 Online Python Console
Online Python Console One-time Donation
One-time Donation


7. Ruis en dB¶
In dit hoofdstuk behandelen we ruis, hoe het wordt gemodelleerd en hoe ermee wordt omgegaan in draadloze systemen. Concepten als AWGN, complexe ruis en SNR/SINR komen langs. Onderweg introduceren we ook decibellen (dB) omdat dit veel wordt gebruikt binnen draadloze communicatiesystemen en SDR’s.
7.1. Gaussische Ruis¶
De meeste mensen zijn met het concept van ruis bekend: ongewilde fluctuaties dat ons signaal kan overstemmen. Ruis ziet er ongeveer zo uit:
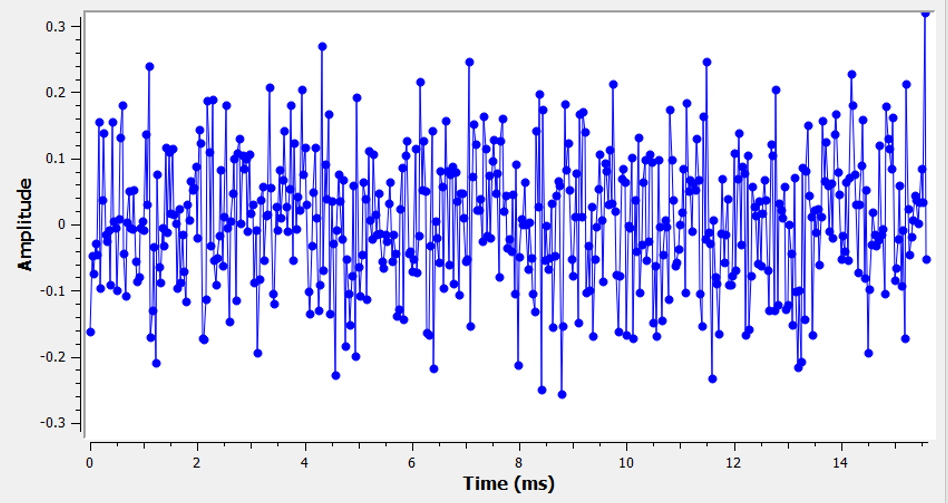
We merken op dat het gemiddelde ruisniveau in het tijddomein-figuur nul is. Als de gemiddelde waarde niet nul zou zijn, dan hadden we de gemiddelde waarde, de offset, ervan af kunnen halen, en dan zouden we over zijn gebleven met een gemiddelde van nul. Ook merken we op dat de individuele punten in het figuur niet “uniform” verdeeld zijn, hogere waarden zijn minder aanwezig dan punten die dichter bij nul zitten.
We noemen dit “gaussische ruis”. Dat is een goed model voor het type ruis wat ontstaat door vele natuurlijke bronnen, zoals de thermische trilling van atomen binnen het silicium van de RF-componenten in onze ontvanger. Volgens de centrale limietstelling zal de sommatie van vele stochastische/willekeurige processen altijd naar een gaussische verdeling convergeren, zelfs wanneer de individuele processen andere verdelingen hebben.

De gaussische verdeling wordt de “normale” verdeling genoemd.
De normale verdeling heeft twee parameters: gemiddelde/verwachtingswaarde en variantie. Waarom het gemiddelde als nul kan worden gezien hebben we al besproken, omdat een statische afwijking altijd eraf kan worden gehaald. De variantie vertelt ons hoe “sterk” de ruis is. Een hogere variantie zal leiden tot hogere nummers. Om deze reden wordt het vermogen ook door de variantie gedefinieerd.
De variantie staat gelijk aan de standaard deviatie in het kwadraat (\(\sigma^2\)).
7.2. Decibellen (dB)¶
We gaan een kort zijspoor in om dB te introduceren. Als je van dB hebt gehoord, voel je dan vrij om dit deel over te slaan.
Het werken met dB is extreem handig wanneer we met kleine en grote getallen op hetzelfde moment werken, of gewoon een hoop supergrote getallen. Kijk eens naar voorbeelden 1 en 2 om te zien hoe moeizaam het is zonder dB te werken:
Voorbeeld 1: Signaal 1 heeft een vermogen van 2 Watt en de ruisvloer is 0.0000002 Watt.
Voorbeeld 2: Een vuilnisbelt is 100000 keer luider dan een stille omgeving, terwijl een kettingzaag 10000 keer luider is dan een vuilnisbelt (geluidsgolven).
Zonder dB, dus in normale “lineaire” termen, hebben we een hoop nullen nodig om de waarden in voorbeelden 1 en 2 te kunnen weergeven. Als we de waarden van signaal 1 zouden willen tonen in de tijd, dan zouden we de ruisvloer niet eens zien! Als bijvoorbeeld de y-as van 0 tot 3 Watt loopt, dan zou de ruis te klein zijn om zichtbaar te worden in de grafiek. Om beide waarden in dezelfde schaal te kunnen gebruiken, moeten we overgaan naar de logaritmische schaal.
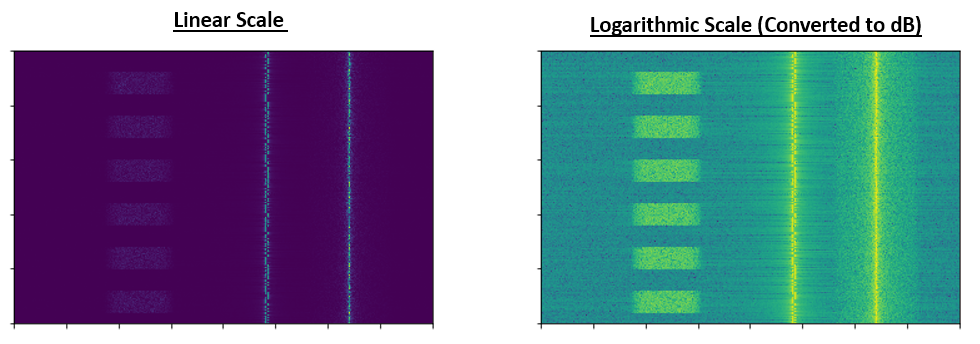
Om het probleem van de juiste schaal in DSP nog duidelijker te maken, kijken we naar de onderstaande watervaldiagrammen van dezelfde drie signalen. De linker kant is het originele signaal in de lineaire schaal, en de rechterkant laat de signalen zien in een logaritmische schaal (dB). Beide representaties gebruiken dezelfde kleurcodering, blauw heeft de laagste waarde en geel de hoogste. Je kunt in het linker figuur, in de lineaire schaal, het signaal nauwelijks zien.
We kunnen voor een gegeven waarde x, het met de volgende formule in dB zetten:
In Python:
x_db = 10.0 * np.log10(x)
Misschien heb je de 10 * als een 20 * gezien in andere domeinen.
Wanneer je met een of ander vermogen werkt, dan gebruik je 10, als je werkt met spanning of stroom dan gebruik je 20.
Binnen de DSP-wereld werken we meestal met vermogens.
Het is zelfs zo, dat we in heel dit boek geen 20 in plaats van 10 nodig hebben.
We kunnen van dB naar lineair (normale getallen) terugrekenen met:
In Python:
x = 10.0 ** (x_db / 10.0)
Raak niet in deze vergelijkingen verstrikt, er is een concept waar het om draait. In DSP werken we met enorm kleine getallen en enorm grote getallen samen (bijv. signaal- vergeleken met ruisvermogen). Wanneer we in dB werken, hebben we een groter dynamisch bereik om getallen uit te drukken in tekst of een grafiek. Daarnaast geeft het een aantal andere voordelen zoals de mogelijkheid om ze bij elkaar op te tellen waar we normaal zouden vermenigvuldigen (zoals je zult zien in het Link Budgets hoofdstuk).
Een aantal veel voorkomende fouten die nieuwelingen maken:
- \(ln()=log^e()\) gebruiken in plaats van \(log^{10}()\). Dit komt omdat in de meeste talen log() voor het natuurlijke logaritme wordt gebruikt.
- Bij het gebruik van getallen of grafiekassen vergeten te melden dat het in dB is. Dit moet ergens aangegeven worden.
- In dB waarden vermenigvuldigen/delen in plaats van optellen/aftrekken. Bijvoorbeeld:
Wat ook belangrijk is om te beseffen , is dat dB technisch gezien geen “eenheid” is. Een waarde in dB is eenheid-loos omdat het over een verhouding gaat, zoals wanneer iets 2x groter is, er is geen eenheid totdat ik je vertel over welke eenheid het gaat. dB is relatief. Wanneer men het over dB heeft in de context van audio, bedoelt men meestal dBA, wat wordt gebruikt voor volume (de A staat voor de eenheid). In draadloze systemen gebruiken we meestal Watt om een vermogensniveau aan te geven. Om die reden zie je misschien dBW als eenheid, wat relatief is aan 1 Watt. Misschien zie je ook dBmW wat relatief is aan 1 mW (en wordt vaak als dBm geschreven). Als iemand bijvoorbeeld zegt dat de zender is afgesteld op 3 dBW, dan gaat dat over \(10^{\frac{1}{3}}=1.995\approx 2\) Watt. Soms gebruiken we dB helemaal op zichzelf, dus relatief zonder eenheden. Iemand zou bijv. kunnen zeggen dat “het ontvangen signaal 20 dB boven de ruisvloer staat”. Een kleine tip hierbij: 0 dBm = -30 dBW.
Hier zijn een aantal standaardwaarden die ik aanraad om te onthouden:
| Lineair | dB |
|---|---|
| 1x | 0 dB |
| 2x | 3 dB |
| 10x | 10 dB |
| 0.5x | -3 dB |
| 0.1x | -10 dB |
| 100x | 20 dB |
| 1000x | 30 dB |
| 10000x | 40 dB |
En om afsluitend deze nummers een context te geven, staan hieronder wat voorbeeldvermogens in dBm:
| 80 dBm | Zendvermogen van een afgelegen FM-radio station |
| 62 dBm | Max vermogen van een ham radiozender |
| 60 dBm | Vermogen van een typische magnetron |
| 37 dBm | Vermogen van een typische draagbare radiozender |
| 27 dBm | Typisch zendvermogen van een mobiele telefoon |
| 15 dBm | Typisch zendvermogen van Wifi |
| 10 dBm | Bluetooth (v 4) max zendvermogen |
| -10 dBm | Max ontvangstvermogen voor Wifi |
| -70 dBm | Mogelijk ontvangstvermogen voor een ham signaal |
| -100 dBm | Minimale ontvangstvermogen voor Wifi |
| -127 dBm | Typisch ontvangstvermogen van GPS satellieten |
7.3. Ruis in het frequentiedomein¶
In het Het Frequentiedomein hoofdstuk hadden we het over Fourier-paren, bijv., hoe een tijddomein-signaal er in het frequentiedomein uitziet. Dus, hoe ziet gaussische ruis in het frequentiedomein eruit? De komende grafieken laten gesimuleerde ruis in het tijddomein (boven) en de spectrale vermogensdichtheid (PSD) van de ruis (onder) zien. De figuren komen uit GNU Radio.
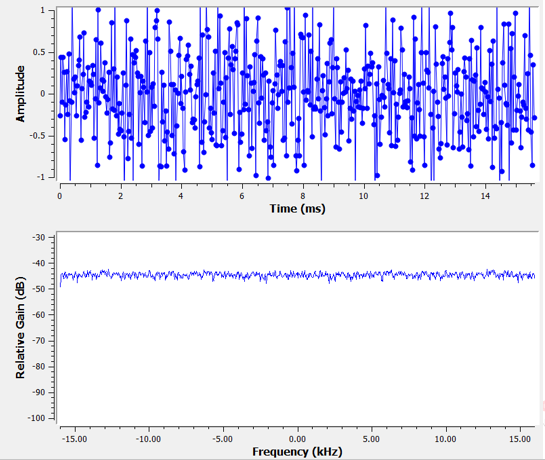
We kunnen zien dat de ruis vrijwel vlak en gelijk is over alle frequenties. Het blijkt dat gaussische ruis in het tijddomein ook gaussische ruis in het frequentiedomein is. Waarom lijken de twee figuren dan niet op elkaar? Dit komt doordat het frequentiedomein-figuur de modulus laat zien van de FFT, dus dat zal alleen positieve getallen opleveren. En nog belangrijker, het gebruikt een logaritmische schaal om de waarden te weergeven in dB. Anders hadden de figuren hetzelfde eruitgezien. We kunnen dit zelf bewijzen door in Python wat ruis te genereren en daarna de FFT te nemen.
import numpy as np
import matplotlib.pyplot as plt
N = 1024 # aantal samples om te simuleren, kies zelf een waarde
x = np.random.randn(N)
plt.plot(x, '.-')
plt.show()
X = np.fft.fftshift(np.fft.fft(x))
X = X[N//2:] # alleen de positieve frequenties // is een integer deling
plt.plot(np.real(X), '.-') #reeele deel ipv lengte/modulus
plt.show()
We merken op dat de randn() functie standaard een gemiddelde heeft van 0 en variantie van 1. Beide figuren zullen er ongeveer zo uitzien:
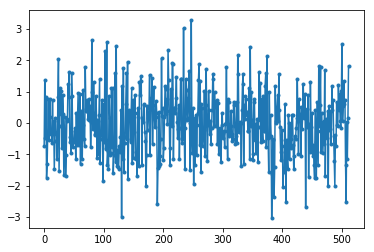
We zouden de vlakke PSD van GNU Radio kunnen genereren door vervolgens de logaritme te nemen en te middelen. Het ruissignaal wat we in de FFT stopten was een reëel signaal (i.p.v. complex), en de FFT van een reëel signaal zal symmetrisch zijn rondom het midden (0 Hz), vandaar dat we alleen het positieve deel namen (de 2e helft). Maar waarom hadden we alleen “reële” ruis gegenereerd, en hoe werkt dat met complexe signalen?
7.4. Complexe Ruis¶
“Complexe Gaussische” ruis zullen we met signalen in de basisband ervaren; het ruisvermogen wordt evenredig over de reële en imaginaire delen verdeeld. Nog belangrijker is te beseffen dat de reële en imaginaire delen onafhankelijk van elkaar zijn; de waarde van het reële deel zegt niets over de waarde van het imaginaire deel.
In Python kunnen we complexe gaussische ruis genereren met:
n = np.random.randn() + 1j * np.random.randn()
Maar wacht! De bovenstaande vergelijking genereert niet dezelfde hoeveelheid ruisvermogen als np.random.randn().
Het gemiddelde vermogen van een signaal met een gemiddelde van 0 (of ruis) kunnen we vinden met:
power = np.var(x)
Waar np.var() de variantie berekent.
Dit levert voor n een signaalvermogen op van 2.
Om complexe ruis te generen met een vermogen van 1 (wat dingen eenvoudiger maakt) moeten we het ruissignaal normaliseren met:
n = (np.random.randn(N) + 1j*np.random.randn(N))/np.sqrt(2) # AWGN with unity power
Om de complexe ruis in het tijddomein te weergeven hebben we, zoals bij elk complex signaal, twee regels nodig:
n = (np.random.randn(N) + 1j*np.random.randn(N))/np.sqrt(2)
plt.plot(np.real(n),'.-')
plt.plot(np.imag(n),'.-')
plt.legend(['real','imag'])
plt.show()
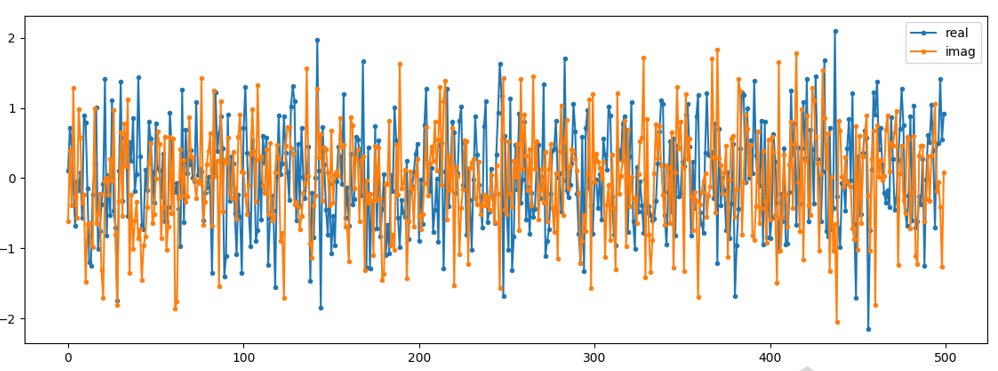
Zoals je ziet, zijn de reële en imaginaire delen compleet onafhankelijk.
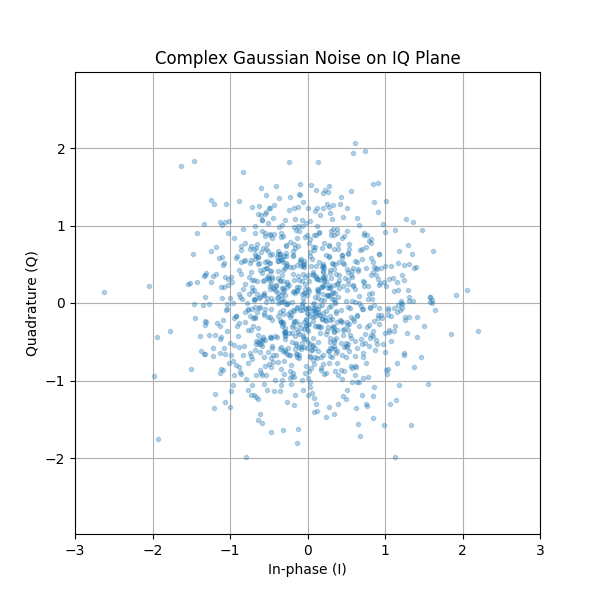
Hoe ziet die gaussische ruis op een IQ-diagram eruit? Zoals je weet laat het IQ-diagram het reële deel (horizontaal) en het imaginaire deel (verticaal) zien. In dit geval hebben beide assen een onafhankelijke gaussische verdeling.
plt.plot(np.real(n),np.imag(n),'.')
plt.grid(True, which='both')
plt.axis([-2, 2, -2, 2])
plt.show()
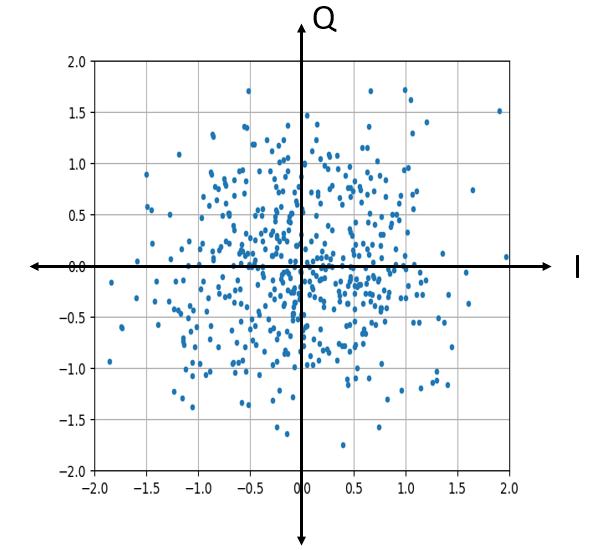
Dit ziet eruit zoals we het zouden verwachten; een willekeurige klodder met het midden rond 0+0j, de oorsprong. Laten we voor de lol, om te kijken hoe het eruit ziet, wat ruis proberen toe te voegen aan een QPSK-signaal:
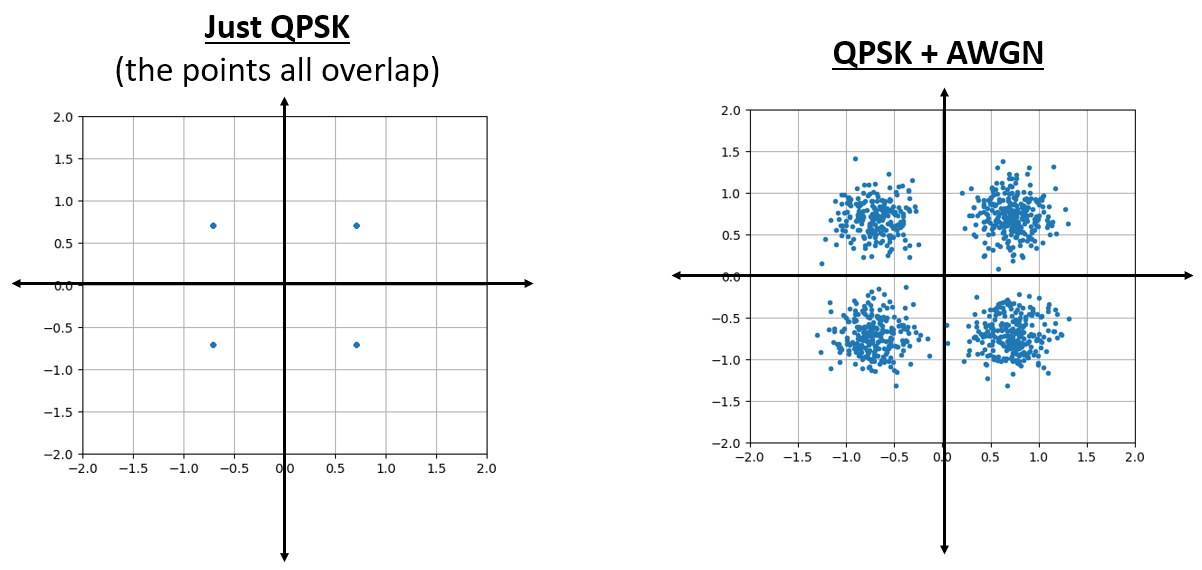
En wat als de ruis nog sterker is?
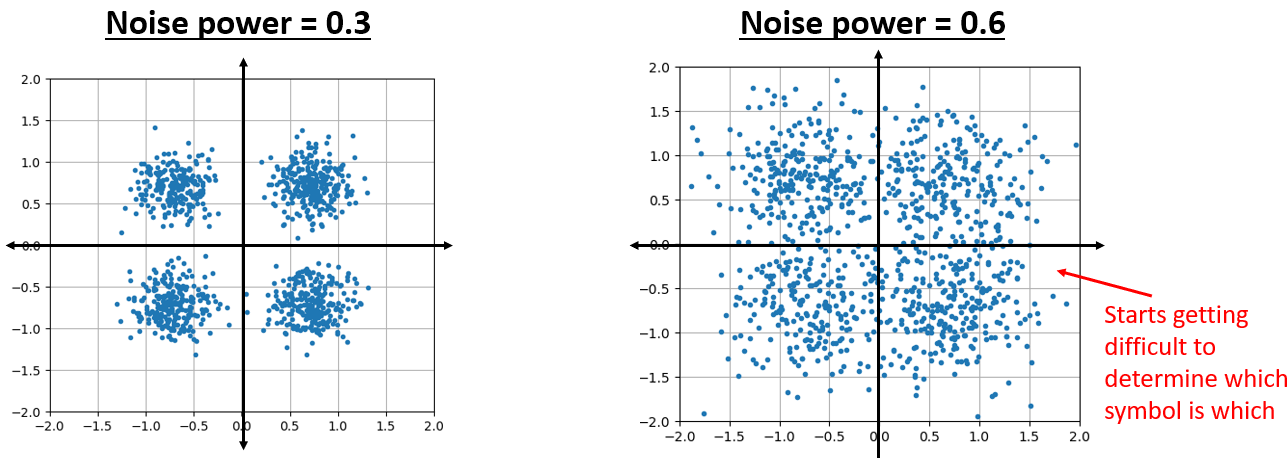
Nu beginnen we een gevoel te krijgen waarom het niet zo simpel is om draadloos data over te sturen. We willen zoveel mogelijk bits per symbool versturen, maar als de ruis te groot is zullen we bij de ontvanger verkeerde bits krijgen.
7.5. AWGN¶
Additive White Gaussian Noise (AWGN) is een afkorting die je vaak in de DSP en SDR-wereld zult tegenkomen. GN, gaussische ruis, hebben we al behandeld. ‘Additive’ of toevoegend, betekent gewoon dat de ruis wordt toegevoegd aan ons ontvangen signaal. ‘White’ of wit, betekent dat het frequentiespectrum over het volledig geobserveerde bereik vlak is. In de praktijk is het bijna altijd wit, of vrijwel wit. In dit boek zullen we alleen AWGN in beschouwing nemen bij het behandelen van communicatieketens en ketenbudgetten e.d. Niet-AWGN ruis is een vak apart.
7.6. SNR en SINR¶
Signal-to-Noise Ratio (SNR) of de signaalruisverhouding is hoe we het krachtverschil tussen het signaal en de ruis uitdrukken. Het is een verhouding dus het heeft geen eenheid. In de praktijk is SNR bijna altijd in dB. Voor simulaties programmeren we onze signalen altijd op zo’n manier dat het een vermogen heeft van 1, of eenheidsvermogen. Als we nu een SNR van 10 dB in de simulatie willen creëren, kunnen we simpelweg ruis genereren van -10 dB vermogen door bij het aanmaken van de ruis de variantie aan te passen.
Als iemand het over “SNR = 0 dB” heeft, betekent het dat het signaal- en ruisvermogen gelijk zijn. Een positieve SNR betekent dat het signaalvermogen groter is dan van de ruis, terwijl een negatieve SNR indiceert dat het ruisvermogen groter is dan het signaalvermogen. Het is meestal erg lastig om signalen met een negatieve SNR nog te kunnen detecteren.
Zoals eerder gezegd, is het vermogen van een signaal gelijk aan de variantie van dat signaal. We zouden SNR dus kunnen uitdrukken als de verhouding van varianties:
Signal-to-Interference-plus-noise verhouding (SINR) of signaal-tot-verstoring-plus-ruis is in essentie hetzelfde als SNR, maar je neemt in de deler ook de verstoring mee.
Wat die verstoring inhoudt, verschilt per toepassing/situatie, maar meestal gaat het om een ander ongewenst signaal wat het signaal van interesse verstoort op zo’n manier dat het niet weg te filteren is.
7.7. Diepere duik in stochastische variabelen¶
Tot nu toe hebben we de wiskunde wat licht gehouden, maar nu doen we een stap terug en introduceren we het concept stochastische variabelen en hoe die in draadloze communicatie en SDR worden gebruikt. Een stochastische variabele is een wiskundig object dat uitkomsten van een willekeurig experiment op numerieke waarden afbeeldt. Stochastische variabelen beschrijven grootheden waarvan de waarde pas bekend is nadat je die observeert of meet, zoals onze ruissamples. Denk aan het gooien van een dobbelsteen. Voor de worp weet je niet welk getal valt. We kunnen een stochastische variabele \(X\) definieren als de uitkomst van die worp. De waarde van \(X\) ligt in {1, 2, 3, 4, 5, 6}, maar welke het wordt weten we pas na de worp.
In draadloze communicatie en SDR zijn stochastische variabelen overal:
- Thermische ruis in een ontvanger wordt op elk tijdstip als stochastische variabele gemodelleerd
- De amplitude van een ontvangen signaal met multipadfading is willekeurig
- De fase-offset door een veranderend kanaal kan als stochastische variabele tussen \(0\) en \(2\pi\) worden gezien
- Zelfs de databits die we verzenden kun je als stochastische variabelen beschouwen
Een sample versus veel samples
Dit onderscheid is cruciaal en zorgt vaak voor verwarring:
- Een enkele uitkomst of enkel sample van een stochastische variabele is slechts een getal: een uitkomst van het willekeurige experiment
- Om een stochastische variabele te karakteriseren (gemiddelde, spreiding, enz.) heb je veel uitkomsten nodig
Roep je in Python np.random.randn() zonder argumenten aan, dan krijg je een enkel willekeurig getal uit een Gauss-verdeling. Met dat ene getal weet je vrijwel niets over de verdeling. Roep je np.random.randn(10000) aan en genereer je 10.000 samples, dan kun je eigenschappen zoals gemiddelde en variantie schatten.
import numpy as np
# Single sample - just one number
x_single = np.random.randn()
print(x_single) # might be 0.534, -1.23, or any other value
# Many samples - now we can characterize the distribution
x_many = np.random.randn(10000)
print(np.mean(x_many)) # will be close to 0
print(np.var(x_many)) # will be close to 1
Gezamenlijke verdelingen¶
Tot nu toe keken we naar losse stochastische variabelen. Werk je met twee of meer stochastische variabelen tegelijk, dan gebruik je een gezamenlijke verdeling.
Voor continue variabelen \(X\) en \(Y\) wordt dit beschreven door de gezamenlijke PDF:
De gezamenlijke PDF vertelt hoe waarschijnlijk het is dat \(X\) waarde \(x\) aanneemt en \(Y\) tegelijk waarde \(y\).
Uit de gezamenlijke PDF kunnen we berekenen:
- Marginale PDF’s (bijv. \(f_X(x)\) of \(f_Y(y)\))
- Verwachtingswaarden zoals \(E[XY]\)
- Covariantie en correlatie
- Kansen waarin beide variabelen voorkomen
De marginale PDF van \(X\) krijg je bijvoorbeeld door over \(Y\) te integreren:
Gezamenlijke verdelingen vormen de wiskundige basis om afhankelijkheid, correlatie en onafhankelijkheid tussen stochastische variabelen te begrijpen.
Kansverdelingen¶
Een kansverdeling beschrijft hoe waarschijnlijk verschillende waarden van een stochastische variabele zijn. Voor een continue stochastische variabele gebruiken we een probability density function (PDF), genoteerd als \(f_X(x)\). De PDF geeft de relatieve waarschijnlijkheid van verschillende waarden.
De belangrijkste verdeling in SDR en communicatie is de Gauss- (normale) verdeling. Een Gaussische stochastische variabele \(X\) met gemiddelde \(\mu\) en variantie \(\sigma^2\) heeft de PDF:
Dit is de bekende “klokvorm”. De verdeling wordt volledig bepaald door twee parameters:
- Gemiddelde \(\mu\): het centrum van de verdeling
- Variantie \(\sigma^2\): de spreiding van de verdeling (standaardafwijking \(\sigma\) is de wortel van de variantie)
In Python genereert np.random.randn() samples uit een standaard-Gaussverdeling met \(\mu = 0\) en \(\sigma^2 = 1\). Dat kunnen we visualiseren:
import numpy as np
import matplotlib.pyplot as plt
# Generate 10,000 samples from standard Gaussian
x = np.random.randn(10000)
# Create histogram to visualize the distribution
plt.hist(x, bins=50, density=True, alpha=0.7, edgecolor='black')
plt.xlabel('Value')
plt.ylabel('Probability Density')
plt.title('Gaussian Distribution (μ=0, σ²=1)')
plt.grid(True)
plt.show()
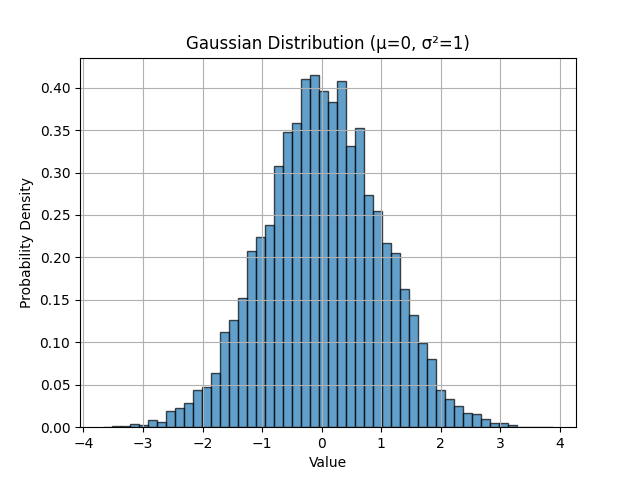
Verwachtingswaarde (oftewel gemiddelde)¶
De verwachtingswaarde van een stochastische variabele, genoteerd als \(E[X]\) of \(\mu\), is de gemiddelde waarde over veel realisaties. Voor een continue stochastische variabele met PDF \(f_X(x)\) is de verwachting:
In de praktijk, met \(N\) samples \(x_1, x_2, \ldots, x_N\) uit de verdeling, schatten we de verwachting met het steekproefgemiddelde:
De verwachtingswaarde is een lineaire operator, dus:
- \(E[aX + b] = aE[X] + b\) voor constanten \(a\) en \(b\)
- \(E[X + Y] = E[X] + E[Y]\) voor willekeurige stochastische variabelen
Die lineariteit is erg nuttig in signaalverwerking.
Variantie en standaardafwijking¶
De variantie van een stochastische variabele, genoteerd als \(\text{Var}(X)\) of \(\sigma^2\), meet hoe ver waarden rond het gemiddelde zijn uitgespreid. Definitie: de verwachtingswaarde van de gekwadrateerde afwijking van het gemiddelde.
Met \(N\) samples schatten we de variantie met:
De standaardafwijking \(\sigma\) is de wortel van de variantie: \(\sigma = \sqrt{\sigma^2}\).
Let op het \(\enspace \hat{} \enspace\)-symbool (“hoedje”) bij \(\sigma\) en bij het steekproefgemiddelde. Dat geeft aan dat het om een schatting gaat. Die is niet exact gelijk aan de werkelijke waarde, maar benadert die steeds beter naarmate je meer samples gebruikt.
Belangrijke eigenschap: Als \(X\) variantie \(\sigma^2\) heeft, dan:
- Schalen: \(\text{Var}(aX) = a^2 \text{Var}(X)\)
- Verschuiven: \(\text{Var}(X + b) = \text{Var}(X)\) (een constante optellen verandert de spreiding niet)
En dus voor standaardafwijking \(\sigma\):
- Schalen: \(\sigma(aX) = a\sigma(X)\)
- Verschuiven: \(\sigma(X+b) = \sigma(X)\)
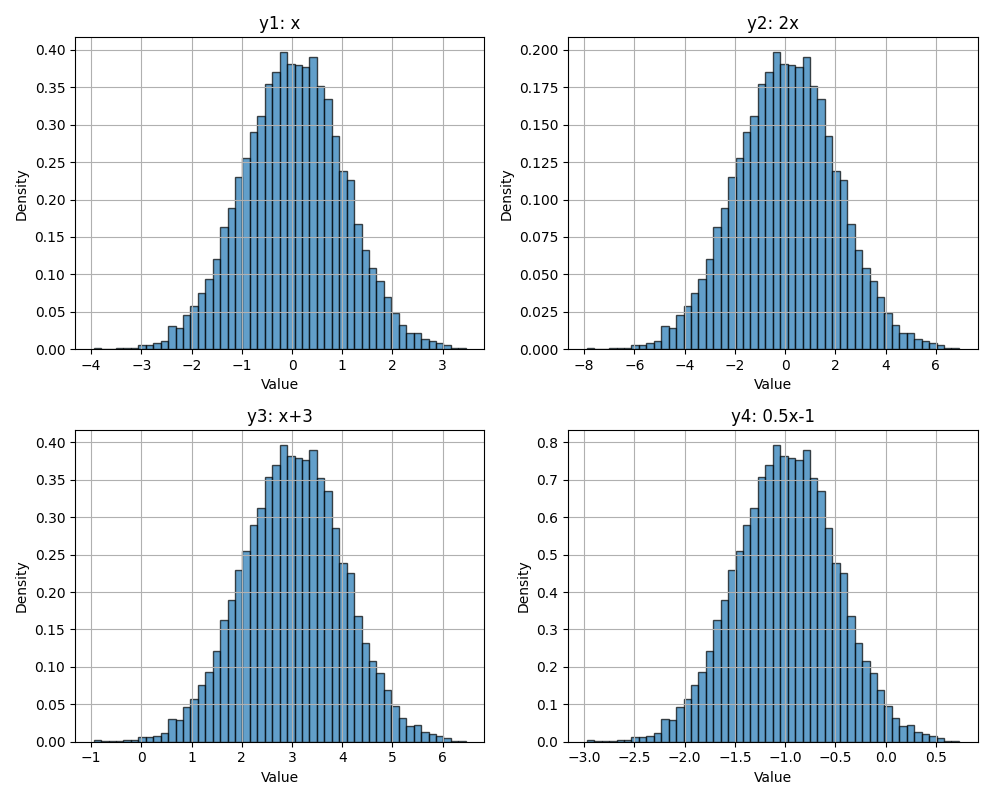
Schalen en verschuiven van de Gaussverdeling (let op de asschalen van x en y).
Variantie en vermogen
In signaalverwerking geldt voor een nulgemiddeld signaal (gemiddelde ~ 0) dat de variantie gelijk is aan het gemiddelde vermogen. Daarom gebruiken we die termen vaak door elkaar:
Deze relatie is fundamenteel bij analyse van ruisvermogen, signaal-ruisverhouding (SNR) en linkbudgets.
noise_power = 2.0
n = np.random.randn(N) * np.sqrt(noise_power)
print(np.var(n)) # will be approximately 2.0
Covariantie¶
De covariantie tussen twee stochastische variabelen \(X\) en \(Y\) is gedefinieerd als:
Een equivalente en vaak handigere vorm is:
Covariantie meet hoe twee variabelen samen variëren:
- Positieve covariantie: ze nemen meestal samen toe of af
- Negatieve covariantie: als de ene toeneemt, neemt de andere vaak af
- Nul covariantie: ze zijn ongecorreleerd
Als beide variabelen nulgemiddeld zijn, vereenvoudigt dit tot:
Covariantie heeft een eenheid (is niet genormaliseerd), daarom gebruiken we in de praktijk vaak de correlatiecoefficient (of gewoon correlatie):
Dit levert een dimensieloze waarde tussen -1 en +1.
Variantie van een som van variabelen¶
In signaalverwerking werken we vaak met sommen van stochastische variabelen, zoals signaal plus ruis:
De variantie van die som hangt af van of \(X\) en \(Y\) onafhankelijk zijn (of algemener: gecorreleerd).
In de algemene vorm:
waar \(\text{Cov}(X,Y)\) de covariantie tussen \(X\) en \(Y\) is.
Onafhankelijk geval
Als \(X\) en \(Y\) onafhankelijk zijn (of eenvoudiger: ongecorreleerd), dan vereenvoudigt dit tot:
Dit resultaat is erg belangrijk in communicatiesystemen. Bijvoorbeeld, als een ontvangen signaal is:
waar \(S\) het signaal is en \(N\) onafhankelijke ruis, dan is het totale vermogen simpelweg de som van signaal- en ruisvermogen.
Daarom zijn SNR-berekeningen zo rechttoe rechtaan.
7.8. Complexe stochastische variabelen¶
In SDR werken we veel met complexe signalen, dus ook met complexe stochastische variabelen. Zo’n variabele heeft de vorm:
waar \(X\) en \(Y\) reele stochastische variabelen zijn voor de in-phase (I) en quadratuur (Q)-component.
Complexe Gaussische ruis
De meest voorkomende complexe stochastische variabele in draadloze communicatie is complexe Gaussische ruis, waarbij \(X\) en \(Y\) onafhankelijke Gaussische variabelen met dezelfde variantie zijn.
Als bijvoorbeeld \(X \sim \mathcal{N}(\alpha_1, \sigma_1^2)\) en \(Y \sim \mathcal{N}(\alpha_2, \sigma_2^2)\) onafhankelijk zijn, dan heeft \(Z = X + jY\):
- Gemiddelde: \(E[Z] = E[X] + jE[Y] = \alpha_1 + j\alpha_2\)
- Variantie (vermogen): \(\text{Var}(Z) = \text{Var}(X) + \text{Var}(Y) = \sigma_1^2 + \sigma_2^2\)
Daarom gebruiken we bij complexe Gaussische ruis met eenheidsvermogen (variantie = 1):
N = 10000
n = (np.random.randn(N) + 1j*np.random.randn(N)) / np.sqrt(2)
print(np.var(n)) # ~ 1
De deling door \(\sqrt{2}\) zorgt dat het totale vermogen (som van I- en Q-variantie) gelijk is aan 1.
# Without normalization:
n_raw = np.random.randn(N) + 1j*np.random.randn(N)
print(np.var(np.real(n_raw))) # ~ 1
print(np.var(np.imag(n_raw))) # ~ 1
print(np.var(n_raw)) # ~ 2 (total power)
# With normalization:
n_norm = n_raw / np.sqrt(2)
print(np.var(n_norm)) # ~ 1 (unit power)
7.9. Toevalsprocessen¶
Tot nu toe bespraken we stochastische variabelen: willekeurige waarden op een enkel punt. Een toevalsproces (ook wel stochastisch proces) is een verzameling stochastische variabelen geindexeerd door de tijd:
Op elk tijdstip \(t\) is \(X(t)\) een stochastische variabele. Zie een toevalsproces als een signaal dat in de tijd willekeurig evolueert.
Voorbeelden in draadloze communicatie:
- Ruis in de ontvanger: \(N(t)\) of \(N[n]\)
- Een signaal met tijdsafhankelijke fading: \(H(t)S(t)\)
- Samples uit een SDR: elke batch is een realisatie van een toevalsproces
Stationaire processen
Een toevalsproces is stationair als de statistische eigenschappen niet in de tijd veranderen. In het bijzonder heeft een wide-sense stationary (WSS) proces:
- Constant gemiddelde: \(E[X(t)] = \mu\) voor alle \(t\)
- Autocorrelatie die alleen van tijdsverschil afhangt: \(E[X(t)X(t+\tau)]\) hangt alleen van \(\tau\) af, niet van \(t\)
Veel ruisbronnen in draadloze systemen zijn ongeveer stationair, wat de analyse sterk vereenvoudigt.
Witte ruis
Witte ruis is een toevalsproces waarbij samples op verschillende tijdstippen ongecorreleerd zijn en de vermogensspectrale dichtheid over alle frequenties constant is. Additive White Gaussian Noise (AWGN) is tegelijk:
- White: ongecorreleerd in de tijd, vlak spectrum
- Gaussian: elke sample is Gaussisch verdeeld
Als we in Python ruis maken met np.random.randn(N), is elke van de \(N\) samples een onafhankelijke Gaussische stochastische variabele, samen een wit-ruisproces.
Onafhankelijkheid en correlatie¶
Twee stochastische variabelen \(X\) en \(Y\) zijn onafhankelijk als kennis van de ene niets zegt over de andere. Wiskundig factoriseert dan de gezamenlijke PDF:
Onafhankelijkheid is een sterke voorwaarde. Een zwakkere voorwaarde is ongecorreleerd, wat betekent:
Voor Gaussische stochastische variabelen impliceert ongecorreleerd ook onafhankelijk (een speciale eigenschap van Gaussische variabelen).
Bij complexe Gaussische ruis zijn de I- en Q-component onafhankelijk:
N = 10000
I = np.random.randn(N)
Q = np.random.randn(N)
# Check independence via correlation
correlation = np.corrcoef(I, Q)[0, 1]
print(f"Correlation between I and Q: {correlation:.4f}") # ~ 0
7.10. Extra leesmateriaal¶
Bronnen over AWGN, SNR, en variantie:
