadMXFE (16 kanalen). Een belangrijk probleem is dat goedkope SDR’s meestal niet eenvoudig te koppelen zijn om op te schalen in kanaalaantal. Een uitzondering is de KerberosSDR (4 kanalen) en KrakenSDR (5 kanalen), die meerdere RTL-SDR’s met gedeelde LO combineren tot een betaalbare digitale array. Nadeel is de beperkte samplerate (tot 2,56 MHz) en het beperkte afstembereik (tot 1766 MHz). De KrakenSDR-print en een voorbeeld van een antenne-opstelling staan hieronder.

In dit hoofdstuk gebruiken we geen specifieke SDR-hardware; in plaats daarvan simuleren we ontvangen signalen in Python en doorlopen we de DSP-stappen voor bundelvorming/DOA bij digitale arrays.
16.5. Introductie Matrix wiskunde in Python/NumPy¶
Python heeft veel voordelen ten opzichte van MATLAB. Het is gratis en open-source en heeft een diversiteit aan toepassingen. Het heeft een levendige gemeenschap, indexen beginnen bij 0 zoals in elke andere taal, het wordt gebruikt binnen AI/ML, en er lijkt een bibliotheek te zijn voor alles wat je maar kunt bedenken.
Maar waar Python tekort schiet, is de syntax van matrixmanipulatie (berekenings- /snelheidsgewijs is het snel genoeg, met functies die efficiënt in C/C++ zijn geïmplementeerd). Het helpt ook niet dat er meerdere manieren zijn om matrices in Python te vertegenwoordigen, waarbij de methode np.matrix is verouderd ten gunste van np.ndarray. In dit hoofdstuk geven we een korte inleiding over het uitvoeren van matrixwiskunde in Python met behulp van NumPy, zodat je je comfortabeler voelt wanneer we bij de DOA-voorbeelden komen.
We zullen beginnen met het vervelendste deel van matrixwiskunde met NumPy: vectoren worden behandeld als 1D arrays. Het is dus onmogelijk om onderscheid te maken tussen een rij- of kolomvector (het wordt standaard als een rijvector behandeld). In MATLAB is een vector een 2D-object.
In Python kun je een nieuwe vector maken met a = np.array([2,3,4,5]) of een lijst omzetten in een vector met mylist = [2, 3, 4, 5] en dan a = np.asarray(mylist), maar zodra je enige matrixwiskunde wilt doen, is de oriëntatie belangrijk, en a wordt geïnterpreteerd als een rijvector.
De vector transponderen met bijv. a.T zal het niet veranderen in een kolomvector! De manier om van een normale vector a een kolomvector te maken, is door a = a.reshape(-1,1) te gebruiken. De -1 vertelt NumPy om de grootte van deze dimensie automatisch te bepalen, terwijl de tweede dimensie lengte 1 behoudt, dus het is vanuit een wiskundig perspectief nog steeds 1D. Het is maar één extra regel, maar het kan de leesbaarheid van matrix code echt verstoren.
Als een kort voorbeeld voor matrixwiskunde in Python zullen we een 3x10 matrix vermenigvuldigen met een 10x1 matrix. Onthoud dat 10x1 10 rijen en 1 kolom betekent. Het is dus een kolomvector omdat het slechts één kolom is. In school hebben we geleerd dat, omdat de binnenste dimensies overeenkomen, dit een geldige matrixvermenigvuldiging is, en dat de resulterende matrix 3x1 groot is (de buitenste dimensies). We zullen np.random.randn() gebruiken om de 3x10 te maken, en np.arange() om de 10x1 te maken:
A = np.random.randn(3,10) # 3x10
B = np.arange(10) # 1D array met lengte 10
B = B.reshape(-1,1) # 10x1
C = A @ B # matrixvermenigvuldiging
print(C.shape) # 3x1
C = C.squeeze() # zie het volgende deel
print(C.shape) # 1D array met lengte 3, makkelijker om te plotten of verder te gebruiken
Na het uitvoeren van matrixwiskunde, kan het resultaat er ongeveer zo uitzien: [[ 0. 0.125 0.251 -0.376 -0.251 ...]]. Deze data heeft duidelijk maar 1 dimensie, maar je kunt het niet doorgeven aan andere functies zoals plot(). Je krijgt een foutmelding of lege grafiek.
Dit komt omdat het resultaat technisch gezien een 2D-Pythonarray is. Je moet het naar een 1D-array omzetten met a.squeeze().
De squeeze()-functie verwijdert alle dimensies met lengte 1, en is handig bij het uitvoeren van matrixwiskunde in Python. In het bovenstaande voorbeeld zou het resultaat [ 0. 0.125 0.251 -0.376 -0.251 ...] zijn (let op de ontbrekende tweede haakjes). Dit kan nu verder gebruikt worden om een grafiek te plotten of iets anders te doen.
De beste check die je op je matrixwiskunde kunt uitvoeren is het afdrukken van de dimensies (met A.shape) en te controleren of ze zijn wat je verwacht. Overweeg om de dimensies op elke regel als commentaar te plaatsen, zodat nadien controleren makkelijker wordt.
Hier zijn enkele veelvoorkomende bewerkingen in zowel MATLAB als Python, als een soort spiekbriefje:
| Operatie | MATLAB | Python/NumPy |
|---|---|---|
Maak een rijvector met grootte 1 x 4 |
a = [2 3 4 5]; |
a = np.array([2,3,4,5]) |
Maak een kolomvector met grootte 4 x 1 |
a = [2; 3; 4; 5]; or a = [2 3 4 5].' |
a = np.array([[2],[3],[4],[5]]) or a = np.array([2,3,4,5]) then a = a.reshape(-1,1) |
| Maak een 2D Matrix | A = [1 2; 3 4; 5 6]; |
A = np.array([[1,2],[3,4],[5,6]]) |
| Krijg grootte van een matrix | size(A) |
A.shape |
| Transponeer matrix \(A^T\) | A.' |
A.T |
| Complex Conjugeerde transponatie a.k.a. Conjugeerde Transponatie a.k.a. Hermitische Transponatie a.k.a. \(A^H\) |
A' |
A.conj().T (Helaas is er geen A.H voor ndarrays) |
| Vermenigvulging per element | A .* B |
A * B or np.multiply(a,b) |
| Matrixvermenigvuldiging | A * B |
A @ B or np.matmul(A,B) |
| Inwendig product van twee vectoren (1D) | dot(a,b) |
np.dot(a,b) (gebruik np.dot nooit voor 2D) |
| Aan elkaar plakken van matrices | [A A] |
np.concatenate((A,A)) |
16.6. Stuurvector¶
Voor we naar de leuke stukken gaan moeten we eerst een beetje wiskunde doen, maar dit deel is zo opgezet dat het relatief rechttoe rechtaan blijft en met figuren wordt ondersteund. We gebruiken alleen basale goniometrische en exponentiele eigenschappen. Deze basis is belangrijk om later de Python-code voor DOA goed te begrijpen.
We hebben een 1 dimensionale array van antennes die uniform zijn uitgespreid:

In dit voorbeeld komt het signaal van rechts dus het raakt het meest rechtste element als eerste. Laten we de vertraging berekenen tussen wanneer het signaal het eerste element raakt en wanneer het het volgende element bereikt. We kunnen dit doen door het volgende trigonometrische probleem te vormen, probeer te begrijpen hoe deze driehoek is gevormd vanuit het bovenstaande figuur. Het rode segment vertegenwoordigt de afstand die het signaal moet afleggen nadat het het eerste element heeft bereikt en voordat het het volgende element raakt.

Als je SOS CAS TOA nog kent, zijn we in dit geval geinteresseerd in de “aanliggende” en hebben we de lengte van de “schuine” (\(d\)), dus we moeten een cosinus gebruiken:
De aanliggende vertelt ons hoe ver het signaal moet reizen tussen het raken van het eerste en het raken van het volgende element, dus het wordt aanliggende \(= d \cos(90 - \theta)\). Nu is er een goniometrische identiteit die ons in staat stelt dit om te zetten in aanliggende \(= d \sin(\theta)\). Dit is slechts een afstand, we moeten dit omzetten in een tijd met behulp van de lichtsnelheid: verstreken tijd \(= d \sin(\theta) / c\) [seconden]. Deze vergelijking geldt tussen elk aangrenzend element van onze array, hoewel we het hele ding met een geheel getal kunnen vermenigvuldigen om de niet-aangrenzende elementen te berekenen, omdat ze gelijkmatig verdeeld zijn (dit zullen we later doen).
Nu zullen we deze gonio en lichtsnelheid formules koppelen aan de DSP-wereld. Laten we ons signaal op de basisband \(x(t)\) noemen en het verzenden op een bepaalde frequentie, \(f_c\), dus het verzonden signaal is \(x(t) e^{2j \pi f_c t}\). We gebruiken \(d_m\) om de afstand in meters tussen de elementen aan te geven. Laten we zeggen dat dit signaal het eerste element op tijd \(t = 0\) raakt, wat betekent dat het volgende element na \(d_m \sin(\theta) / c\) [seconden] wordt geraakt, zoals we hierboven hebben berekend. Het tweede element ontvangt dan:
tijdverschuivingen worden afgetrokken van het tijdsargument.
De ontvanger of SDR vermenigvuldigt het signaal met de draaggolf, maar in omgekeerde richting. Na de verschuiving naar de basisband ziet de ontvanger:
Met een kleine truc is dit nog verder te vereenvoudigen. Wanneer we een signaal samplen, kunnen we \(t\) vervangen door \(nT\), waarbij \(T\) de sampleperiode is en \(n\) gelijk is aan 0, 1, 2, 3… . Dan krijgen we \(x(nT - \Delta t) e^{-2j \pi f_c \Delta t}\). Voor een smalbandig signaal verandert de envelop langzaam genoeg over de propagatievertraging \(\Delta t\), zodat we \(x(nT - \Delta t) \approx x(nT)\) mogen aannemen. Dan blijft over: \(x(nT) e^{-2j \pi f_c \Delta t}\). Als de samplerate ooit hoog genoeg wordt om de lichtsnelheid over zeer kleine afstanden te benaderen, moeten we deze aanname opnieuw beoordelen. In de praktijk is de samplerate echter slechts iets hoger dan de bandbreedte van het signaal van interesse.
Laten we doorgaan met deze wiskunde maar dingen in discrete termen gaan vertegenwoordigen zodat het meer op onze Python-code lijkt. De laatste vergelijking kan als volgt worden voorgesteld, laten we \(\Delta t\) weer invullen:
We zijn bijna klaar. Gelukkig is er nog een vereenvoudiging die we kunnen maken. Herinner je de relatie tussen middenfrequentie en golflengte: \(\lambda = \frac{c}{f_c}\) of de vorm die we zullen gebruiken: \(f_c = \frac{c}{\lambda}\). Als we dit invullen krijgen we:
Wat we normaal willen doen met DOA is de afstand tussen twee elementen uit te drukken als een fractie van de golflengte in plaats van meters. De meest gekozen waarde tijdens het ontwerpen van een array is om voor \(d\) een halve golflengte te gebruiken. Ongeacht wat \(d\) is, vanaf dit punt gaan we \(d\) uitdrukken als een fractie van de golflengte in plaats van meters, waardoor de vergelijking en al onze code eenvoudiger wordt. Dus, \(d\) (zonder subscript \(m\)) is de genormaliseerde afstand, gelijk aan \(d = d_m / \lambda\). Dan kunnen we de vergelijking nog verder vereenvoudigen tot:
Dit is voor aangrenzende elementen, voor het \(k\)’de element moeten we gewoon \(d\) keer \(k\) vermenigvuldigen:
Nu moeten we afspreken welke conventies we willen gebruiken voor het coordinatenstelsel. In dit boek gaan we ervan uit dat 0 graden de raaklijn is van de plaatsing van de array (d.w.z. de lijn waarop de elementen zich bevinden), zoals te zien is in het bovenstaande diagram, en dat theta met de klok mee toeneemt. We zullen ook het meest linker element als het referentie-element beschouwen, en elk extra element ligt dan \(d_m\) verder naar rechts. Dit is het tegenovergestelde van ons diagram hierboven, dus we moeten de richting van de faseverschuiving omkeren, wat betekent dat we het negatieve teken moeten verwijderen:
Dit kunnen we in matrixformaat gieten door k op te laten lopen voor alle Nr`elementen in de array, van :math:`k = 0, 1, ... , N-1:
Hierbij is \(x\) de 1D rij-vector van het te verzenden signaal, en noemen we de getoonde kolom-vector de “stuurvector” (vaak aangeduid als \(s\) en in code s) en stellen we deze voor als een array, een 1D array voor een 1D antenne array, enz. Omdat \(e^{0} = 1\), is het eerste element van de stuurvector altijd 1, en de rest zijn faseverschuivingen ten opzichte van het eerste element:
Nu zijn we klaar! De bovenstaande vergelijking zul je in alle DOA artikelen en ULA implementaties tegenkomen! Je kunt ook tegenkomen dat \(2\pi\sin(\theta)\) als \(\psi\) wordt uitgedrukt, waardoor de stuurvector gelijk wordt aan \(e^{jd\psi}\), de meer algemene vorm (die we dus niet gebruiken). In python is s:
s = [np.exp(2j*np.pi*d*0*np.sin(theta)), np.exp(2j*np.pi*d*1*np.sin(theta)), np.exp(2j*np.pi*d*2*np.sin(theta)), ...] # k wordt hier dus opgehoogd
# of
s = np.exp(2j * np.pi * d * np.arange(Nr) * np.sin(theta)) # met Nr het aaantal ontvangstantennes
Merk op dat het eerste element in een 1+0j resulteert (omdat \(e^{0}=1\)); dit is logisch omdat alles hierboven relatief is aan dat eerste element, dus het ontvangt het signaal zoals het is zonder enige relatieve faseverschuivingen. Dit is puur hoe dat resulteert uit de wiskunde. In werkelijkheid kan elk element als referentie worden gebruikt, maar zoals je later in onze wiskunde/code zult zien, is het verschil in fase/amplitude dat tussen elementen wordt ontvangen wat telt. Het is allemaal relatief.
Vergeet niet dat d is uitgedrukt in golflengte als eenheid en niet in meters!
16.7. Een signaal ontvangen¶
Laten we het bovenstaande concept gebruiken om een ontvangen signaal signaal te simuleren. Voorlopig gebruiken we een enkele toon als verzendsignaal:
import numpy as np
import matplotlib.pyplot as plt
sample_rate = 1e6
N = 10000 # aantal samples om te simuleren
# Maak een toon om het verzonden signaal mee te simuleren
t = np.arange(N)/sample_rate # tijdsvector
f_tone = 0.02e6
tx = np.exp(2j * np.pi * f_tone * t)
Nu gaan we een antenne simuleren, met drie omnidirectionele antennes op een rij, elk een halve golflengte van elkaar verwijderd. We zullen simuleren dat het signaal van de zender op deze array aankomt onder een bepaalde hoek, \(\theta\). Het begrijpen van de factor a, is de reden waarom we al die wiskunde hierboven hebben doorgenomen.
d = 0.5 #afstand van een halve golflengte
Nr = 3
theta_degrees = 20 # aankomstrichting in graden
theta = theta_degrees / 180 * np.pi # naar radialen
s = np.exp(2j * np.pi * d * np.arange(Nr) * np.sin(theta)) # de stuurvector
print(s) # 3 complexe elementen, de eerste is 1+0j
Om de array factor toe te passen moeten we een matrixvermenigvuldiging doen van s en tx, dus laten we beide omzetten naar 2D met de methode die we eerder hebben besproken toen we de matrixwiskunde in Python doornamen. Eerst zetten we het om naar rijvectoren met onzearray.reshape(-1,1). Vervolgens voeren we de matrixvermenigvuldiging uit, aangegeven door het @-symbool. Ook moeten we met een transpositie-operatie tx omzetten van een rijvector naar een kolomvector (zie het als een rotatie van 90 graden), zodat de matrixvermenigvuldiging gelijke binnenste dimensies heeft.
s = s.reshape(-1,1) # omzetten naar een kolomvector
print(s.shape) # 3x1
tx = tx.reshape(1,-1) # meteen transponeren naar een rijvector
print(tx.shape) # 1x10000x
# matrixvermenigvuldiging
X = s @ tx # We simuleren het ontvangen signaal X met een matrixvermenigvuldiging
print(X.shape) # 3x10000. X is nu tweedimensionaal: tijd en afstand
Op dit moment is X een 2D array van 3 x 10000 elementen. Dit is omdat we drie array-elementen en 10000 gesimuleerde samples hebben. We gebruiken de hoofdletter X om duidelijk aan tegeven dat het om meerdere ontvangen, opgestapelde signalen gaat. We kunnen elk individueel signaal eruit halen en de eerste 200 samples laten zien. Hieronder zullen we alleen de reële delen weergeven, maar net als bij elk basisbandsignaal is er ook een imaginair deel. Een vervelend onderdeel van matrixwiskunde in Python is dat we .squeeze() moeten toevoegen oom de extra dimensies met lengte 1 te verwijderen, zodat we naar een normale 1D NumPy-array gaan die we verder kunnen gebruiken.
plt.plot(np.asarray(r[0,:]).squeeze().real[0:200]) # asarray en squeeze zijn helaas noodzakelijk omdat we van een 2D array komen
plt.plot(np.asarray(r[1,:]).squeeze().real[0:200])
plt.plot(np.asarray(r[2,:]).squeeze().real[0:200])
plt.show()

Het faseverschil tussen de element is zoals we hadden verwacht (tenzij het signaal haaks aankomt, en dan alle element op het zelfde moment bereikt, en er dus geen verschuiving is, zet theta op 0 om dit te zien). Probeer de hoek aan te passen en kijk wat er gebeurt.
Laten we als laatste nog wat ruis toevoegen aan dit ontvangen signaal, want elk signaal dat we zullen behandelen heeft een bepaalde hoeveelheid ruis. We willen de ruis toepassen nadat de stuurvector is toegepast, omdat elk element een onafhankelijk ruisignaal ervaart (we kunnen dit doen omdat AWG-ruis na een faseverschuiving nog steeds AWG-ruis is):
n = np.random.randn(Nr, N) + 1j*np.random.randn(Nr, N)
X = X + 0.1*n # X en n zijn allebij 3x10000

16.8. Conventionele Bundelvorming en DOA¶
We gaan deze samples X nu verwerken alsof we de aankomstrichting niet kennen, en vervolgens DOA uitvoeren. Daarbij schatten we de aankomstrichting(en) met DSP en Python-code. Zoals eerder in dit hoofdstuk besproken zijn bundelvorming en DOA sterk aan elkaar verwant en vaak gebaseerd op dezelfde technieken. In de rest van dit hoofdstuk bekijken we verschillende bundelvormers. Voor elke techniek starten we met de wiskunde/code om de gewichten, \(w\), te berekenen. Deze gewichten kunnen we vervolgens op het inkomende signaal X “toepassen” met de eenvoudige vergelijking \(w^H X\), of in Python w.conj().T @ X. In het voorbeeld hierboven is X een 3x10000-matrix, maar na het toepassen van de gewichten houden we 1x10000 over, alsof onze ontvanger maar één antenne heeft. Daarna kunnen we normale RF signaalbewerking toepassen op het signaal. Zodra we de bundelvormer hebben opgebouwd, passen we die toe op het DOA-probleem.
We beginnen met de “conventionele” bundelvormingsaanpak, ook wel delay-and-sum genoemd. Onze gewichtenvector w moet voor een uniforme lineaire array een 1D-array zijn. In ons voorbeeld met drie elementen is w een 3x1-array met complexe gewichten. Bij conventionele bundelvorming laten we de amplitudes van de gewichten op 1 staan en passen we alleen de fases aan, zodat het signaal constructief in de richting van het gewenste signaal optelt, aangeduid met \(\theta\). Dit blijkt exact dezelfde wiskunde te zijn als hierboven; onze gewichten zijn dus gewoon onze stuurvector.
of in Python:
w = np.exp(2j * np.pi * d * np.arange(Nr) * np.sin(theta)) # conventionele, oftewel delay-and-sum-beamformer
X_weighted = w.conj().T @ X # voorbeeld van gewichten toepassen op het ontvangen signaal (dus bundelvorming uitvoeren)
print(X_weighted.shape) # 1x10000
waar Nr het aantal elementen is in onze uniforme lineaire array met een onderlinge afstand van d golflengtefracties (meestal ~0,5). Zoals je ziet hangen de gewichten alleen af van de arraygeometrie en de gewenste hoek. Als onze array fasekalibratie nodig heeft, nemen we die kalibratiewaarden ook mee. Je ziet in de vergelijking voor w ook dat de gewichten complex zijn en allemaal een amplitude van één (unity) hebben.
Maar hoe kennen we de gewenste hoek theta? We moeten eerst DOA uitvoeren, waarbij we alle aankomstrichtingen van -π tot +π (-180 tot +180 graden) scannen (samplen), bijvoorbeeld in stappen van 1 graad. Voor elke richting berekenen we de gewichten met een bundelvormer; we beginnen met de conventionele bundelvormer. Als we de gewichten op X toepassen, krijgen we een 1D-array met samples, alsof we met één richtantenne ontvangen. Daarna kunnen we het signaalvermogen bepalen via de variantie met np.var(), en dit herhalen voor elke hoek in de scan. We plotten de resultaten en beoordelen ze visueel, maar in de praktijk zoekt RF-DSP meestal de hoek met het maximale vermogen (via een piekzoekalgoritme) en noemt die de DOA-schatting.
theta_scan = np.linspace(-1*np.pi, np.pi, 1000) # 1000 verschillende theta-waarden tussen -180 en +180 graden
results = []
for theta_i in theta_scan:
w = np.exp(2j * np.pi * d * np.arange(Nr) * np.sin(theta_i)) # conventionele, oftewel delay-and-sum-beamformer
X_weighted = w.conj().T @ X # pas de gewichten toe; onthoud dat X 3x10000 is
results.append(10*np.log10(np.var(X_weighted))) # signaalvermogen in dB, zodat kleine en grote lobben tegelijk zichtbaar zijn
results -= np.max(results) # normalize (optional)
# print de hoek die de maximale waarde geeft
print(theta_scan[np.argmax(results)] * 180 / np.pi) # 19.99999999999998
plt.plot(theta_scan*180/np.pi, results) # plot de hoek in graden
plt.xlabel("Theta [Degrees]")
plt.ylabel("DOA Metric")
plt.grid()
plt.show()

We hebben ons signaal gevonden. Je ziet nu waarschijnlijk ook waar de term “elektronisch gestuurde array” vandaan komt. Probeer de hoeveelheid ruis te verhogen om de limiet op te zoeken; bij lage SNR heb je mogelijk meer gesimuleerde samples nodig. Probeer ook de aankomstrichting te veranderen.
Als je de DOA-resultaten liever in een poolplot ziet, gebruik dan de volgende code:
fig, ax = plt.subplots(subplot_kw={'projection': 'polar'})
ax.plot(theta_scan, results) # GEBRUIK RADIALEN VOOR EEN POOLPLOT
ax.set_theta_zero_location('N') # maak dat 0 graden omhoog wijst
ax.set_theta_direction(-1) # laat de hoek met de klok mee toenemen
ax.set_rlabel_position(55) # verplaats rasterlabels weg van andere labels
plt.show()

We blijven dit patroon terugzien: over alle hoeken, op een bepaalde manier de gewichten berekenen en die vervolgens op het ontvangen signaal toepassen. In de volgende methode (MVDR) gebruiken we het ontvangen signaal X ook in de gewichtenberekening, waardoor het een adaptieve techniek wordt. Maar eerst bekijken we een paar interessante effecten van phased arrays, waaronder waarom er een tweede piek bij 160 graden staat.
16.9. 180-gradenambiguiteit¶
Laten we bespreken waarom er een tweede piek op 160 graden staat. De gesimuleerde DOA was 20 graden, en het is geen toeval dat 180 - 20 = 160. Stel je drie omnidirectionele antennes in een lijn op een tafel voor. De kijkrichting van de array staat 90 graden op de as van de array, zoals in het eerste diagram van dit hoofdstuk. Denk nu aan een zender vóór de antennes, ook op die (erg grote) tafel, zodat het signaal binnenkomt onder +20 graden ten opzichte van de kijkrichting. Voor de array is het faseverschil echter hetzelfde of het signaal van voren of van achteren komt. Dat zie je hieronder, met de array-elementen in rood en de twee mogelijke DOA-posities van de zender in groen. Daarom krijg je bij het uitvoeren van een DOA-algoritme altijd dit soort 180-gradenambiguiteit. De enige oplossing is een 2D-array, of een tweede 1D-array onder een andere hoek ten opzichte van de eerste. Je vraagt je misschien af of je dan net zo goed alleen van -90 tot +90 graden kunt rekenen om rekentijd te besparen. Dat klopt.

Laten we de aankomstrichting (Engels: Angle of Arrival, AoA) eens sweepen van -90 tot +90 graden, in plaats van hem constant op 20 te houden:
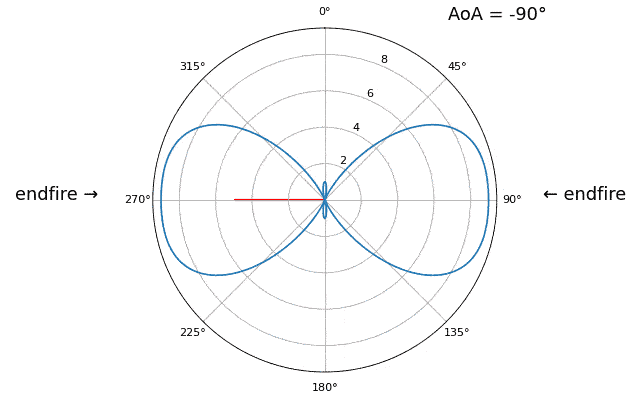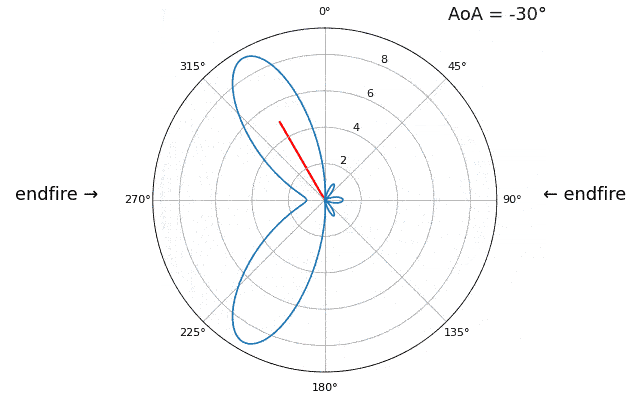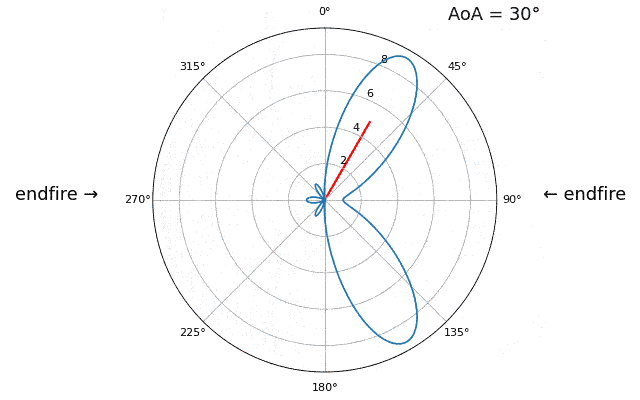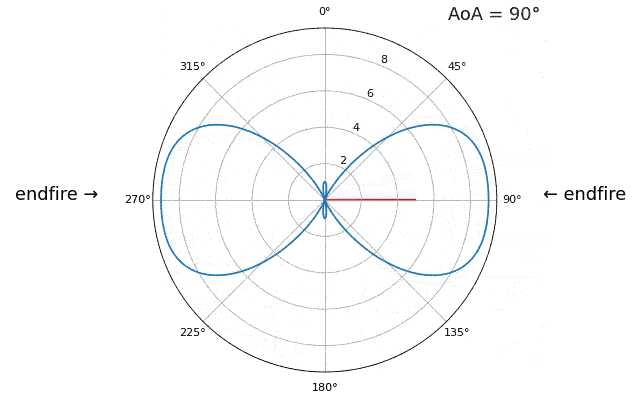
Wanneer we de endfire-regio van de array naderen (dus wanneer het signaal op of dicht bij de array-as aankomt), daalt de prestatie. We zien twee belangrijke verslechteringen: 1) de hoofdlob wordt breder en 2) er ontstaat ambiguiteit, waardoor je niet weet of het signaal van links of rechts komt. Deze ambiguiteit komt boven op de eerder besproken 180-gradenambiguiteit, waarbij je een extra lob op 180 - theta krijgt. Daardoor kunnen bepaalde AoA’s tot drie lobben van ongeveer gelijke grootte leiden. Deze endfire-ambiguiteit is logisch: de faseverschuivingen tussen elementen zijn identiek of het signaal nu van links of rechts van de array-as komt. Net als bij de 180-gradenambiguiteit is de oplossing een 2D-array of twee 1D-arrays onder verschillende hoeken. In het algemeen werkt bundelvorming het beste wanneer de hoek dichter bij de kijkrichting ligt.
Vanaf nu tonen we in poolplots alleen nog -90 tot +90 graden, omdat het patroon voor 1D-lineaire arrays (waar dit hoofdstuk over gaat) toch gespiegeld is rond de array-as.
16.10. Bundelpatroon¶
De grafieken die we tot nu toe hebben getoond zijn DOA-resultaten; ze geven het ontvangen vermogen per hoek na het toepassen van de bundelvormer. Ze horen bij een specifiek scenario met zenders op bepaalde hoeken. We kunnen echter ook het bundelpatroon zelf bekijken, dus vóórdat we een signaal ontvangen. Dit heet soms het rustpatroon of de arrayrespons.
Onthoud dat onze stuurvector, die we steeds terugzien,
np.exp(2j * np.pi * d * np.arange(Nr) * np.sin(theta))
de ULA-geometrie vastlegt, en als extra parameter alleen de richting heeft waar je naartoe wilt sturen. We kunnen het rustpatroon (arrayrespons) berekenen en plotten voor een gekozen stuurhoek. Dat laat de natuurlijke respons van de array zien als we geen extra bundelvorming toepassen. Dit kan door de FFT van de complex geconjugeerde gewichten te nemen, dus zonder for-loop. Het lastige deel is zero-padding voor extra resolutie en het mappen van FFT-bins naar hoeken in radialen of graden, waarbij een arcsinus nodig is, zoals je in het voorbeeld hieronder ziet.
Nr = 3
d = 0.5
N_fft = 512
theta_degrees = 20 # er is geen SOI; we verwerken geen samples, dit is alleen de richting waar we op richten
theta = theta_degrees / 180 * np.pi
w = np.exp(2j * np.pi * d * np.arange(Nr) * np.sin(theta)) # conventionele beamformer
w_padded = np.concatenate((w, np.zeros(N_fft - Nr))) # zero-pad naar N_fft elementen voor meer FFT-resolutie
w_fft_dB = 10*np.log10(np.abs(np.fft.fftshift(np.fft.fft(w_padded)))**2) # FFT-magnitude in dB
w_fft_dB -= np.max(w_fft_dB) # normalize to 0 dB at peak
# map FFT-bins naar hoeken in radialen
theta_bins = np.arcsin(np.linspace(-1, 1, N_fft)) # in radians
# vind het maximum zodat we het in de plot kunnen tonen
theta_max = theta_bins[np.argmax(w_fft_dB)]
fig, ax = plt.subplots(subplot_kw={'projection': 'polar'})
ax.plot(theta_bins, w_fft_dB) # GEBRUIK RADIALEN VOOR EEN POOLPLOT
ax.plot([theta_max], [np.max(w_fft_dB)],'ro')
ax.text(theta_max - 0.1, np.max(w_fft_dB) - 4, np.round(theta_max * 180 / np.pi))
ax.set_theta_zero_location('N') # laat 0 graden omhoog wijzen
ax.set_theta_direction(-1) # laat de hoek met de klok mee toenemen
ax.set_rlabel_position(55) # verplaats rasterlabels weg van andere labels
ax.set_thetamin(-90) # toon alleen de bovenste helft
ax.set_thetamax(90)
ax.set_ylim([-30, 1]) # zonder ruis hoeft de schaal maar tot -30 dB te gaan
plt.show()

Dit patroon blijkt bijna exact overeen te komen met het patroon dat je krijgt bij DOA met de conventionele bundelvormer (delay-and-sum), wanneer er één toon op theta_degrees aanwezig is en weinig tot geen ruis. De plot kan er anders uitzien door hoe ver de y-as in dB naar beneden loopt, of door de FFT-grootte waarmee dit rustpatroon is gemaakt. Probeer theta_degrees of het aantal elementen Nr te variëren om te zien hoe de respons verandert.
Voor het leuke, laat de volgende animatie het bundelpatroon van de conventionele bundelvormer zien, voor een 8-element-array die tussen -90 en +90 graden wordt gestuurd. Ook zie je de acht gewichten in het complexe vlak (reële en imaginaire as).
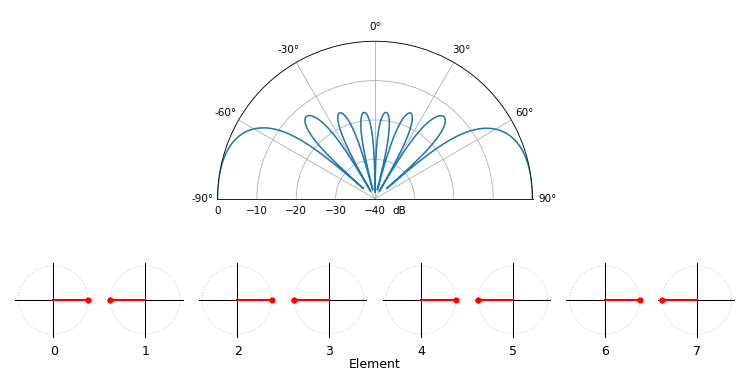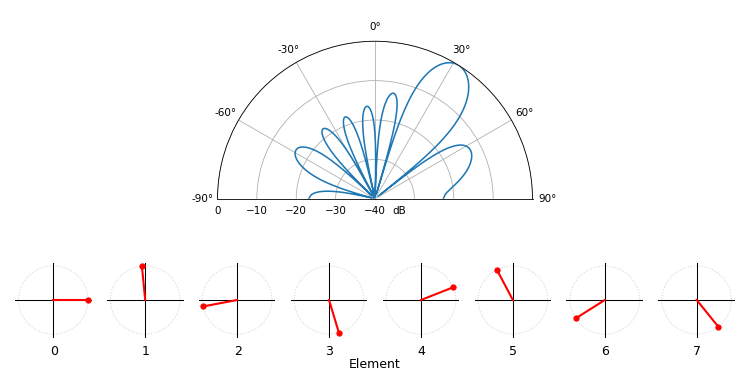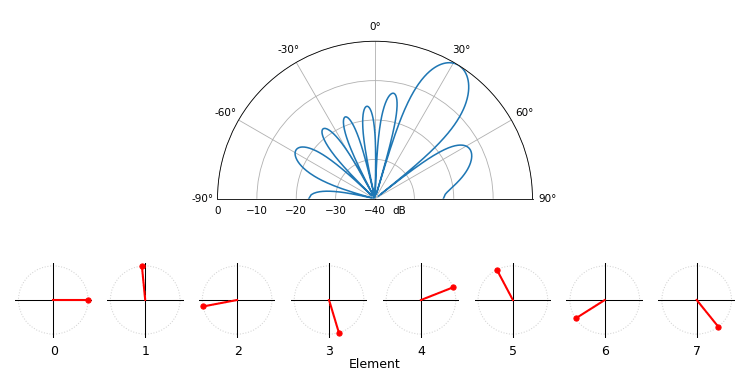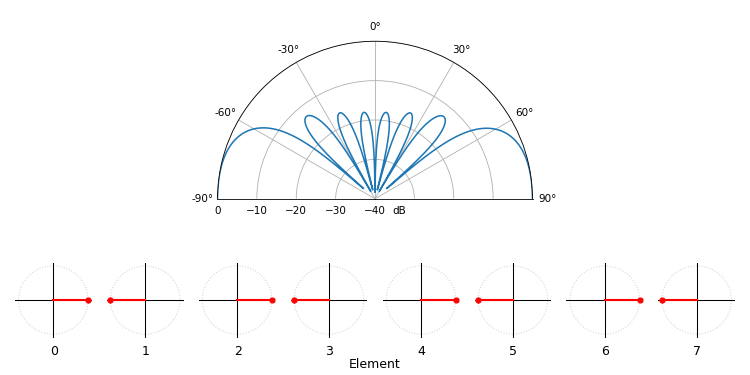
Let erop dat alle gewichten eenheidsamplitude hebben (ze blijven op de eenheidscirkel), en dat elementen met een hoger indexnummer sneller “draaien”. Als je goed kijkt, zie je dat ze bij 0 graden allemaal samenvallen; ze hebben dan allemaal 0 faseverschuiving (1+0j).
16.11. Array Pulsbreedte¶
Voor wie nieuwsgierig is: er bestaan vergelijkingen die de breedte van de hoofdlob benaderen op basis van het aantal elementen. Ze werken vooral goed bij grotere arrays (bijvoorbeeld 8 elementen of meer). De half-power beamwidth (HPBW) is de breedte op 3 dB onder de piek van de hoofdlob, en is ongeveer \(\frac{0.9 \lambda}{N_rd\cos(\theta)}\) [1]. Voor halve-golflengteafstand vereenvoudigt dit tot:
De first-null beamwidth (FNBW), dus de hoofdlobbreedte van nul tot nul, is ongeveer \(\frac{2\lambda}{N_rd}\) [1]. Voor halve-golflengteafstand vereenvoudigt dit tot:
Laten we de vorige code gebruiken maar Nr verhogen naar 16 elementen. Met de vergelijkingen hierboven zou de HPBW, gericht op 20 graden (0,35 radialen), ongeveer 0,12 radialen of 6,8 graden moeten zijn. De FNBW zou ongeveer 0,25 radialen of 14,3 graden moeten zijn. Laten we simuleren hoe dicht we daarbij in de buurt komen. Voor het bekijken van bundelbreedtes gebruiken we meestal rechthoekige plots in plaats van poolplots. Hieronder staan de resultaten, met HPBW in groen en FNBW in rood.

In de plot is het misschien lastig te zien, maar als je ver inzoomt blijkt de HPBW ongeveer 6,8 graden en de FNBW ongeveer 15,4 graden te zijn. Dat ligt dus behoorlijk dicht bij de berekening, zeker voor HPBW.
16.12. Wanneer d niet λ/2 is¶
Tot nu toe hebben we de elementafstand \(d\) gelijk genomen aan een halve golflengte. Een array voor 2,4 GHz wifi met λ/2-afstand heeft bijvoorbeeld een elementafstand van 3e8/2.4e9/2 = 12,5 cm (ongeveer 5 inch). Een 4x4-array komt dan uit op ongeveer 15” x 15” x de hoogte van de antennes. Soms kun je echter geen exacte λ/2-afstand halen, bijvoorbeeld door ruimtegebrek, of omdat dezelfde array op meerdere draaggolffrequenties moet werken.
Laten we bekijken wat er gebeurt als de afstand groter is dan λ/2, dus te groot, door \(d\) te variëren tussen λ/2 en 4λ. We laten de onderste helft van de poolplot weg, omdat die toch een spiegeling van de bovenkant is.
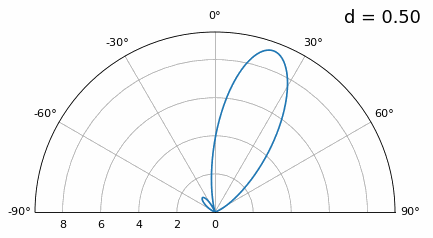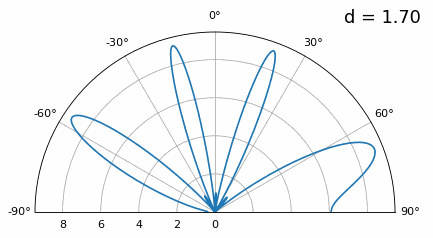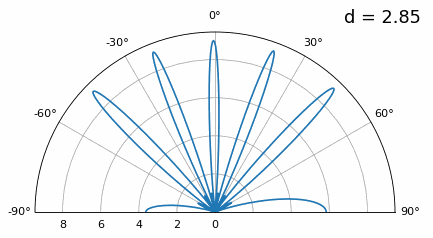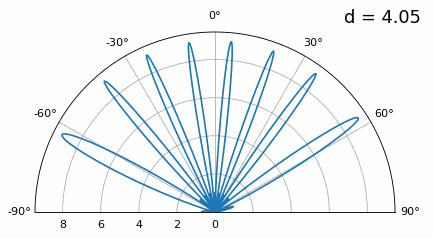
Zoals je ziet krijgen we, naast de eerder besproken 180-gradenambiguiteit, extra ambiguiteit. Die wordt erger naarmate \(d\) groter wordt (extra/foute lobben ontstaan). Deze extra lobben heten grating lobes en zijn het gevolg van “spatial aliasing”. Zoals we in het IQ-sampling-hoofdstuk hebben gezien: als je niet snel genoeg samplet, krijg je aliasing. Hetzelfde gebeurt in het ruimtelijke domein. Als elementen niet dicht genoeg op elkaar staan ten opzichte van de draaggolffrequentie van het waargenomen signaal, krijg je slechte analyseresultaten. Je kunt antenneafstand zien als het samplen van ruimte. In dit voorbeeld worden grating lobes pas echt problematisch bij \(d > \lambda\), maar ze ontstaan al zodra je boven λ/2 gaat. Dat komt doordat Nyquist zegt dat we minstens twee keer zo snel moeten samplen als het waargenomen signaal, dus twee samples per cyclus. Onze ruimtelijke samplefrequentie meten we in samples per meter. Omdat de equivalente radiaalfrequentie in de ruimte \(2\pi/\lambda\) radialen per meter is, en één cyclus \(2\pi\) radialen (360 graden) bevat, moeten we de ruimte minstens samplen met:
of, uitgedrukt in elementafstand \(d\) (in feite meter per ruimtelijke sample):
Zolang \(d \leq \lambda/2\) krijgen we geen grating lobes.
Wat gebeurt er dan als \(d\) kleiner is dan λ/2, bijvoorbeeld wanneer de array in een kleine ruimte moet passen? We weten dat we dan geen grating lobes krijgen, maar er gebeurt wel iets anders. Laten we dezelfde simulatie herhalen, startend bij 0,5λ en dan \(d\) verlagen:
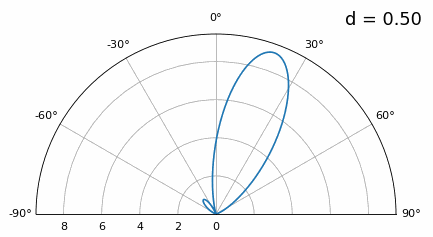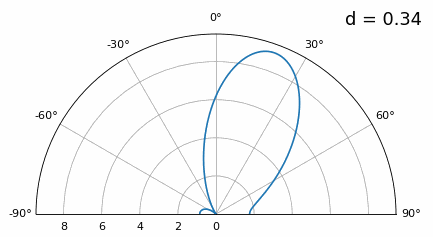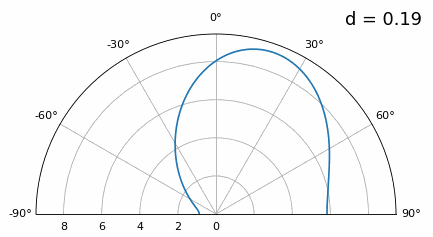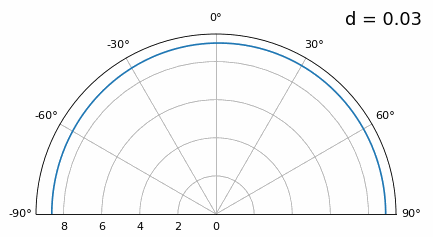
Terwijl de hoofdlob breder wordt als \(d\) kleiner wordt, blijft het maximum wel op 20 graden liggen en ontstaan er geen grating lobes. In theorie werkt dit dus nog steeds (tenminste bij hoge SNR en zolang onderlinge koppeling geen groot probleem wordt). Om beter te begrijpen wat er misgaat bij te kleine \(d\), herhalen we het experiment met een extra signaal dat binnenkomt op -40 graden:
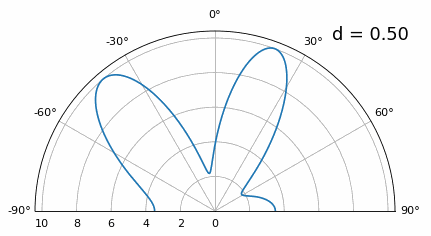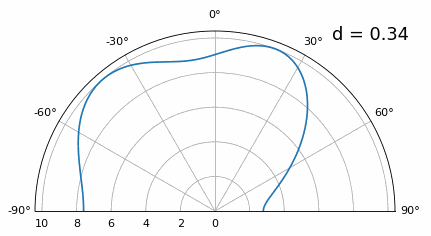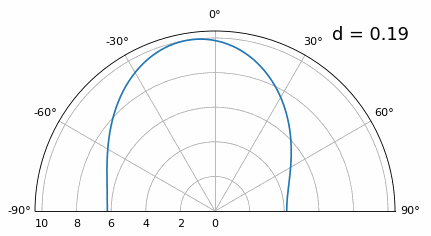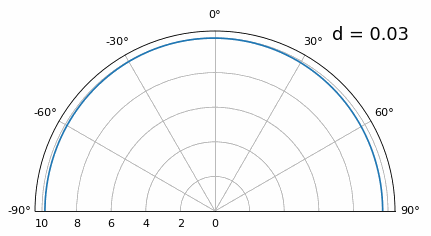
Zodra we onder λ/4 komen, is er nauwelijks nog onderscheid te maken tussen de twee verschillende paden en presteert de array slecht. Zoals we later in dit hoofdstuk zullen zien, zijn er bundelvormingstechnieken met scherpere bundels dan conventionele bundelvorming. Toch blijft het een belangrijk uitgangspunt om \(d\) zo dicht mogelijk bij λ/2 te houden.
16.13. Ruimtelijke Tapering¶
Ruimtelijke tapering is een techniek die je naast de conventionele bundelvormer gebruikt, waarbij je de amplitude van de gewichten aanpast om bepaalde eigenschappen te krijgen. Ook als je geen conventionele bundelvormer gebruikt, is het taperingconcept belangrijk om te begrijpen. Toen we de gewichten van de conventionele bundelvormer berekenden, waren dat complexe getallen met allemaal amplitude één (unity). Met ruimtelijke tapering vermenigvuldigen we de gewichten met scalaire factoren om die amplitude te schalen. Laten we beginnen met wat er gebeurt als we de gewichten met willekeurige waarden tussen 0 en 1 vermenigvuldigen:
tapering = np.random.uniform(0, 1, Nr) # willekeurige tapering
w *= tapering
We simuleren een signaal dat op kijkrichting (0 graden) wordt ontvangen bij hoge SNR om te zien wat er gebeurt. Merk op dat dit proces equivalent is aan het simuleren van het quiescent antenna pattern voor deze gewichten, en dus dezelfde resultaten geeft, zoals we aan het eind van dit hoofdstuk bespreken.
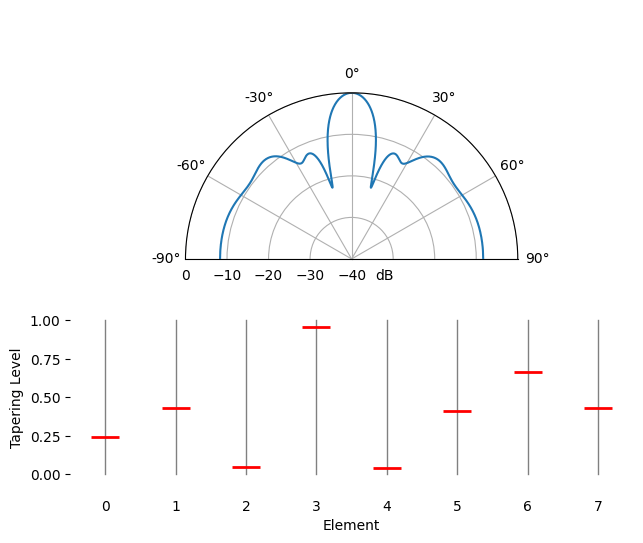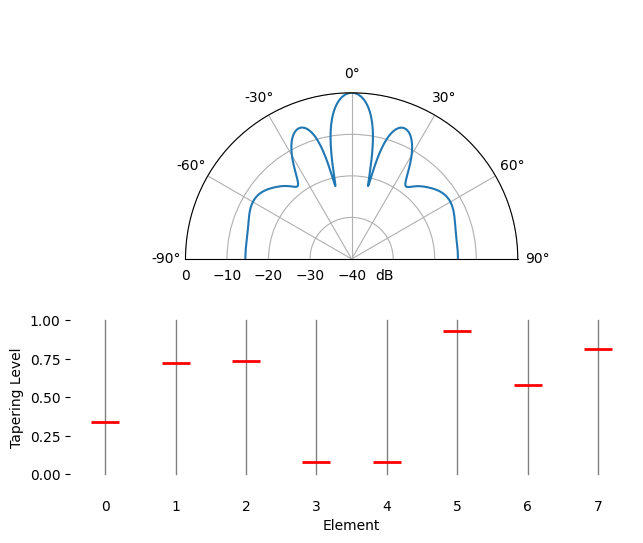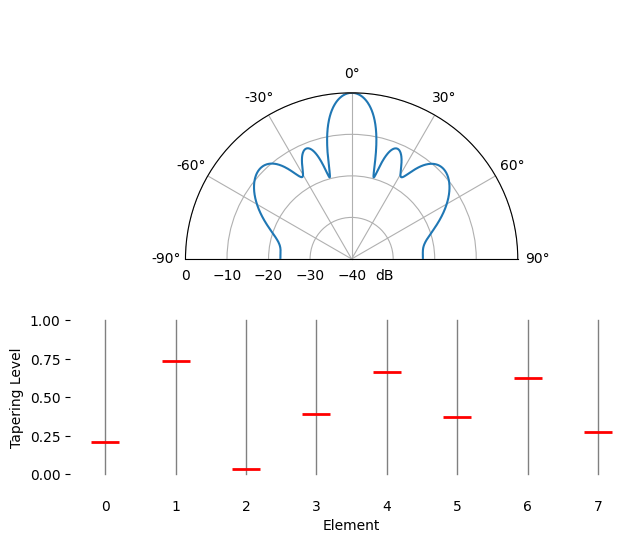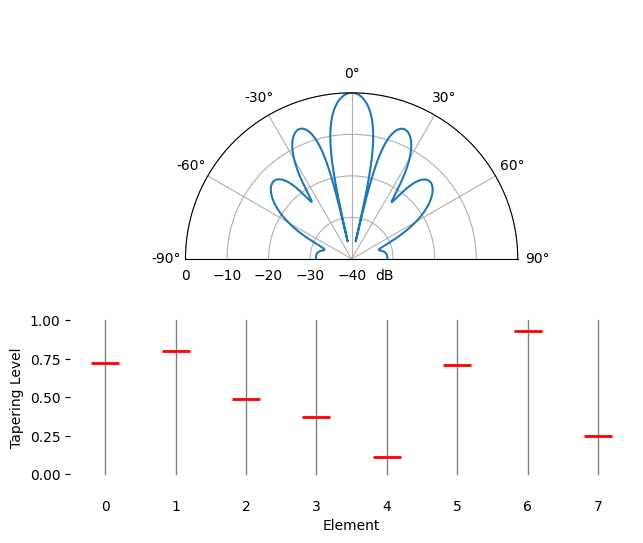
Probeer de breedte van de hoofdlob en de positie van de nullen te observeren.
Het blijkt dat tapering de zijlobben kan verlagen, wat vaak gewenst is, door de amplitude van de gewichten aan de randen van de array te verlagen. Een Hamming-venster kan bijvoorbeeld als taperingwaarden worden gebruikt:
tapering = np.hamming(Nr) # Hamming-vensterfunctie
w *= tapering
Voor de leuk laten we de taperingfunctie geleidelijk overgaan van een rechthoekvenster (geen venster) naar een Hamming-venster:
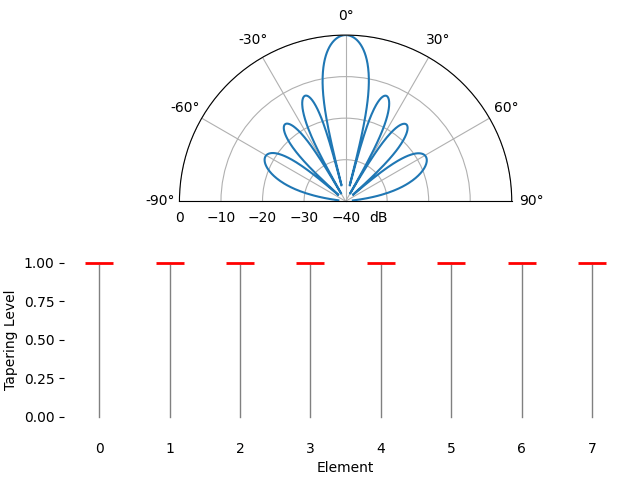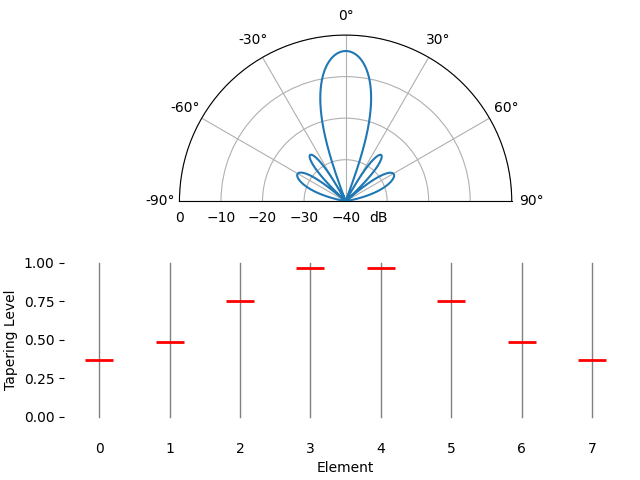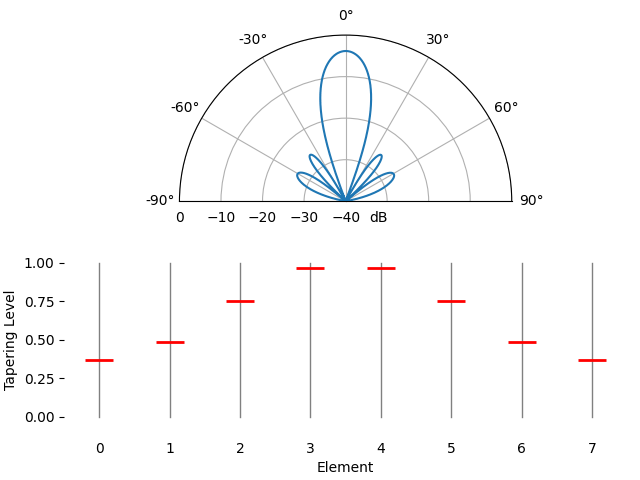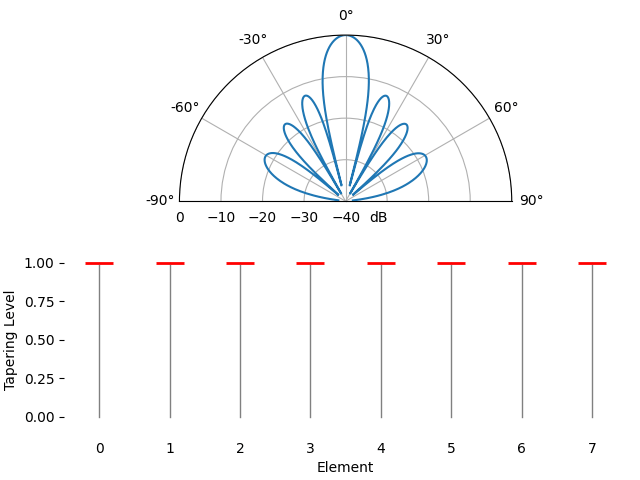
We zien hier een paar veranderingen. Ten eerste kan de hoofdlob breder of smaller worden afhankelijk van de taperingfunctie (minder zijlobben betekent meestal een bredere hoofdlob). Een rechthoekige taper (dus geen tapering) geeft de smalste hoofdlob, maar ook de hoogste zijlobben. Ten tweede zien we dat de gain van de hoofdlob afneemt wanneer we tapering toepassen. Dat komt doordat we uiteindelijk minder signaalenergie ontvangen doordat we niet de volledige gain van alle elementen gebruiken. Bij zeer lage SNR kan dat een belangrijk nadeel zijn.
Als je je afvraagt waarom er zoveel zijlobben zijn bij een rechthoekvenster (geen tapering): dat is dezelfde reden waarom een rechthoekvenster in het tijdsdomein tot spectrale lekkage in het frequentiedomein leidt. De Fourier-transformatie van een rechthoekvenster is een sinc-functie, \(sin(x)/x\), met zijlobben die oneindig doorlopen. Bij arrays samplen we in het ruimtelijke domein, en het bundelpatroon is de Fourier-transformatie van dat ruimtelijke sampleproces in combinatie met de gewichten. Daarom konden we eerder in dit hoofdstuk het bundelpatroon met een FFT plotten. In de sectie over vensterfuncties in het frequentiedomein hebben we de frequentierespons van venstertypen al vergeleken:

16.14. Gewichten Handmatig Aanpassen¶
De conventionele bundelvormer geeft ons een vergelijking om gewichten te berekenen voor een specifieke richting. Maar laten we nu even doen alsof we geen methode hebben en handmatig met de gewichten (zowel amplitude als fase) spelen om te zien wat er gebeurt. Hieronder staat een kleine JavaScript-app die het bundelpatroon van een 8-element-array simuleert, met sliders voor gain en fase per element. Je kunt tapering toevoegen, of minder dan 8 elementen simuleren door de amplitude van één of meer elementen op nul te zetten.
Element Magnitude (Gain) Phase
16.15. Adaptieve Bundelvorming¶
De conventionele bundelvormer die we eerder hebben besproken is een eenvoudige en effectieve manier om bundelvorming uit te voeren, maar hij heeft beperkingen. Hij werkt bijvoorbeeld minder goed wanneer meerdere signalen uit verschillende richtingen binnenkomen, of wanneer het ruisniveau hoog is. In zulke gevallen gebruiken we geavanceerdere technieken, vaak “adaptieve” bundelvorming genoemd. Het idee hierachter is dat we het ontvangen signaal gebruiken om de gewichten te berekenen, in plaats van een vaste set gewichten zoals bij conventionele bundelvorming. Daardoor kan de bundelvormer zich aanpassen aan de omgeving en beter presteren, omdat de gewichten nu op statistieken van de ontvangen data zijn gebaseerd.
Adaptieve bundelvormingstechnieken kun je verder opdelen in reguliere en subruimte-gebaseerde methoden. Subruimtemethoden zoals MUSIC en ESPRIT zijn erg krachtig, maar vereisen dat je schat hoeveel signalen aanwezig zijn. Daarnaast hebben ze minimaal drie elementen nodig om te werken (al is minimaal vier aanbevolen).
De eerste adaptieve bundelvormingstechniek die we bekijken is MVDR, vaak het de-facto-algoritme wanneer mensen over adaptieve bundelvorming praten.
16.16. MVDR/Capon-bundelvormer¶
We bekijken nu een bundelvormer die iets complexer is dan de conventionele/delay-and-sum-techniek, maar meestal veel beter presteert: de Minimum Variance Distortionless Response (MVDR), ook wel Capon-bundelvormer genoemd. Onthoud dat de variantie van een signaal overeenkomt met het vermogen in dat signaal. Het idee achter MVDR is om de versterking van het signaal in de gewenste richting 1 (0 dB) te houden, terwijl de totale variantie/het totale vermogen van het gebundelde signaal wordt geminimaliseerd. Als het gewenste signaal vast staat, betekent het minimaliseren van het totale vermogen dat interferentie en ruis zo veel mogelijk worden onderdrukt. Daarom wordt MVDR vaak een “statistisch optimale” bundelvormer genoemd.
De MVDR/Capon-bundelvormer kan worden samengevat met de volgende vergelijking:
De vector \(s\) is de stuurvector voor de gewenste richting en is aan het begin van dit hoofdstuk besproken. \(R\) is de geschatte ruimtelijke covariantiematrix op basis van onze ontvangen samples, te bepalen via R = np.cov(X) of handmatig met \(R = X X^H\), dus X vermenigvuldigd met zijn complex geconjugeerde getransponeerde. De ruimtelijke covariantiematrix heeft grootte Nr x Nr (3x3 in de voorbeelden tot nu toe) en geeft aan hoe sterk de samples van de elementen op elkaar lijken. De vergelijking kan in eerste instantie verwarrend zijn, maar de noemer dient vooral voor schaling. De teller is het belangrijkst: de inverse van de covariantiematrix vermenigvuldigd met de stuurvector. Toch moeten we de noemer wel meenemen, omdat die als normalisatieconstante werkt zodat de amplitude van de gewichten niet wegdrijft wanneer \(R\) in de tijd verandert.
Voor wie interesse heeft in de MVDR-afleiding: klap dit open
Uitgang van de bundelvormer - De uitgang van de bundelvormer met gewichtenvector \(\mathbf{w}\) is:
Optimalisatieprobleem - Het doel is om bundelvormingsgewichten te bepalen die het uitgangsvermogen minimaliseren, onder de voorwaarde van een distortionless respons in de gewenste richting \(\theta_0\). Formeel schrijven we dat als:
waarbij:
- \(\mathbf{R} = E[\mathbf{X}\mathbf{X}^H]\) de covariantiematrix van de ontvangen signalen is
- \(\mathbf{s}\) de stuurvector in de gewenste signaalrichting \(\theta_0\) is
Lagrangemethode - Introduceer een Lagrange-multiplier \(\lambda\) en vorm de Lagrangiaan:
Oplossen van de optimalisatie - Door de Lagrangiaan af te leiden naar \(\mathbf{w^H}\) en gelijk te stellen aan nul krijgen we:
Om \(\lambda\) op te lossen, passen we de randvoorwaarde \(\mathbf{w}^H \mathbf{s} = 1\) toe:
Als we de richting van het gewenste signaal al kennen en die richting niet verandert, hoeven we de gewichten maar één keer te berekenen en kunnen we die gebruiken om het signaal te ontvangen. Toch is periodiek herberekenen vaak nuttig, zelfs bij constante richting, om veranderingen in interferentie/ruis op te vangen. Daarom noemen we dit soort niet-conventionele digitale beamformers “adaptief”; ze gebruiken informatie uit het ontvangen signaal om betere gewichten te berekenen. Ter herinnering: we voeren bundelvorming met MVDR uit door deze gewichten te berekenen en toe te passen met w.conj().T @ X, net als bij de conventionele methode. Alleen de manier waarop de gewichten worden berekend verschilt.
Om DOA met de MVDR-bundelvormer uit te voeren, herhalen we eenvoudig de MVDR-berekening terwijl we alle relevante hoeken scannen. Met andere woorden: we doen alsof het signaal uit hoek \(\theta\) komt, ook als dat niet zo is. Per hoek berekenen we de MVDR-gewichten, passen die toe op het ontvangen signaal en berekenen vervolgens het signaalvermogen. De hoek met het hoogste vermogen is onze DOA-schatting. Nog beter is om vermogen als functie van hoek te plotten, zoals we eerder deden met de conventionele bundelvormer, zodat we niet vooraf hoeven aan te nemen hoeveel signalen aanwezig zijn.
In Python kunnen we de MVDR/Capon-bundelvormer als volgt implementeren, hier als functie zodat hij later makkelijk te hergebruiken is:
# theta is de gewenste richting in radialen, en X is het ontvangen signaal
def w_mvdr(theta, X):
s = np.exp(2j * np.pi * d * np.arange(Nr) * np.sin(theta)) # stuurvector in de gewenste richting theta
s = s.reshape(-1,1) # maak er een kolomvector van (grootte 3x1)
R = (X @ X.conj().T)/X.shape[1] # bereken covariantiematrix; dit geeft een Nr x Nr-matrix van de samples
Rinv = np.linalg.pinv(R) # 3x3. pseudo-inverse werkt meestal beter/sneller dan een echte inverse
w = (Rinv @ s)/(s.conj().T @ Rinv @ s) # MVDR/Capon-vergelijking; teller is 3x3 * 3x1, noemer is 1x3 * 3x3 * 3x1, resultaat is 3x1
return w
Als we deze MVDR-bundelvormer in DOA-context gebruiken, krijgen we het volgende Python-voorbeeld:
theta_scan = np.linspace(-1*np.pi, np.pi, 1000) # 1000 verschillende theta-waarden tussen -180 en +180 graden
results = []
for theta_i in theta_scan:
w = w_mvdr(theta_i, X) # 3x1
X_weighted = w.conj().T @ X # pas gewichten toe
power_dB = 10*np.log10(np.var(X_weighted)) # vermogen in dB, zodat kleine en grote lobben tegelijk zichtbaar zijn
results.append(power_dB)
results -= np.max(results) # normalize
Toegepast op de vorige DOA-simulatie krijgen we:

Dit lijkt goed te werken, maar om echt met andere technieken te vergelijken maken we een interessanter scenario. We zetten een simulatie op met een 8-element-array die drie signalen ontvangt vanuit verschillende hoeken: 20, 25 en 40 graden, waarbij het signaal op 40 graden met veel lager vermogen binnenkomt dan de andere twee. Ons doel is alle drie signalen te detecteren, dus we willen duidelijk zichtbare pieken hebben (hoog genoeg voor een piekzoekalgoritme). De code om dit scenario te genereren is:
Nr = 8 # 8 elementen
theta1 = 20 / 180 * np.pi # omzetten naar radialen
theta2 = 25 / 180 * np.pi
theta3 = -40 / 180 * np.pi
s1 = np.exp(2j * np.pi * d * np.arange(Nr) * np.sin(theta1)).reshape(-1,1) # 8x1
s2 = np.exp(2j * np.pi * d * np.arange(Nr) * np.sin(theta2)).reshape(-1,1)
s3 = np.exp(2j * np.pi * d * np.arange(Nr) * np.sin(theta3)).reshape(-1,1)
# we gebruiken 3 verschillende frequenties. 1xN
tone1 = np.exp(2j*np.pi*0.01e6*t).reshape(1,-1)
tone2 = np.exp(2j*np.pi*0.02e6*t).reshape(1,-1)
tone3 = np.exp(2j*np.pi*0.03e6*t).reshape(1,-1)
X = s1 @ tone1 + s2 @ tone2 + 0.1 * s3 @ tone3 # let op: de laatste heeft 1/10 van het vermogen
n = np.random.randn(Nr, N) + 1j*np.random.randn(Nr, N)
X = X + 0.05*n # 8xN
Je kunt deze code bovenaan je script plaatsen, omdat we hier een ander signaal genereren dan in het oorspronkelijke voorbeeld. Als we in dit scenario de MVDR-bundelvormer draaien, krijgen we:

Dit werkt vrij goed: we zien twee signalen die slechts 5 graden uit elkaar liggen, en ook het derde signaal (op -40 of 320 graden) dat met een tiende van het vermogen van de andere binnenkomt. Laten we nu in hetzelfde scenario de conventionele bundelvormer draaien:
Hoewel het er visueel mooi uitziet, vindt deze methode duidelijk niet alle drie de signalen. Door deze twee resultaten te vergelijken zie je het voordeel van een complexere en “adaptieve” bundelvormer.
Als korte zijstap voor geïnteresseerden: er is een optimalisatie mogelijk bij DOA met MVDR. Onthoud dat we signaalvermogen berekenen via de variantie, oftewel het gemiddelde van de magnitude in het kwadraat (aangenomen dat het gemiddelde van het signaal ongeveer nul is, wat bij basisband-RF vrijwel altijd zo is). Het vermogen na toepassen van de gewichten kunnen we schrijven als:
Als we overstappen van een sommatie naar de verwachtingsoperator, en de vergelijking voor MVDR-gewichten invullen, krijgen we:
Dit betekent dat we de gewichten niet expliciet hoeven toe te passen; de laatste vermogensvergelijking hierboven kan direct in de DOA-scan worden gebruikt en bespaart rekenwerk:
def power_mvdr(theta, X):
s = np.exp(2j * np.pi * d * np.arange(r.shape[0]) * np.sin(theta)) # stuurvector in de gewenste richting theta_i
s = s.reshape(-1,1) # maak er een kolomvector van (grootte 3x1)
R = (X @ X.conj().T)/X.shape[1] # bereken covariantiematrix; dit geeft een Nr x Nr-matrix van de samples
Rinv = np.linalg.pinv(R) # 3x3. pseudo-inverse werkt meestal beter dan een echte inverse
return 1/(s.conj().T @ Rinv @ s).squeeze()
Om dit in de vorige simulatie te gebruiken hoef je in de for-loop alleen nog 10*np.log10() toe te passen; er zijn geen gewichten meer om toe te passen, want die berekening hebben we overgeslagen.
Er bestaan nog veel meer beamformers, maar hierna staan we eerst kort stil bij hoe het aantal elementen invloed heeft op bundelvorming en DOA.
16.17. Covariantiematrix¶
Laten we kort de ruimtelijke covariantiematrix bespreken, een kernbegrip in adaptieve bundelvorming. Een covariantiematrix is een wiskundige representatie van de overeenkomst tussen paren elementen in een willekeurige vector (in ons geval de array-elementen, daarom noemen we dit de ruimtelijke covariantiematrix). Een covariantiematrix is altijd vierkant, en de waarden op de diagonaal zijn de covariantie van elk element met zichzelf. We berekenen in de praktijk een schatting van de ruimtelijke covariantiematrix, omdat we maar een beperkt aantal samples hebben.
In het algemeen is de covariantiematrix gedefinieerd als:
\(\mathrm{cov}(X) = E \left[ (X - E[X])(X - E[X])^H \right]\)
voor draadloze basisbandsignalen is \(E[X]\) meestal nul of bijna nul, dus dit vereenvoudigt tot:
\(\mathrm{cov}(X) = E[X X^H]\)
Met een beperkt aantal IQ-samples, \(\boldsymbol{X}\), kunnen we deze covariantie schatten. We noteren die als \(\hat{R}\):
waar \(N\) het aantal samples is (niet het aantal elementen). In Python ziet dat er zo uit:
R = (X @ X.conj().T)/X.shape[1]
Als alternatief kunnen we de ingebouwde NumPy-functie gebruiken:
R = np.cov(X)
Als voorbeeld bekijken we de ruimtelijke covariantiematrix voor het scenario met één zender en drie elementen:
[[ 1.494+0.j 0.486+0.881j -0.543+0.839j]
[ 0.486-0.881j 1.517 +0.j 0.483+0.886j]
[-0.543-0.839j 0.483-0.886j 1.499+0.j ]]
Let op dat de diagonale elementen reëel zijn en ongeveer gelijk. Dat komt doordat ze vooral het ontvangen signaalvermogen per element weergeven, en dat is vergelijkbaar omdat alle elementen dezelfde gain hebben. De off-diagonale elementen bevatten de meest relevante informatie, al zie je uit de ruwe waarden vooral dat er duidelijke correlatie tussen elementen aanwezig is.
Als onderdeel van adaptieve bundelvorming zie je vaak dat we de inverse van de ruimtelijke correlatiematrix nemen. Die inverse vertelt hoe twee elementen zich tot elkaar verhouden nadat de invloed van de andere elementen is verwijderd. In statistiek heet dit de “precision matrix” en in radar de “whitening matrix”.
16.18. LCMV-bundelvormer¶
Hoewel MVDR krachtig is, wat als we meer dan één SOI hebben? Met een kleine aanpassing op MVDR kunnen we gelukkig een schema bouwen dat meerdere SOI’s aankan: de Linearly Constrained Minimum Variance (LCMV)-bundelvormer. Dit is een generalisatie van MVDR waarbij we de gewenste respons voor meerdere richtingen specificeren, een beetje als een ruimtelijke variant van SciPy’s firwin2() voor wie dat kent. De optimale gewichtenvector voor de LCMV-bundelvormer is samen te vatten als:
waar \(C\) een matrix is met stuurvectoren van de bijbehorende SOI’s en stoorzenders, en \(f\) de gewenste responsvector is. Voor een bepaalde rij krijgt \(f\) de waarde 0 als de bijbehorende stuurvector onderdrukt moet worden (null), en 1 als we er een bundel op willen richten. Hebben we bijvoorbeeld twee gewenste bronnen en twee interferentiebronnen, dan kunnen we f = [1,1,0,0] kiezen. De LCMV-bundelvormer is een krachtig hulpmiddel om interferentie en ruis uit meerdere richtingen te onderdrukken en tegelijk gewenste signalen uit meerdere richtingen te versterken. De keerzijde is dat het totale aantal nullen en bundels dat je tegelijk kunt vormen beperkt is door de arraygrootte (het aantal elementen). Daarnaast moet je voor elke SOI en interferer een stuurvector opstellen, wat in de praktijk niet altijd eenvoudig beschikbaar is. Als je schattingen gebruikt, kan de prestatie van de LCMV-bundelvormer dalen. Daarom sturen we nullen liever met de ruimtelijke covariantiematrix \(R\) (gebaseerd op statistiek van het ontvangen signaal), in plaats van nullen te “hardcoden” door de AoA van een interferer te schatten en daar een stuurvector voor te bouwen met een 0 in \(f\).
LCMV uitvoeren in Python lijkt sterk op MVDR, maar we moeten C opgeven (mogelijk samengesteld uit meerdere stuurvectoren) en f als 1D-array met 1’en en 0’en zoals hierboven beschreven. De volgende code laat zien hoe je de LCMV-bundelvormer implementeert voor twee SOI’s (15 en 60 graden). Onthoud dat MVDR maar één SOI tegelijk ondersteunt. Daarom is hier f = [1; 1] zonder nullen, omdat we geen “hardcoded” nullen opnemen. We simuleren een scenario met vier stoorzenders op -60, -30, 0 en 30 graden.
# Richt op de SOI bij 15 graden en nog een potentiële SOI op 60 graden die we niet hebben gesimuleerd
soi1_theta = 15 / 180 * np.pi # omzetten naar radialen
soi2_theta = 60 / 180 * np.pi
# LCMV-gewichten
R_inv = np.linalg.pinv(np.cov(X)) # 8x8
s1 = np.exp(2j * np.pi * d * np.arange(Nr) * np.sin(soi1_theta)).reshape(-1,1) # 8x1
s2 = np.exp(2j * np.pi * d * np.arange(Nr) * np.sin(soi2_theta)).reshape(-1,1) # 8x1
C = np.concatenate((s1, s2), axis=1) # 8x2
f = np.ones(2).reshape(-1,1) # 2x1
# LCMV-vergelijking
# 8x8 8x2 2x8 8x8 8x2 2x1
w = R_inv @ C @ np.linalg.pinv(C.conj().T @ R_inv @ C) @ f # output is 8x1
We kunnen het bundelpatroon van w plotten met de FFT-methode van eerder:

Zoals je ziet hebben we bundels naar de twee gewenste richtingen en nullen op de locaties van de stoorzenders (net als bij MVDR hoeven we niet expliciet te zeggen waar de zenders zitten; dat volgt uit het ontvangen signaal). Groene en rode punten in de plot geven respectievelijk de AoA’s van SOI’s en stoorzenders aan.
Klap dit open voor de volledige code
# Simuleer ontvangen signaal
Nr = 8 # 8 elementen
theta1 = -60 / 180 * np.pi # omzetten naar radialen
theta2 = -30 / 180 * np.pi
theta3 = 0 / 180 * np.pi
theta4 = 30 / 180 * np.pi
s1 = np.exp(2j * np.pi * d * np.arange(Nr) * np.sin(theta1)).reshape(-1,1) # 8x1
s2 = np.exp(2j * np.pi * d * np.arange(Nr) * np.sin(theta2)).reshape(-1,1)
s3 = np.exp(2j * np.pi * d * np.arange(Nr) * np.sin(theta3)).reshape(-1,1)
s4 = np.exp(2j * np.pi * d * np.arange(Nr) * np.sin(theta4)).reshape(-1,1)
# we gebruiken 3 verschillende frequenties. 1xN
tone1 = np.exp(2j*np.pi*0.01e6*t).reshape(1,-1)
tone2 = np.exp(2j*np.pi*0.02e6*t).reshape(1,-1)
tone3 = np.exp(2j*np.pi*0.03e6*t).reshape(1,-1)
tone4 = np.exp(2j*np.pi*0.04e6*t).reshape(1,-1)
X = s1 @ tone1 + s2 @ tone2 + s3 @ tone3 + s4 @ tone4
n = np.random.randn(Nr, N) + 1j*np.random.randn(Nr, N)
X = X + 0.5*n # 8xN
# Richt op de SOI bij 15 graden en nog een potentiële SOI op 60 graden die we niet hebben gesimuleerd
soi1_theta = 15 / 180 * np.pi # omzetten naar radialen
soi2_theta = 60 / 180 * np.pi
# LCMV-gewichten
R_inv = np.linalg.pinv(np.cov(X)) # 8x8
s1 = np.exp(2j * np.pi * d * np.arange(Nr) * np.sin(soi1_theta)).reshape(-1,1) # 8x1
s2 = np.exp(2j * np.pi * d * np.arange(Nr) * np.sin(soi2_theta)).reshape(-1,1) # 8x1
C = np.concatenate((s1, s2), axis=1) # 8x2
f = np.ones(2).reshape(-1,1) # 2x1
# LCMV-vergelijking
# 8x8 8x2 2x8 8x8 8x2 2x1
w = R_inv @ C @ np.linalg.pinv(C.conj().T @ R_inv @ C) @ f # output is 8x1
# Plot bundelpatroon
w = w.squeeze() # reduceer naar een 1D-array
N_fft = 1024
w_padded = np.concatenate((w, np.zeros(N_fft - Nr))) # zero-pad naar N_fft elementen voor meer FFT-resolutie
w_fft_dB = 10*np.log10(np.abs(np.fft.fftshift(np.fft.fft(w_padded)))**2) # FFT-magnitude in dB
w_fft_dB -= np.max(w_fft_dB) # normalize to 0 dB at peak
theta_bins = np.arcsin(np.linspace(-1, 1, N_fft)) # map FFT-bins naar hoeken in radialen
fig, ax = plt.subplots(subplot_kw={'projection': 'polar'})
ax.plot(theta_bins, w_fft_dB) # GEBRUIK RADIALEN VOOR EEN POOLPLOT
# Voeg punten toe op de locaties van stoorzenders en SOI's
ax.plot([theta1], [0], 'or')
ax.plot([theta2], [0], 'or')
ax.plot([theta3], [0], 'or')
ax.plot([theta4], [0], 'or')
ax.plot([soi1_theta], [0], 'og')
ax.plot([soi2_theta], [0], 'og')
ax.set_theta_zero_location('N') # laat 0 graden omhoog wijzen
ax.set_theta_direction(-1) # laat de hoek met de klok mee toenemen
ax.set_thetagrids(np.arange(-90, 105, 15)) # dit is in graden
ax.set_rlabel_position(55) # verplaats rasterlabels weg van andere labels
ax.set_thetamin(-90) # toon alleen de bovenste helft
ax.set_thetamax(90)
ax.set_ylim([-30, 1]) # zonder ruis hoeven we maar tot -30 dB te gaan
plt.show()
Er is een interessante toepassing van LCMV waar je misschien al aan dacht: stel dat je de hoofdbundel niet exact op 20 graden wilt richten, maar juist breder wilt maken dan conventionele bundelvorming normaal oplevert. Dat kan door de gewenste responsvector f op 1 te zetten voor een hoekbereik (bijvoorbeeld meerdere waarden tussen 10 en 30 graden) en daarbuiten op 0. Daarmee kun je een bundelpatroon maken dat breder is dan de hoofdlob van de conventionele bundelvormer, wat handig is in praktijksituaties waar de exacte aankomstrichting niet bekend is. Je kunt dezelfde aanpak ook gebruiken om een null over een breder hoekbereik te maken. Houd er wel rekening mee dat dit meerdere vrijheidsgraden kost. Als voorbeeld simuleren we een 18-element-array, met een interessehoek van 15 tot 30 graden via 4 verschillende theta’s, en een null van 45 tot 60 graden ook met 4 theta’s. We simuleren hier geen echte stoorzenders.
Nr = 18
X = np.random.randn(Nr, N) + 1j*np.random.randn(Nr, N) # simuleer ontvangen signaal met alleen ruis
# Richt op de SOI van 15 tot 30 graden met 4 verschillende theta's
soi_thetas = np.linspace(15, 30, 4) / 180 * np.pi # omzetten naar radialen
# Maak een null van 45 tot 60 graden met 4 verschillende theta's
null_thetas = np.linspace(45, 60, 4) / 180 * np.pi # omzetten naar radialen
# LCMV-gewichten
R_inv = np.linalg.pinv(np.cov(X))
s = []
for soi_theta in soi_thetas:
s.append(np.exp(2j * np.pi * d * np.arange(Nr) * np.sin(soi_theta)).reshape(-1,1))
for null_theta in null_thetas:
s.append(np.exp(2j * np.pi * d * np.arange(Nr) * np.sin(null_theta)).reshape(-1,1))
C = np.concatenate(s, axis=1)
f = np.asarray([1]*len(soi_thetas) + [0]*len(null_thetas)).reshape(-1,1)
w = R_inv @ C @ np.linalg.pinv(C.conj().T @ R_inv @ C) @ f # LCMV-vergelijking
# Plot bundelpatroon zoals eerder...

De bundel en null zijn nu uitgespreid over het gevraagde bereik. Probeer het aantal theta’s voor de hoofdbundel en/of null te wijzigen, en ook het aantal elementen, om te zien of de resulterende gewichten de gewenste respons nog kunnen realiseren.
16.19. Nullsturing¶
Nu we LCMV hebben gezien, is het de moeite waard om een eenvoudigere techniek te bekijken die zowel in analoge als digitale arrays kan worden gebruikt: null steering. Zie het als een uitbreiding op de conventionele bundelvormer: naast een bundel naar de gewenste richting kun je ook nullen op specifieke hoeken plaatsen. Deze techniek past gewichten niet aan op basis van het ontvangen signaal (we berekenen bijvoorbeeld geen R) en wordt dus niet als adaptief beschouwd. In de simulatie hieronder hoeven we zelfs geen signaal te simuleren; we construeren alleen de gewichten met null steering en visualiseren vervolgens het bundelpatroon.
De gewichten voor null steering bereken je door te starten met de conventionele bundelvormer op de interessehoek, en daarna met de sidelobe-canceler-vergelijking de gewichten bij te werken zodat nullen worden toegevoegd, één voor één. De sidelobe-canceler-vergelijking is:
waar \(w_{\text{null}}\) de stuurvector is in de richting van de null die we aan \(w_{\text{orig}}\) willen toevoegen. De gewichten worden bijgewerkt door de geschaalde null-stuurvector van de huidige gewichten af te trekken. De schaalfactor volgt uit projectie van de huidige gewichten op de null-stuurvector, gedeeld door de projectie van die null-stuurvector op zichzelf. Dit herhaal je voor elke null-richting (\(w_{\text{orig}}\) begint als conventionele bundelvormingsgewichten en wordt na elke null bijgewerkt). Het volledige proces:
Laten we een 8-element-array simuleren en vier nullen plaatsen:
d = 0.5
Nr = 8
theta_soi = 30 / 180 * np.pi # omzetten naar radialen
nulls_deg = [-60, -30, 0, 60] # graden
nulls_rad = np.asarray(nulls_deg) / 180 * np.pi
# Start met een conventionele beamformer gericht op theta_soi
w = np.exp(2j * np.pi * d * np.arange(Nr) * np.sin(theta_soi)).reshape(-1,1)
# Loop over de nullen
for null_rad in nulls_rad:
# gewichten gelijk aan stuurvector in de gewenste null-richting
w_null = np.exp(2j * np.pi * d * np.arange(Nr) * np.sin(null_rad)).reshape(-1,1)
# scaling_factor (complex scalar) voor w in de genulde richting
scaling_factor = w_null.conj().T @ w / (w_null.conj().T @ w_null)
print("scaling_factor:", scaling_factor, scaling_factor.shape)
# Werk gewichten bij om de null toe te voegen
w = w - w_null @ scaling_factor # sidelobe-canceler equation
# Plot bundelpatroon
N_fft = 1024
w_padded = np.concatenate((w.squeeze(), np.zeros(N_fft - Nr))) # zero-pad naar N_fft elementen voor meer FFT-resolutie
w_fft_dB = 10*np.log10(np.abs(np.fft.fftshift(np.fft.fft(w_padded)))**2) # FFT-magnitude in dB
w_fft_dB -= np.max(w_fft_dB) # normalize to 0 dB at peak
theta_bins = np.arcsin(np.linspace(-1, 1, N_fft)) # map FFT-bins naar hoeken in radialen
fig, ax = plt.subplots(subplot_kw={'projection': 'polar'})
ax.plot(theta_bins, w_fft_dB)
# Voeg punten toe op de locaties van nullen en SOI
for null_rad in nulls_rad:
ax.plot([null_rad], [0], 'or')
ax.plot([theta_soi], [0], 'og')
ax.set_theta_zero_location('N') # laat 0 graden omhoog wijzen
ax.set_theta_direction(-1) # laat de hoek met de klok mee toenemen
ax.set_thetagrids(np.arange(-90, 105, 15)) # dit is in graden
ax.set_rlabel_position(55) # verplaats rasterlabels weg van andere labels
ax.set_thetamin(-90) # toon alleen de bovenste helft
ax.set_thetamax(90)
ax.set_ylim([-40, 1]) # zonder ruis hoeven we maar tot -40 dB te gaan
plt.show()
We krijgen het volgende bundelpatroon. Je ziet mogelijk nullen op posities die je niet expliciet hebt gevraagd; dat is verwacht gedrag en komt door het beperkte aantal elementen. Bij te weinig elementen kan het ook zijn dat nullen/bundel niet exact op de bedoelde plek liggen, of dat de criteria helemaal niet haalbaar zijn door een gebrek aan vrijheidsgraden (aantal elementen min 1).

16.20. MUSIC¶
We schakelen nu over naar een ander type bundelvormer. Alle eerdere methoden vielen in de “delay-and-sum”-categorie, maar nu duiken we in subruimtemethoden. Daarbij splitsen we in een signaal-subruimte en een ruis-subruimte, wat betekent dat we eerst moeten schatten hoeveel signalen de array ontvangt. MUltiple SIgnal Classification (MUSIC) is een populaire subruimtemethode die eigenvectoren van de covariantiematrix gebruikt (een rekenintensieve operatie). We splitsen de eigenvectoren in twee groepen: signaal-subruimte en ruis-subruimte, en projecteren daarna stuurvectoren in de ruis-subruimte om nullen te sturen. Dat klinkt in het begin verwarrend, wat mede verklaart waarom MUSIC soms als zwarte magie voelt.
De kernvergelijking van MUSIC is:
waar \(V_n\) de lijst is met eigenvectoren van de ruis-subruimte (een 2D-matrix). Die krijg je door eerst de eigenvectoren van \(R\) te berekenen, in Python simpel met w, v = np.linalg.eig(R), en daarna de vectoren te splitsen op basis van hoeveel signalen we denken dat de array ontvangt. Er is een truc om het aantal signalen te schatten, die komt later, maar het moet tussen 1 en Nr - 1 liggen. Ontwerp je een array, dan moet het aantal elementen dus minstens één hoger zijn dan het verwachte aantal signalen. Belangrijk detail: in de vergelijking hierboven hangt \(V_n\) niet af van stuurvector \(s\), dus \(V_n\) kunnen we vooraf berekenen voordat we over theta loopen. De volledige MUSIC-code:
num_expected_signals = 3 # Probeer dit te veranderen!
# deel dat niet verandert met theta_i
R = np.cov(X) # bereken covariantiematrix; dit geeft een Nr x Nr-matrix
w, v = np.linalg.eig(R) # eigenwaarde-ontbinding, v[:,i] is de eigenvector bij eigenwaarde w[i]
eig_val_order = np.argsort(np.abs(w)) # bepaal volgorde op grootte van eigenwaarden
v = v[:, eig_val_order] # sorteer eigenvectoren volgens die volgorde
# maak een nieuwe eigenvectormatrix voor de "ruis-subruimte"; dit zijn de overblijvende eigenwaarden
V = np.zeros((Nr, Nr - num_expected_signals), dtype=np.complex64)
for i in range(Nr - num_expected_signals):
V[:, i] = v[:, i]
theta_scan = np.linspace(-1*np.pi, np.pi, 1000) # -180 tot +180 graden
results = []
for theta_i in theta_scan:
s = np.exp(2j * np.pi * d * np.arange(Nr) * np.sin(theta_i)) # stuurvector
s = s.reshape(-1,1)
metric = 1 / (s.conj().T @ V @ V.conj().T @ s) # de hoofdvergelijking van MUSIC
metric = np.abs(metric.squeeze()) # neem de magnitude
metric = 10*np.log10(metric) # converteer naar dB
results.append(metric)
results /= np.max(results) # normalize
Als we dit algoritme op het complexe scenario van hierboven toepassen, krijgen we zeer precieze resultaten, wat de kracht van MUSIC laat zien:

Wat als we geen idee hebben hoeveel signalen aanwezig zijn? Daar is een truc voor: sorteer de magnitudes van de eigenwaarden van hoog naar laag en plot ze (in dB plotten helpt vaak):
plot(10*np.log10(np.abs(w)),'.-')

De eigenwaarden die bij de ruis-subruimte horen zijn het kleinst en clusteren rond ongeveer dezelfde waarde. Je kunt deze lage waarden dus als “ruisvloer” zien, en elke eigenwaarde erboven komt overeen met een signaal. Hier zien we duidelijk dat er drie signalen worden ontvangen, en kunnen we het MUSIC-algoritme daarop afstemmen. Heb je weinig IQ-samples of lage SNR, dan is het aantal signalen minder duidelijk. Speel gerust met num_expected_signals tussen 1 en 7; onderschatting zorgt voor gemiste signalen, overschatting schaadt de prestatie meestal maar beperkt.
Nog een interessant experiment met MUSIC is kijken hoe dicht twee signalen qua hoek bij elkaar kunnen liggen terwijl je ze nog kunt onderscheiden; subruimtetechnieken zijn hier juist erg goed in. De animatie hieronder laat een voorbeeld zien, met één signaal op 18 graden en een tweede waarvan de aankomstrichting langzaam sweept.
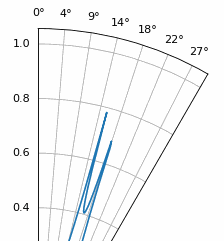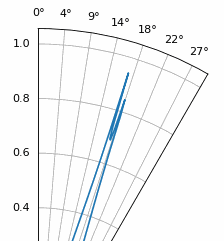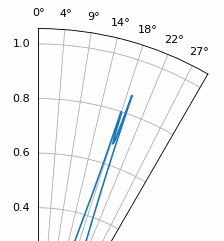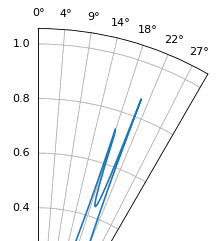
16.21. Root MUSIC¶
Alle DOA-technieken die we tot nu toe hebben behandeld, inclusief conventionele bundelvorming, MVDR en MUSIC zelf, werken door over een raster met kandidaat-hoeken te sweepen en per hoek een metric te berekenen (vaak parallel). Root MUSIC elimineert die scan volledig. In plaats van pieken in een spectrum te zoeken, bepaalt het de signaalrichtingen analytisch door de wortels van een polynoom op te lossen. Daardoor kan Root MUSIC zowel sneller als nauwkeuriger zijn dan spectrale MUSIC, omdat de piekpositie niet langer beperkt is door de hoekresolutie van je scanraster. Een beperking is dat Root MUSIC alleen direct werkt voor een ULA. Voor 2D-arrays of niet-ULA 1D-arrays bestaan varianten/uitbreidingen, maar die zijn veel complexer. Net als bij MUSIC hebben we nog steeds num_expected_signals nodig, wat je ook als beperking kunt zien.
Root MUSIC benut het feit dat de stuurvector van een ULA een nette Vandermonde-structuur heeft: een vector (of matrix) waarin elke rij bestaat uit opeenvolgende machten van een basiswaarde, bijvoorbeeld [1, x, x^2, x^3, ..., x^(n-1)]. Bij halve-golflengteafstand zijn de stuurvectorelementen gewoon opeenvolgende machten van één complex getal \(z = e^{j\pi\sin\theta}\), zoals we aan het begin van dit hoofdstuk hebben gezien.
Voor Root MUSIC bouwen we een polynoom op uit de projectiematrix van de ruis-subruimte. We gebruiken dezelfde MUSIC-kostfunctie als in de vorige sectie, maar nu in de vorm:
waar \(V_n\) de ruis-subruimtematrix is uit de eigenwaarde-ontbinding van de covariantiematrix \(R\), net als bij MUSIC. Als je dit product uitwerkt, krijg je een polynoom van graad \(2(N_r-1)\). Op punten waar \(P(z)\) een wortel op de eenheidscirkel \(|z|=1\) heeft, zou de MUSIC-kostfunctie oneindig worden; dat zijn dus signaalrichtingen. In de praktijk, met een eindig aantal samples, vallen wortels niet exact op de eenheidscirkel maar clusteren er dichtbij. Daarom kiezen we de \(D\) wortels (waar \(D\) het aantal verwachte signalen is) die het dichtst bij de eenheidscirkel liggen.
De polynoomcoefficienten worden opgebouwd door de diagonalen van de projectiematrix van de ruis-subruimte \(D = V_n V_n^H\) op te tellen:
oftewel de som over de \((k-(N_r-1))\)-de diagonaal van \(D\). Zodra we het polynoom \(P(z) = p_0 + p_1 z + \cdots + p_{2(N_r-1)} z^{2(N_r-1)}\) hebben, bepalen we numeriek de wortels en zetten we de signaalwortels terug om naar hoeken:
De volledige Root MUSIC-code, met hetzelfde ontvangen signaal X en dezelfde parameters als in het MUSIC-voorbeeld, is:
num_expected_signals = 3
# Zelfde eigenwaarde-ontbinding als bij MUSIC
R = np.cov(X)
w, v = np.linalg.eig(R)
eig_val_order = np.argsort(np.abs(w))
v = v[:, eig_val_order]
V = v[:, :Nr - num_expected_signals] # eigenvectoren van ruis-subruimte
# Bouw het Root MUSIC-polynoom op uit diagonalen van de ruis-subruimteprojectie
D = V @ V.conj().T
p = np.zeros(2*Nr - 1, dtype=np.complex128)
for k in range(2*Nr - 1):
p[k] = np.sum(np.diag(D, k - (Nr - 1)))
# Vind wortels, houd die binnen de eenheidscirkel, kies de num_expected_signals
# wortels die het dichtst bij de eenheidscirkel liggen
roots = np.roots(p[::-1]) # np.roots verwacht hoogste-graadscoefficient eerst
roots = roots[np.abs(roots) <= 1.0] # verwijder de conjugaat-reciproke partners die dezelfde DOA opleveren
roots = roots[np.argsort(-np.abs(roots))] # sorteer: dichtst bij eenheidscirkel eerst
doa_roots = roots[:num_expected_signals]
# Zet wortels om naar hoeken in graden
doas_deg = np.sort(np.arcsin(np.angle(doa_roots) / (2 * np.pi * d)) * 180 / np.pi)
print("Estimated DOAs (degrees):", doas_deg)
Het meeste rekenwerk wordt hier gedaan door NumPy’s np.roots()-functie, die de companion-matrixmethode gebruikt om de polynoomwortels te vinden.
Als je dit op hetzelfde drie-signalen-scenario uitvoert, krijg je vrij nauwkeurige hoekschattingen, zonder sweep, resolutiestap of piekzoekalgoritme:
Estimated DOAs (degrees): [-39.98674197 19.99724883 25.00387589]
True DOAs (degrees): [-40. 20. 25.]
Vergelijk dat met spectrale MUSIC, waarvoor een theta-sweep van duizend punten nodig was om dezelfde drie pieken te vinden. De nauwkeurigheid van Root MUSIC wordt in essentie begrensd door de covariantiematrixschatting, niet door een gekozen roosterstap. De rekenwinst valt vooral op bij grote Nr, omdat een polynoom van graad \(2(N_r-1)\) opbouwen en oplossen veel goedkoper is dan de MUSIC-vergelijking over duizenden stuurhoeken evalueren.
Een belangrijk punt: Root MUSIC erft dezelfde eisen als MUSIC. Je moet nog steeds het aantal signalen kennen (of schatten), en je hebt genoeg elementen nodig zodat \(N_r > D\). De eigenwaarde-plottruc uit de MUSIC-sectie werkt hier net zo goed om eerst het aantal signalen te schatten.
16.22. LMS¶
De Least Mean Squares (LMS)-bundelvormer is een bundelvormer met lage complexiteit, geïntroduceerd door Bernard Widrow. Deze verschilt op twee punten van de bundelvormers die we eerder zagen: 1) je moet de SOI kennen, of ten minste een deel ervan (bijv. synchronisatiereeks, pilots, enz.), en 2) hij is iteratief, dus de gewichten worden in meerdere iteraties aangescherpt. LMS werkt door de gemiddelde kwadratische fout te minimaliseren tussen het gewenste signaal (SOI) en de uitgang van de bundelvormer (dus gewichten toegepast op ontvangen samples). In de klassieke implementatie is elk ontvangen sample de volgende iteratiestap: pas huidige gewichten toe op één sample, bereken fout, en gebruik die fout om gewichten bij te sturen. Daarna herhaal je dit. De LMS-bundelvormer is toepasbaar in zowel analoge als digitale bundelvorming. Het LMS-algoritme:
waar \(w_n\) de gewichtenvector is bij iteratie/sample \(n\), \(\mu\) de stapgrootte is, \(x_n\) het ontvangen sample op \(n\), \(y_n\) de verwachte waarde in die iteratie (de bekende SOI), en \(*\) de complex geconjugeerde is. Laat \(w_{n}^H x_n\) de vergelijking niet ingewikkelder laten lijken dan nodig: dat is simpelweg het toepassen van de huidige gewichten op het ingangssignaal, oftewel standaard bundelvorming. De stapgrootte \(\mu\) bepaalt hoe snel de gewichten convergeren naar optimale waarden. Een kleine \(\mu\) geeft trage convergentie (je haalt mogelijk de beste gewichten niet voordat het bekende signaal weg is), terwijl een grote \(\mu\) instabiliteit kan veroorzaken. LMS is krachtig voor adaptieve bundelvorming, maar heeft beperkingen: je hebt een bekende SOI nodig, en tijd- en frequentiesynchronisatie maken onderdeel uit van het LMS-proces zodat je SOI-referentie is uitgelijnd met de ontvangen samples.
In het Python-voorbeeld hieronder simuleren we een 8-element-array met een SOI die bestaat uit een herhaalde Gold-code, gemoduleerd als BPSK. Gold-codes worden gebruikt in 5G en GPS en hebben uitstekende kruiscorrelatie-eigenschappen, waardoor ze goed zijn als synchronisatiesignaal. In de simulatie nemen we ook twee toon-stoorzenders op, op 60 en -50 graden. Let op: deze simulatie bevat geen tijd- of frequentieverschuiving; anders zouden we SOI-synchronisatie in het LMS-proces moeten opnemen (dus gecombineerde bundelvorming en synchronisatie). In de animatie hieronder sweepen we de AoA van de SOI en plotten we het bundelpatroon dat LMS na 10k samples oplevert. Je ziet dat LMS de gain richting de SOI op exact 0 dB houdt (tenzij er een interferer precies bovenop zit), terwijl nullen naar de stoorzenders worden gezet.
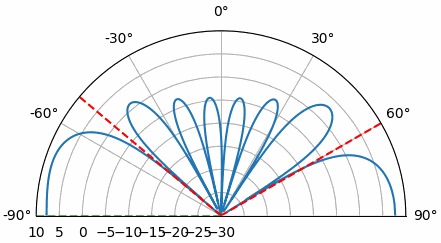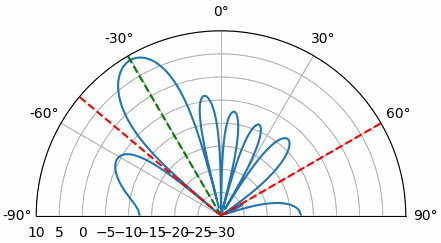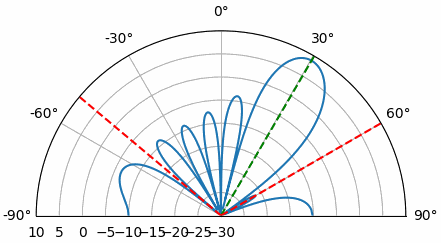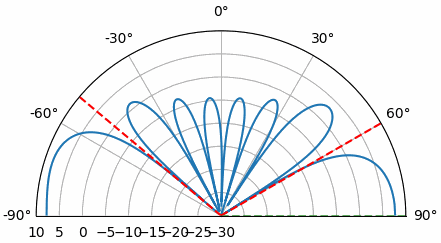
# Scenario
sample_rate = 1e6
d = 0.5 # halve-golflengteafstand
N = 100000 # aantal te simuleren samples
Nr = 8 # elementen
theta_soi = 20 / 180 * np.pi # omzetten naar radialen
theta2 = 60 / 180 * np.pi
theta3 = -50 / 180 * np.pi
t = np.arange(N)/sample_rate # tijdsvector
s1 = np.exp(2j * np.pi * d * np.arange(Nr) * np.sin(theta_soi)).reshape(-1,1) # 8x1
s2 = np.exp(2j * np.pi * d * np.arange(Nr) * np.sin(theta2)).reshape(-1,1)
s3 = np.exp(2j * np.pi * d * np.arange(Nr) * np.sin(theta3)).reshape(-1,1)
# SOI is een Gold-code, herhaald, lengte 127
gold_code = np.array([-1, 1, 1, -1, 1, 1, 1, 1, -1, -1, -1, 1, 1, -1, -1, -1, -1, -1, 1, 1, 1, -1, -1, 1, 1, 1, -1, 1, 1, 1, 1, 1, 1, -1, -1, -1, 1, 1, 1, -1, -1, 1, 1, -1, -1, 1, -1, 1, -1, -1, 1, -1, -1, -1, -1, -1, -1, 1, 1, -1, 1, -1, 1, -1, 1, 1, -1, -1, -1, -1, 1, 1, 1, -1, 1, -1, 1, 1, 1, 1, 1, -1, -1, -1, -1, 1, 1, 1, -1, 1, -1, -1, -1, 1, 1, 1, 1, -1, 1, 1, 1, -1, 1, -1, -1, -1, -1, 1, -1, 1, 1, -1, -1, -1, -1, 1, -1, 1, 1, -1, -1, -1, -1, -1, -1, 1, 1])
soi_samples_per_symbol = 8
soi = np.repeat(gold_code, soi_samples_per_symbol)
num_sequence_repeats = int(N / soi.shape[0]) + 1 # aantal herhalingen om N samples te vullen
soi = np.tile(soi, num_sequence_repeats)[:N] # herhaal reeks over simulatieduur en knip af
soi = soi.reshape(1, -1) # 1xN
# Interferentie, bv. toonjammers, uit verschillende richtingen
tone2 = np.exp(2j*np.pi*0.02e6*t).reshape(1,-1)
tone3 = np.exp(2j*np.pi*0.03e6*t).reshape(1,-1)
# Simuleer ontvangen signaal
r = s1 @ soi + s2 @ tone2 + s3 @ tone3
n = np.random.randn(Nr, N) + 1j*np.random.randn(Nr, N)
r = r + 0.5*n # 8xN
# LMS: richting van SOI is onbekend, SOI-signaal zelf is wel bekend
mu = 0.5e-5 # LMS-stapgrootte
w_lms = np.zeros((Nr, 1), dtype=np.complex128) # start met nullen
# Loop over ontvangen samples
error_log = []
for i in range(N):
r_sample = r[:, i].reshape(-1, 1) # 8x1
soi_sample = soi[0, i] # scalar
y = w_lms.conj().T @ r_sample # pas de gewichten toe
y = y.squeeze() # maak er een scalar van
error = soi_sample - y
error_log.append(np.abs(error)**2)
w_lms += mu * np.conj(error) * r_sample # gewichten zijn nog steeds 8x1
w_lms /= np.linalg.norm(w_lms) # normaliseer gewichten
plt.plot(error_log)
plt.xlabel('Iteration')
plt.ylabel('Mean Square Error')
plt.show()
# Plot het bundelpatroon zoals eerder getoond
Probeer theta_soi, de hoeveelheid ruis (dus 0.5*n) en de stapgrootte mu te variëren om te zien hoe het LMS-algoritme presteert.
16.23. Trainingsdata¶
Binnen array processing bestaat het concept “training”, waarbij je covariantiematrix R vastlegt voordat een mogelijke SOI aanwezig is. Dit wordt vooral in radar gebruikt, waar meestal geen SOI aanwezig is en het detectieproces bestaat uit het testen van hoeken om te zien of er ergens een SOI zit. Als we R vóór aanwezigheid van de SOI berekenen, kunnen we met methoden zoals MVDR gewichten bepalen waarin alleen stoorzenders en ruisomgeving zijn opgenomen. Zo voorkom je dat MVDR een null op of vlak bij de SOI-richting zet. Daarna passen we de gewichten toe op het ontvangen signaal om te testen of de SOI nu op die hoek aanwezig is.
Om de waarde van trainingsdata te laten zien voeren we MVDR uit op een opname van een echte 16-element-array (met het QUAD-MxFE-platform van Analog Devices). Eerst doen we MVDR op de gebruikelijke manier, dus met het volledige ontvangen signaal voor R en de gewichten. Daarna gebruiken we een aparte opname, gemaakt voordat de SOI werd ingeschakeld, om R en de gewichten te berekenen.
Deze opnames zijn gemaakt op 3,3 GHz RF, met een array-elementafstand van 0,045 meter, dus \(d = 0.495\). Er is een samplefrequentie van 30 MHz gebruikt. We noemen de drie signalen A, B en C. Signaal C is de aangewezen SOI, A en B zijn stoorzenders. Daarom hebben we een opname nodig met alleen A en B om trainingsdata te maken, zonder dat A en B verplaatsen tussen de trainingsopname en de opname waarin C ook aanwezig is. Hieronder staan de links naar de twee opnames:
https://github.com/777arc/777arc.github.io/raw/master/3p3G_A_B.npy
https://github.com/777arc/777arc.github.io/raw/master/3p3G_A_B_C.npy
Laten we beginnen met normale MVDR op de A_B_C-opname. Die opname staat in np.save()-formaat met een 2D-array: eerste dimensie is het aantal elementen in de array, tweede dimensie het aantal samples.
import matplotlib.pyplot as plt
import numpy as np
# Arrayparameters
center_freq = 3.3e9
sample_rate = 30e6
d = 0.045 * center_freq / 3e8
print("d:", d)
# Bevat alle drie signalen; C noemen we onze SOI
filename = '3p3G_A_B_C.npy'
X = np.load(filename)
Nr = X.shape[0]
Daarna voeren we basis-DOA met MVDR uit om de aankomstrichtingen van de drie signalen te bepalen:
# Voer DOA uit om de aankomstrichting van C te vinden
theta_scan = np.linspace(-1*np.pi/2, np.pi/2, 10000) # tussen -90 en +90 graden
results = []
R = X @ X.conj().T # bereken covariantiematrix; dit geeft een Nr x Nr-matrix van de samples
Rinv = np.linalg.pinv(R) # pseudo-inverse werkt meestal beter dan een echte inverse
for theta_i in theta_scan:
a = np.exp(2j * np.pi * d * np.arange(X.shape[0]) * np.sin(theta_i)) # stuurvector in de gewenste richting theta_i
a = a.reshape(-1,1) # maak er een kolomvector van
power = 1/(a.conj().T @ Rinv @ a).squeeze() # MVDR power equation
power_dB = 10*np.log10(np.abs(power)) # vermogen in dB, zodat kleine en grote lobben tegelijk zichtbaar zijn
results.append(power_dB)
results -= np.max(results) # normalize to 0 dB at peak
Dit is zo’n situatie waarin een rechthoekige plot handiger is dan een poolplot. We hebben de signalen A, B en C gelabeld.

Als we C als SOI willen gebruiken en MVDR-gewichten willen maken die A en B nullen maar C behouden, moeten we de exacte aankomstrichting van C kennen. Dat doen we met een argmax op de DOA-resultaten van hierboven, maar pas nadat we de hoeken van A en B hebben onderdrukt (door de bovenste 60% van de DOA-resultaten op een zeer lage waarde te zetten).
# Haal de hoek van C eruit na het onderdrukken van hoeken met stoorzenders
results_temp = np.array(results)
results_temp[int(len(results)*0.4):] = -9999*np.ones(int(len(results)*0.6))
max_angle = theta_scan[np.argmax(results_temp)] # radians
print("max_angle:", max_angle)
Het blijkt dat C binnenkomt op -0,3407 radialen, en die waarde gebruiken we dus bij het berekenen van de MVDR-gewichten. Dat hebben we al vaker gedaan; het is gewoon de MVDR-vergelijking:
# Bereken MVDR-gewichten
s = np.exp(2j * np.pi * d * np.arange(Nr) * np.sin(max_angle)) # stuurvector in de gewenste richting theta
s = s.reshape(-1,1) # maak er een kolomvector van
w = (Rinv @ s)/(s.conj().T @ Rinv @ s) # MVDR/Capon-vergelijking
Als laatste plotten we het bundelpatroon van de zojuist berekende MVDR-gewichten, samen met de eerdere DOA-resultaten en een groene stippellijn op max_angle:
Klap dit open voor de plotcode (niets nieuws)
# Bereken bundelpatroon
w = w.squeeze()
N_fft = 2048
w_padded = np.concatenate((w, np.zeros(N_fft - Nr))) # zero-pad naar N_fft elementen voor meer FFT-resolutie
w_fft_dB = 10*np.log10(np.abs(np.fft.fftshift(np.fft.fft(w_padded)))**2) # FFT-magnitude in dB
w_fft_dB -= np.max(w_fft_dB) # normalize to 0 dB at peak
theta_bins = np.arcsin(np.linspace(-1, 1, N_fft)) # map FFT-bins naar hoeken in radialen
# Plot bundelpatroon en DOA-resultaten
plt.plot(theta_bins * 180 / np.pi, w_fft_dB) # GEBRUIK RADIALEN VOOR EEN POOLPLOT
plt.plot(theta_scan * 180 / np.pi, results, 'r')
plt.vlines(ymax=np.max(results), ymin=np.min(results) , x=max_angle*180/np.pi, color='g', linestyle='--')
plt.xlabel("Angle [deg]")
plt.ylabel("Magnitude [dB]")
plt.title("Bundelpatroon en DOA-resultaten, zonder training")
plt.grid()
plt.show()

Het is gelukt om nullen op A en B te maken. Op de positie van C (groene stippellijn) hebben we geen null, maar ook niet echt een uitgesproken hoofdlob; eerder een verlaagde lob. Dat komt deels doordat er buiten de richtingen van A, B en C weinig tot geen energie binnenkomt, dus extra lobben (bijv. rond -70, 25 en 40 graden) maken in de praktijk weinig uit. Een andere reden dat de lob bij C niet sterker is, is dat de hoofdlob als het ware concurreert met nullen die MVDR zou plaatsen als we niet exact op die richting gericht waren. Een sterke hoofdlob op max_angle zou mooier zijn, en daarvoor gebruiken we trainingsdata.
We laden nu de opname met alleen A en B om trainingsdata op te bouwen. In een radarsituatie is dit vergelijkbaar met R berekenen voordat je een radar-puls uitzendt (idealiter kort daarvoor).
# Laad trainingsdata met alleen A en B, en bereken daarna Rinv
filename = '3p3G_A_B.npy'
X_A_B = np.load(filename)
R_training = X_A_B @ X_A_B.conj().T # bereken covariantiematrix
Rinv_training = np.linalg.pinv(R_training)
Het grote verschil is nu dat we Rinv_training gebruiken bij het berekenen van de MVDR-gewichten. We hergebruiken max_angle van eerder. Zo richten we op C, maar nemen we C niet op in het ontvangen signaal dat voor R en R_inv wordt gebruikt.
# Bereken MVDR-gewichten met training-Rinv
s = np.exp(2j * np.pi * d * np.arange(Nr) * np.sin(max_angle)) # stuurvector in de gewenste richting theta
s = s.reshape(-1,1) # maak er een kolomvector van (grootte 3x1)
w = (Rinv_training @ s)/(s.conj().T @ Rinv_training @ s) # MVDR/Capon-vergelijking
Met dezelfde plotmethode krijgen we:

Let op dat we nog steeds nullen bij A en B krijgen (de null van B is minder diep, maar B is ook een zwakker signaal), maar nu zien we een sterke hoofdlob richting onze interessehoek C. Dit is precies de kracht van trainingsdata, en waarom het zo belangrijk is in radar-toepassingen.
16.24. Simulatie van breedband-stoorzenders¶
De methode die we dit hoofdstuk gebruikten om signalen op een bepaalde aankomstrichting op de array te simuleren (stuurvector maal verzonden signaal) gaat uit van een smalbandige-aanname: het signaal wordt als enkelvoudige frequentie beschouwd en de stuurvector wordt op die frequentie berekend. Dat is voor veel signalen een goede benadering, maar werkt minder goed voor breedband-signalen, bijvoorbeeld met bandbreedte groter dan circa 5% van de middenfrequentie. We behandelen kort een truc om breedband-ruis uit een bepaalde richting te simuleren (bijv. barrage jamming uit één hoekrichting).
Deze methode werkt door een covariantiematrix R op te bouwen als som van bijdragen van elke breedband-ruisbron. Daarna berekenen we de wortelmatrix A, en genereren we de sampleset X door standaard complexe Gaussische ruis met A te “kleuren”. Een belangrijke parameter is fractional_bw: de bandbreedte van het ruissignaal gedeeld door de middenfrequentie. Als fractional_bw=0 moet de code hieronder hetzelfde scenario geven als de traditionele methode voor ontvangen-signaalsimulatie. De onderstaande Python-code kun je in eerdere voorbeelden gebruiken om X te simuleren.
N = 10 # aantal elementen in ULA
num_samples = 10000
d = 0.5
num_jammers = 3
jammer_pow_dB = np.array([30, 30, 30]) # jammervermogens in dB
jammer_aoa_deg = np.array([-70, -20, 40]) # jammerhoeken in graden
jammer_aoa = np.sin(np.deg2rad(jammer_aoa_deg)) * np.pi
element_gain_dB = np.zeros(N) # gains in dB voor array-elementen (hier overal 0 dB)
element_gain_linear = 10.0 ** (element_gain_dB / 10) # converteer arraygains naar lineaire waarden
fractional_bw = 0.1 # als dit 0 is, komt deze methode overeen met traditionele arrayfactor-simulatie
# Bouw NxN-jammer-covariantiematrix R
R = np.zeros((N, N), dtype=complex)
for m in range(N):
for n in range(N):
for j in range(num_jammers):
total_element_gain = np.sqrt(element_gain_linear[m] * element_gain_linear[n])
sinc_term = np.sinc(0.5 * fractional_bw * (m - n) * jammer_aoa[j] / np.pi)
exp_term = np.exp(1j * (m - n) * jammer_aoa[j])
R[m, n] += 10.0 ** (jammer_pow_dB[j] / 10) * total_element_gain * sinc_term * exp_term
R = np.eye(N, dtype=complex) + R
# Genereer ontvangen samples
A = fractional_matrix_power(R, 0.5) # bereken matrixwortel (effectieve Cholesky-factorisatie)
A = A / np.sqrt(2)
X = np.zeros((N, num_samples), dtype=complex)
for k in range(num_samples):
noise_vec = np.random.randn(N) + 1j * np.random.randn(N) # complexe ruis
X[:, k] = A.conj().T @ noise_vec
In de onderstaande plots zijn de MVDR-gewichten berekend voor 20 graden en in zwart weergegeven, terwijl de conventionele bundelvormer op 20 graden als blauwe stippellijn staat. De drie ruisbronnen zijn rood aangegeven. In de eerste plot is de fractionele bandbreedte 0, wat betekent dat de MVDR-gewichten overeen moeten komen met eerdere smalbandscenario’s. Volgens de plot werkt dit prima, maar als de werkelijke ruis breedband is (en je SOI ook breedband is, waardoor je ruis niet simpel kunt wegfilteren), dan komt de simulatie niet overeen met de praktijk.

Nu passen we een fractionele bandbreedte van 0,1 toe, waardoor de ruisbronnen effectief over een brede band worden uitgesmeerd en MVDR veel bredere nullen vormt. Voor veel praktijkscenario’s is dit realistischer.

16.25. Cirkelarrays¶
We bespreken kort de Uniform Circular Array (UCA), een populaire arraygeometrie voor DOA omdat deze de 180-gradenambiguiteit van ULA’s omzeilt. De KrakenSDR is bijvoorbeeld een 5-element-array, en vaak worden die vijf elementen in een cirkel met gelijke tussenafstand geplaatst. In theorie zijn maar drie elementen nodig om een UCA te vormen, net zoals je met twee elementen al een ULA kunt maken.
Alle code die we tot nu toe hebben bekeken geldt ook voor UCA’s; we hoeven alleen de stuurvectorvergelijking te vervangen door de UCA-variant:
radius = 0.05 # genormaliseerd op golflengte!
d = np.sqrt(2 * radius**2 * (1 - np.cos(2*np.pi/Nr)))
sf = 1.0 / (np.sqrt(2.0) * np.sqrt(1.0 - np.cos(2*np.pi/Nr))) # schaalfactor op basis van geometrie; bij een hexagoon is dit bv. 1.0
x = d * sf * np.cos(2 * np.pi / Nr * np.arange(Nr))
y = -1 * d * sf * np.sin(2 * np.pi / Nr * np.arange(Nr))
s = np.exp(1j * 2 * np.pi * (x * np.cos(theta) + y * np.sin(theta)))
s = s.reshape(-1, 1) # Nrx1
Tot slot wil je hier van 0 tot 360 graden scannen, in plaats van -90 tot +90 zoals bij een ULA.
Voor 2D-arrays (bijv. rechthoekig), zie 2D-bundelvorming.
16.26. Conclusie en Referenties¶
Alle Python-code, inclusief de code waarmee de figuren/animaties zijn gemaakt, staat op de GitHub-pagina van het boek.
- DOA-implementatie in GNU Radio - https://github.com/EttusResearch/gr-doa
- DOA-implementatie gebruikt door KrakenSDR - https://github.com/krakenrf/krakensdr_doa/blob/main/_signal_processing/krakenSDR_signal_processor.py
[1] Mailloux, Robert J. Phased Array Antenna Handbook. Second edition, Artech House, 2005
[2] Van Trees, Harry L. Optimum Array Processing: Part IV of Detection, Estimation, and Modulation Theory. Wiley, 2002.
