 Online Python Console
Online Python Console One-time Donation
One-time Donation


21. Detectie met Correlatie¶
Mede-auteur: Sam BrownIn dit hoofdstuk leren we hoe we de aanwezigheid van signalen kunnen detecteren en hun timing terug kunnen vinden door ontvangen samples kruis te correleren met een voor ons bekend deel van het signaal, zoals de preamble van een pakket. Deze methode leidt van nature tot een eenvoudige vorm van classificatie met een rij correlators. We introduceren de basisconcepten van signaaldetectie, met focus op de beslissing of een specifiek signaal wel of niet aanwezig is in een ruisachtige omgeving. Daarbij behandelen we zowel de theoretische basis als praktische technieken om onder onzekerheid zo goed mogelijk te beslissen.
21.1. Basis van Signaaldetectie en Correlators¶
Signaaldetectie is de taak waarbij wordt besloten of een waargenomen energiepiek een betekenisvol signaal is of alleen achtergrondruis.
De Uitdaging: In systemen zoals radar of sonar is ruis overal aanwezig. Als de detector te gevoelig is, krijg je “valse alarmen”. Is hij niet gevoelig genoeg, dan “mist” hij het echte doel.
De oplossing begint met de Neyman-Pearson-detector, die een wiskundige “sweet spot” geeft: maximale kans op detectie bij een strikt begrensde kans op vals alarm. CFAR-detectors (CFAR: Constant False Alarm Rate) bouwen hierop voort door adaptief te reageren op veranderingen in het ruisniveau. Meer specifiek worden CFAR-detectors gebruikt wanneer de ruisstatistiek niet stationair is, dus wanneer ruisvloer en ruisverdeling veranderen door interferentie en veranderende kanaalomstandigheden. Het doel is om de detectiedrempel automatisch mee te laten bewegen met de achtergrondruis, zodat een gewenste vals-alarmkans behouden blijft. Dat vereist een continue schatting van de ruisvloer.
Zodra een systeem weet dat er iets aanwezig is, moet het precies bepalen waar de data start. Digitale pakketten in LTE, 5G en wifi beginnen met een “preamble”: een bekend en herhaald patroon. Een preamble-correlator werkt als een “slot-en-sleutel”-mechanisme, waarbij de sleutel een symboolreeks is die de ontvanger kent en die uniek is voor het te herstellen signaal. Door een kopie van die preamble over het inkomende signaal te schuiven en op elke vertraging een inwendig product te nemen, meet de ontvanger de overeenkomst tussen sjabloon en ontvangen reeks. Als beide bijna perfect uitlijnen, ontstaat een scherpe piek die exact aangeeft waar de data begint. Geavanceerde varianten houden ook rekening met frequentie-offset door afstemverschillen of Doppler-verschuiving.
Wanneer een bekend signaal (de preamble) over een kanaal met alleen Additive White Gaussian Noise (AWGN) wordt verzonden, is de taak simpel: beslissen of het signaal aanwezig is. Dit is het eenvoudigste, maar ook meest fundamentele detectieprobleem.
De Kruiscorrelatiefunctie¶
Een correlator in de eenvoudigste vorm is gewoon een kruiscorrelatie tussen een ontvangen signaal en een sjabloon van wat je zoekt. Kruiscorrelatie is een inwendig product tussen twee vectoren terwijl één vector over de andere schuift. Als je convolutie kent: het is bijna hetzelfde, behalve dat je de tweede vector niet omkeert, dus net iets eenvoudiger. Voor complexe signalen, waar we hier mee werken, neem je ook de complex geconjugeerde van één ingang. In Python kan dat zo:
def correlate(a, v):
n = len(a)
m = len(v)
result = []
for i in range(n - m + 1):
s = 0
for j in range(m):
s += a[i + j] * v[j].conjugate()
result.append(s)
return result
# Voorbeeldgebruik:
a = [1+2j, 2+1j, 3+0j, 4-1j, 5-2j]
v = [0+1j, 1+0j, 0.5-0.5j]
correlate(a, v)
Let op hoe a schuift en v complex geconjugeerd wordt, en hoe de loop met j en s in feite gewoon een inwendig vector-product is. Gelukkig hoeven we kruiscorrelatie niet zelf van nul te implementeren: in Python kunnen we NumPy’s correlate gebruiken (er is ook een SciPy-variant).
Python-voorbeeld van een Kruiscorrelatie¶
Om een basisvoorbeeld van een correlator in Python te maken, bouwen we eerst een voorbeeldsignaal met een bekende preamble in ruis. We gebruiken een Zadoff-Chu-sequentie als bekende preamble vanwege de uitstekende autocorrelatie-eigenschappen en het veelvuldige gebruik in communicatiesystemen. We negeren hier de rest van de payload-data, al volgt in echte systemen na de preamble meestal onbekende data. Een Zadoff-Chu-sequentie genereren we zo:
import numpy as np
import matplotlib.pyplot as plt
N = 839 # Length of Zadoff-Chu sequence
u = 25 # Root of ZC sequence
t = np.arange(N)
zadoff_chu = np.exp(-1j * np.pi * u * t * (t + 1) / N)
De resulterende sequentie is een signaal: de IQ-samples van zadoff_chu vormen een complex basisbandsignaal zoals we vaak in dit boek zien, alleen encodeert het hier geen bits. We kunnen een realistischer scenario nabootsen door dit Zadoff-Chu-signaal op een willekeurige offset in een langere AWGN-stroom te plaatsen:
signal_length = 10 * N # overall simulated signal length
offset = np.random.randint(N, signal_length - N)
print(f"True offset: {offset}")
snr_db = -15
noise_power = 1 / (2 * (10**(snr_db / 10)))
signal = np.sqrt(noise_power/2) * (np.random.randn(signal_length) + 1j * np.random.randn(signal_length))
signal[offset:offset+N] += zadoff_chu # place our ZC signal at the random offset
Let op dat we hier een zeer lage SNR gebruiken. Die is zo laag dat je de Zadoff-Chu-sequentie in het tijdsdomein helemaal niet terugziet. De sequentie is 839 samples lang op ongeveer 8000 gesimuleerde samples, en zit zo diep in de ruis dat je zelfs geen kleine toename in signaalamplitude ziet.

Nu kunnen we de correlator implementeren door een kruiscorrelatie uit te voeren tussen het ontvangen signaal en onze bekende Zadoff-Chu-sequentie met np.correlate(). Dit veronderstelt dat de ontvanger de exacte preamble kent. zadoff_chu werd eerst gebruikt om het scenario te simuleren, maar fungeert nu ook als sjabloon dat de ontvanger in de correlator gebruikt. In Python kan dit in één regel:
correlation = np.correlate(signal, zadoff_chu, mode='valid')
De valid-modus lichten we zo toe. We normaliseren de uitgang ook met de sequentielengte en nemen de magnitude in het kwadraat om vermogen te krijgen. Je kunt ook alleen de magnitude nemen; dat werkt meestal ook. Het belangrijkste blijft de np.correlate()-operatie.
correlation = np.abs(correlation / N)**2 # normalize by N, and take magnitude squared
Hieronder plotten we de magnitude in het kwadraat en markeren we de echte startpositie van de sequentie om te zien of de correlator die vindt:

Ondanks de zeer lage SNR zien we een duidelijke piek in de correlator-uitgang precies waar de Zadoff-Chu-sequentie is geplaatst. Dat is de start van de sequentie: de 839 samples vanaf die piek bevatten het patroon. Dit laat de kracht van correlatiegebaseerde detectie zien, zeker in combinatie met een lange preamble. We hebben nog geen expliciete drempel ingesteld om te beslissen of de piek een echt signaal of ruis is; we inspecteren nu visueel. Voor automatische detectie is een drempel nodig. De rest van dit hoofdstuk gaat grotendeels over hoe je die drempel goed kiest, vooral wanneer ruisvloer en interferentie continu veranderen.
Modi: Valid, Same en Full¶
Je hebt misschien gezien dat np.correlate() en np.convolve() drie modi hebben: valid, same en full. Die bepalen de lengte van de output-array ten opzichte van de inputs. In ons geval gebruikten we valid, wat betekent dat alleen punten worden teruggegeven waar beide arrays volledig overlappen. De outputlengte wordt dan len(signal) - len(zadoff_chu) + 1. Met same krijg je een output met dezelfde lengte als het (langste) ingangssignaal. Met full krijg je de volledige lineaire discrete convolutie, met een iets langere output van lengte max(M, N) - min(M, N) + 1, waarbij M en N de lengtes van beide arrays zijn. In veel RF-signaalbewerking gebruiken we convolutie om een FIR-filter toe te passen, en dan is same handig omdat input en output even lang blijven. Voor correlatiegebaseerde detectie willen we meestal valid, omdat vooral de posities interessant zijn waar de preamble volledig overlapt met het ontvangen signaal.
De Neyman-Pearson-detector¶
De gouden standaard voor het kiezen van een goede drempel voor correlatoruitgang is de Neyman-Pearson-detector. Deze theorie helpt een optimale beslissing nemen onder een specifieke randvoorwaarde: maximaliseer de detectiekans, \(P_{D}\), bij een vaste en acceptabele vals-alarmkans, \(P_{FA}\). Simpel gezegd: jij kiest hoeveel valse detecties je maximaal accepteert (bijvoorbeeld één per uur), en Neyman-Pearson geeft de beste drempel om zoveel mogelijk echte signalen te vinden. Voor detectie van een bekende preamble in AWGN is de aanpak eenvoudig: bereken een correlatiewaarde tussen het ontvangen signaal en een bekend preamble-patroon. Overschrijdt die waarde de drempel \(\tau\), dan verklaar je het signaal aanwezig; anders ga je ervan uit dat er alleen ruis is.
De prestatie van deze detector, gemeten met \(P_{D}\) en \(P_{FA}\), hangt af van de drempel \(\tau\), de SNR en de preamblelengte \(L\). De vals-alarmkans is een functie van de drempel en ruisvariantie \(\sigma_n^2\):
\(P_{FA} = Q\left(\frac{\tau}{\sigma_n}\right)\)
De detectiekans is een functie van drempel, ruisvariantie en preamble-energie (\(E_s = L \cdot S\), met \(S\) als gemiddeld symboolvermogen):
\(P_{D} = Q\left(\frac{\tau - \sqrt{E_s}}{\sigma_n}\right) = Q\left(\frac{\tau - \sqrt{L \cdot S}}{\sigma_n}\right)\)
Hier is \(Q(x)\) de Q-functie (staartkans van de standaardnormale verdeling), oftewel de kans dat een standaardnormale variabele groter is dan \(x\).
Prestatie-analyse: ROC-curves en Pd-vs-SNR-curves¶
Om te kwantificeren hoe goed een correlatie-detector presteert in ruis, gebruiken engineers twee hoofdvisualisaties: de Receiver Operating Characteristic (ROC)-curve en de Probability of Detection (\(P_{d}\))-tegen-SNR-curve.
De ROC-curve zet \(P_{d}\) uit tegen \(P_{fa}\) bij vaste SNR. Door de detectiedrempel op de correlatoruitgang te variëren kies je een punt op deze curve; het blijft een afweging. Een lagere drempel verhoogt \(P_{d}\) (meer signalen gevonden), maar ook \(P_{fa}\) (meer ruis-triggers). Hoe sterker de curve naar linksboven buigt, hoe beter de detector. Een perfecte detector zit linksboven (100% \(P_{d}\), 0% \(P_{fa}\)), terwijl een diagonaal overeenkomt met gokken.

Uit de vergelijkingen (en intuïtie) volgt dat preamblelengte \(L\) een cruciale ontwerpparameter is, omdat die direct de processing gain en daarmee de detectieprestatie bepaalt. Bij vaste drempel en SNR groeit \(P_{D}\) met \(L\). Een langere preamble verzamelt meer signaalenergie, waardoor scheiding tussen signaal en achtergrondruis eenvoudiger wordt. Deze prestatieverbetering heet “processing gain” en wordt vaak in dB uitgedrukt als \(10\log_{10}(L)\). Dit is essentieel voor zwakke signalen die anders gemist worden. Door energie over meer samples te integreren kun je signalen detecteren die onder de ruisvloer liggen.
21.2. Voorbeeld: GPS-signalen detecteren onder de ruisvloer¶
Korte introductie tot GPS-signalen¶
In maart 2026 waren er 31 operationele satellieten in de Amerikaanse GPS-constellatie. Ze vliegen in medium Earth orbit (MEO) rond de aarde en doen ongeveer twee omwentelingen per dag. Alle satellieten zenden een signaal uit rond 1575.42 MHz (L1); dit signaal staat continu aan en gebruikt voor alle satellieten dezelfde draagfrequentie. Tegen de tijd dat het signaal het aardoppervlak bereikt is het extreem zwak, ruim onder de ruisvloer. Orthogonaliteit tussen satellieten wordt bereikt doordat elke satelliet een unieke PRN-code (pseudo-random noise) van 1023 chips krijgt, de C/A-code. Daarom zie je dit signaal ook vaak als “L1 C/A”. Deze C/A-codes zijn Gold-codes en zo ontworpen dat twee verschillende codes vrijwel orthogonaal zijn; correleer je twee verschillende satellietcodes met elkaar, dan krijg je bijna nul. De C/A-code loopt op 1.023 miljoen chips per seconde en is 1023 chips lang, dus herhaalt exact elke 1 ms. Boven op die herhalende code moduleert elke satelliet langzaam navigatiedata (baaninformatie, klokcorrecties, enz.) met slechts 50 bits/s, waardoor een databit 20 volledige coderepetities beslaat. Dit principe van een andere code per zender heet CDMA (Code Division Multiple Access), hetzelfde idee als achter 3G.
Aan de ontvangerkant gebruikt de ontvanger, om een van de 31 satellieten te vinden, de code van die satelliet en genereert lokaal een kopie van de PRN-sequentie. Vervolgens gebruikt hij een correlator om het begin van de sequentie te vinden, vergelijkbaar met het begin van een pakket/frame, al zendt GPS in de praktijk continu uit. De exacte correlatiepiek wordt ook gebruikt om te bepalen hoe ver het signaal heeft afgelegd voor het de ontvanger bereikt. Als je dit voor 4 of meer satellieten doet, kan de ontvanger via trilateratie zijn positie op aarde bepalen. Omdat satellieten zo snel bewegen (ongeveer 4 km/s relatief), is er bovendien aanzienlijke Dopplerverschuiving. Daarom moet de ontvanger ook over een raster van mogelijke frequentie-offsets zoeken naar de beste correlatiepiek, feitelijk een 2D-zoekprobleem. De maximale Dopplerverschuiving is ongeveer +/-20 kHz (4e3 / 3e8 * 1.575e9). Dit proces herhaalt elke 1 ms, al houdt de ontvanger de tijdsverschillen en Dopplerverschuiving daarna bij zodat niet telkens een volledige zoekactie nodig is. Het eerste vinden van een satelliet heet “acquisition”, en het daarna volgen van het signaal heet “tracking”. Acquisition is rekenintensiever en kan minuten duren bij een “cold start”, wanneer de ontvanger nog geen informatie heeft over zichtbare satellieten, hun Doppler of de eigen locatie.
Correlatie-aanpak¶
We kruiscorreleren het binnenkomende signaal (hier: een L1-opname) met een lokaal gegenereerde replica van de code van elke satelliet. Een grote correlatiepiek betekent dat die satelliet zichtbaar is en geeft de start van de 1 ms codeperiode. Om ook over frequentie te zoeken en Doppler mee te nemen, gebruiken we een FFT en voeren we de correlatie uit in het frequentiedomein. Daardoor kunnen we efficient meerdere frequentie-offsets testen door de FFT-bins van de lokale codereplica te verschuiven. Tot slot accumuleren we vermogen (correlatiemagnitude in het kwadraat) over meerdere 1 ms-blokken om de SNR te verbeteren. Dat heet non-coherente integratie en helpt om GPS-signalen onder de ruisvloer te detecteren. In het tijddomein zoeken we de pieken in de correlatie-uitgang gedeeld door het gemiddelde correlatievermogen over alle delays, als normalisatie.
Voorbeeldopname¶
We gebruiken een voorbeeldopname van GPS van Daniel Estevez, die je hier kunt downloaden. Het bestand is complex float32 met 4 MHz samplerate en gecentreerd op 1575.42 MHz.
Hieronder zie je het spectrogram van de opname; er is niet veel zichtbaar. De verticale lijn is niet het GPS-signaal zelf, maar waarschijnlijk smalbandige interferentie. De werkelijke GPS L1-signalen gebruiken een chiprate van 1.023 MHz met daarbovenop een signaal met zeer lag datarate, waardoor de totale signaalbandbreedte ongeveer 2 MHz is. Dat zie je hier nauwelijks terug in het spectrogram. Dit is een goed voorbeeld van hoe GPS-signalen ruim onder de ruisvloer binnenkomen en waarom correlatiegebaseerde detectie noodzakelijk is.

Voor wie verder wil kijken: deze opname is een klein deel van een veel groter bestand op IQEngine, onder estevez/GPS and other GNSS, met opname GPS-L1-2022-03-27. Op IQEngine staat die als int16 in SigMF-formaat.
Python-voorbeeld¶
Pas filename aan naar de locatie waar je het IQ-bestand hebt opgeslagen. Let op dat num_integrations bepaalt hoeveel van de IQ-opname wordt ingelezen en verwerkt: die waarde maal 1 ms (bij deze korte opname is 10 de maximale waarde).
import numpy as np
import matplotlib.pyplot as plt
filename = "GPS_L1_recording_10ms_4MHz_cf32.iq"
sample_rate = 4e6
chip_rate = 1023000 # chips / sec (part of the GPS spec)
num_chips = 1023 # chips per C/A code period
samples_per_code = int(round(sample_rate / chip_rate * num_chips)) # Exact number of samples in one 1 ms code period at 4 MHz
doppler_min_hz = -5e3 # GPS Doppler ≈ ±4 kHz for stationary receiver
doppler_max_hz = 5e3
doppler_step_hz = 500 # good enough for a coarse search
num_integrations = 10 # non-coherent power integrations (so 10 ms total), determines how much of the IQ recording we read in and process!
detection_thresh_dB = 14.0 # Peak-to-mean ratio (PMR) threshold in dB to declare a detection, GPS C/A signals are typically 14–20 dB PMR above threshold with 10ms of integration
gps_svs = list(range(1, 33)) # 1–32
##### C/A Code Generation #####
# The GPS C/A code is a Gold code formed by XOR-ing two 10-stage maximal-length
# shift registers (G1 and G2). G2 is effectively delayed by a satellite-
# specific number of chips before the XOR
# Reference: IS-GPS-200, Table 3-Ia
G2_DELAY = [ # G2 phase delay (chips) for gps_svs 1–32
5, 6, 7, 8, 17, 18, 139, 140, # 1– 8
141, 251, 252, 254, 255, 256, 257, 258, # 9–16
469, 470, 471, 472, 473, 474, 509, 512, # 17–24
513, 514, 515, 516, 859, 860, 861, 862, # 25–32
]
"""G1 LFSR: polynomial x^10 + x^3 + 1, all-ones init, output at stage 10."""
reg = np.ones(10, dtype=np.int8)
G1 = np.empty(num_chips, dtype=np.int8)
for i in range(num_chips):
G1[i] = reg[9]
fb = reg[2] ^ reg[9] # stages 3 and 10 (0-indexed: 2 and 9)
reg = np.roll(reg, 1)
reg[0] = fb
"""G2 LFSR: polynomial x^10+x^9+x^8+x^6+x^3+x^2+1, all-ones init."""
reg = np.ones(10, dtype=np.int8)
G2 = np.empty(num_chips, dtype=np.int8)
for i in range(num_chips):
G2[i] = reg[9]
fb = reg[1]^reg[2]^reg[5]^reg[7]^reg[8]^reg[9] # taps 2,3,6,8,9,10
reg = np.roll(reg, 1)
reg[0] = fb
# 1023-chip C/A PRN code for SV sv (1-32) as float32, 1's and -1's, so BPSK
def make_prn(sv: int) -> np.ndarray:
g2_delayed = np.roll(G2, G2_DELAY[sv - 1])
bits = G1 ^ g2_delayed # {0, 1}
return (1 - 2 * bits).astype(np.float32) # BPSK: {+1, −1}
def upsample_prn(sv: int) -> np.ndarray:
"""Nearest-neighbour upsample 1023-chip C/A code → samples_per_code samples."""
code = make_prn(sv)
idx = (np.arange(samples_per_code) * num_chips / samples_per_code).astype(int)
return code[idx]
# Pre-compute template signals - conjugate FFTs of all upsampled PRN codes
template_signals = {sv: np.conj(np.fft.fft(upsample_prn(sv))) for sv in gps_svs}
# Read in IQ file
n_needed = samples_per_code * num_integrations
iq = np.fromfile(filename, dtype=np.complex64, count=n_needed)
# For the full version from IQEngine use the following instead
#iq = np.fromfile(filename, dtype=np.int16, count=n_needed * 2)
#iq = (iq[0::2] + 1j * iq[1::2]).astype(np.complex64)
# Loop through satellites performing acquisition
results = []
detected = []
print(f" {'SV':>3} {'Doppler (Hz)':>13} {'Phase (chips)':>14}"
f" {'Phase (samp)':>13} {'Delay (µs)':>11} {'PMR (dB)':>9}")
doppler_bins = np.arange(doppler_min_hz, doppler_max_hz + doppler_step_hz, doppler_step_hz)
for sv in gps_svs:
corr_map = np.zeros((len(doppler_bins), samples_per_code))
n_total = samples_per_code * num_integrations
for di, f_d in enumerate(doppler_bins):
t = np.arange(n_total) / sample_rate # time vector
mixed = iq[:n_total] * np.exp(-2j*np.pi*float(f_d)*t) # freq shift
# Non-coherent integration: accumulate squared correlation magnitude
for k in range(num_integrations):
blk = mixed[k * samples_per_code:(k + 1) * samples_per_code]
sig_fft = np.fft.fft(blk)
corr = np.fft.ifft(sig_fft * template_signals[sv]) # cross-correlation in freq domain
corr_map[di] += np.abs(corr)**2
# Normalize by mean and convert to dB
peak_val = float(np.max(corr_map))
mean_val = float(np.mean(corr_map))
pmr_db = 10.0 * np.log10(peak_val / mean_val)
peak_idx = np.unravel_index(np.argmax(corr_map), corr_map.shape)
best_doppler_hz = float(doppler_bins[peak_idx[0]])
best_phase_samp = int(peak_idx[1])
best_phase_chips = best_phase_samp * num_chips / samples_per_code
r = {
"sv": sv,
"detected": pmr_db >= detection_thresh_dB,
"doppler_hz": best_doppler_hz,
"code_phase_samp": best_phase_samp, # sample offset = "start of packet"
"code_phase_chip": best_phase_chips,
"pmr_db": pmr_db,
"corr_map": corr_map,
"doppler_bins": doppler_bins,
}
results.append(r)
# Print row
delay_us = r['code_phase_samp'] / sample_rate * 1e6
flag = " ← DETECTED" if r['detected'] else ""
print(f" {sv:>3} {r['doppler_hz']:>+13.0f} {r['code_phase_chip']:>14.2f}"
f" {r['code_phase_samp']:>13d} {delay_us:>11.3f} {r['pmr_db']:>9.1f}{flag}")
Dit zou de volgende uitvoer moeten geven:
SV Doppler (Hz) Phase (chips) Phase (samp) Delay (µs) PMR (dB)
1 -3000 757.79 2963 740.750 5.6
2 +1500 264.19 1033 258.250 9.1
3 -2000 316.62 1238 309.500 5.8
4 +5000 577.48 2258 564.500 5.0
5 +1000 64.96 254 63.500 5.3
6 +1500 511.76 2001 500.250 5.0
7 -4000 763.41 2985 746.250 5.0
8 +3500 961.62 3760 940.000 5.4
9 +3500 118.67 464 116.000 4.9
10 +0 890.52 3482 870.500 5.4
11 +2500 837.33 3274 818.500 14.6 ← GEDETECTEERD
12 -500 871.60 3408 852.000 16.4 ← GEDETECTEERD
13 +1000 137.85 539 134.750 5.9
14 +2500 287.72 1125 281.250 5.0
15 -5000 908.68 3553 888.250 5.3
16 +1500 292.58 1144 286.000 5.9
17 +500 994.61 3889 972.250 5.3
18 +4500 1005.61 3932 983.000 5.4
19 +5000 588.48 2301 575.250 5.0
20 +0 768.53 3005 751.250 5.4
21 -3000 749.60 2931 732.750 5.0
22 +2500 558.05 2182 545.500 14.4 ← GEDETECTEERD
23 -5000 390.02 1525 381.250 5.3
24 +2500 955.48 3736 934.000 5.9
25 +1500 597.94 2338 584.500 15.5 ← GEDETECTEERD
26 -1500 239.89 938 234.500 6.2
27 -2500 488.74 1911 477.750 4.7
28 +3000 858.81 3358 839.500 5.2
29 -4000 998.70 3905 976.250 5.2
30 -2000 937.58 3666 916.500 5.2
31 +5000 463.42 1812 453.000 15.9 ← GEDETECTEERD
32 +1000 342.45 1339 334.750 16.2 ← GEDETECTEERD
Zoals je ziet detecteren we 6 satellieten. Hoewel onze drempel op 14.0 staat, kun je uit de lijst vrij duidelijk afleiden dat de meeste andere satellieten niet zichtbaar waren, met mogelijk uitzondering van SV-2, die waarschijnlijk net onder de drempel bleef. Voor wie dit wil verifiëren: de opname is gemaakt op 2022-03-27T11:32:04 ergens in Spanje.
Plotten¶
Laten we de resultaten van satelliet 11, de eerste die we detecteerden, plotten. De eerste plot is de 2D-correlatiekaart over Doppler en tijd/delay. De tweede plot is een doorsnede van die correlatiekaart bij de beste Doppler-bin, en toont correlatievermogen over de tijd zoals in de vorige sectie.
# Plotting
sv = 11 # we detected 11, 12, 22, 25, 31, 32 although try looking at one we didnt find as well!
r = results[sv - 1] # print the dict of results for this SV to see what we got
cmap = r['corr_map'] # 2-D array of correlation power vs Doppler and code phase
d_bins = r['doppler_bins'] # Doppler bins corresponding
chips_axis = np.arange(samples_per_code) * num_chips / samples_per_code
# 2-D Doppler × code-phase map
plt.figure(0, figsize=(10, 6))
im = plt.pcolormesh(chips_axis, d_bins, cmap, shading='auto', cmap='viridis')
plt.xlabel("Code Phase (chips)")
plt.ylabel("Doppler (Hz)")
plt.title(f"SV {sv} — 2-D Acquisition Map (PMR = {r['pmr_db']:.1f} dB)")
plt.legend(fontsize=8, loc='upper right')
plt.colorbar(im, label="Correlation Power")
# code-phase slice at best Doppler
best_di = int(np.argmin(np.abs(d_bins - r['doppler_hz'])))
plt.figure(1, figsize=(10, 6))
plt.plot(chips_axis, cmap[best_di], lw=1, color='steelblue')
plt.xlabel("Code Phase (chips)")
plt.ylabel("Correlation Power")
plt.title(f"SV {sv} — Code-Phase Slice (Doppler = {r['doppler_hz']:+.0f} Hz)")
plt.legend(fontsize=8)
plt.grid(True, alpha=0.3)
plt.show()
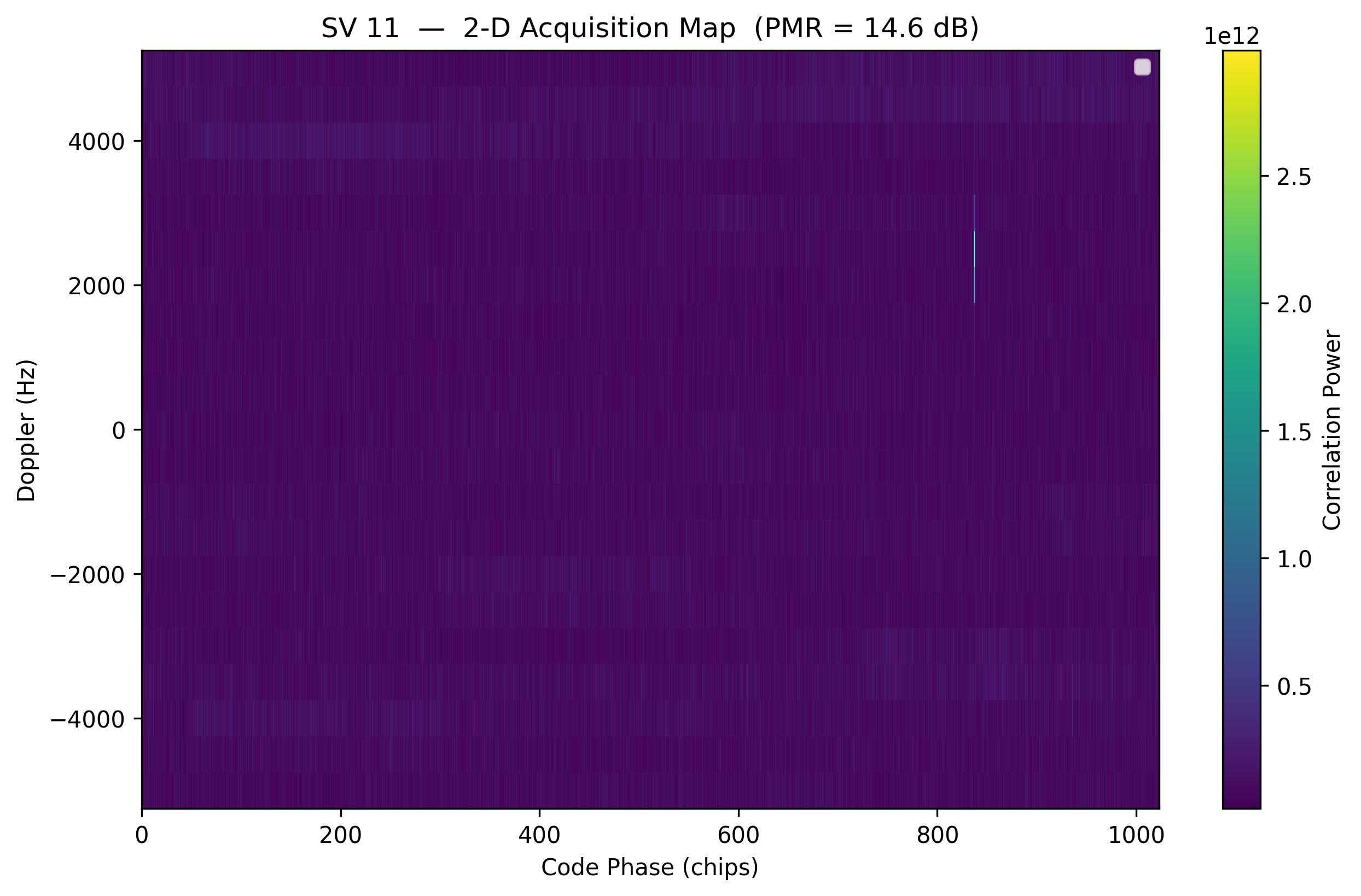

We gaan hier niet dieper in op het trilateratieproces, maar juist de exacte positie van die piek maakt het mogelijk om de afstand tot de satelliet te bepalen. Combineer je die informatie van 4 of meer satellieten, dan kan de ontvanger zijn positie op aarde berekenen.
21.3. CFAR-detectors: Robuust in Veranderende Omgevingen¶
Hoewel de Neyman-Pearson-detector optimaal is bij een vaste ruisvloer, zijn praktijkomstandigheden zelden zo stabiel. In een dynamische omgeving, zoals radar door regen of een draadloze ontvanger in een drukke stad, schommelen achtergrondruis en interferentie voortdurend. Hier wordt een Constant False Alarm Rate (CFAR)-detector essentieel.
CFAR-detectors zijn de werkpaarden van systemen waar een onvoorspelbare achtergrond een vaste drempel onbruikbaar maakt:
- Radar en sonar detecteren doelen (vliegtuigen, onderzeeers) tegen “clutter”: reflecties van golven, regen of land die veranderen terwijl de sensor beweegt.
- Draadloze communicatie, zoals cognitieve radio en LTE/5G-systemen, gebruikt CFAR om beschikbaar spectrum te vinden of inkomende pakketten te detecteren bij grillige interferentie van andere apparaten.
- Medische beeldvorming gebruikt CFAR in automatische analyse van echo- of MRI-data om echte weefselstructuren te onderscheiden van variërende elektronische ruis.
De “C” in CFAR staat voor Constant, omdat het doel is om de vals-alarmkans (\(P_{FA}\)) op een stabiel, voorspelbaar niveau te houden.
Om een drempelwaarde te kiezen, moet je een statistisch ruismodel aannemen (de ruisverdeling). In eenvoudige AWGN is dat een Gauss-verdeling. In radarclutter kan het bijvoorbeeld een Rayleigh- of Weibull-verdeling zijn. Als je model niet klopt, gaat \(P_{FA}\) “driften”, waardoor het systeem óf blind wordt óf overspoeld raakt door valse triggers.
In plaats van een vaste waarde schat een CFAR-detector het ruisvermogen in de lokale “omgeving” van het signaal en vermenigvuldigt die schatting met een schaalfactor (\(T\)) afgeleid van de gewenste \(P_{FA}\). Daardoor stijgt de drempel automatisch mee als de ruisvloer stijgt.
Per-lag versus Systeemniveau Vals-alarmkans¶
Dit is een cruciaal onderscheid dat beginners vaak missen. Bij preamble-zoekacties voer je meestal een schuivende correlatie uit, waarbij je de drempel op duizenden tijdsverschuivingen (“lags”) per seconde controleert.
Per-lag \(P_{FA}\): de kans dat één specifieke correlatietoets een vals alarm oplevert. Stel je \(P_{FA}\) op 0,001, dan heeft elke losse lag 1 op 1000 kans op een “spooksignaal”.
Systeemniveau (globaal) \(P_{FA}\): de kans dat het systeem minstens één vals alarm geeft in een volledig zoekvenster (bijv. over 2048 lags).
Wiskundig geldt: als je per-lag \(P_{FA}\) gelijk is aan \(p\), dan is de kans op minstens één vals alarm over \(N\) lags ongeveer \(1-(1-p)^{N}\).
Gevolg: bij 1000 lags en per-lag \(P_{FA}\) van 0,001 rapporteert het systeem in bijna 63% van de zoekacties minstens één vals alarm. Om de systeemniveau-kans laag te houden moet per-lag \(P_{FA}\) dus extreem klein zijn.
Python-voorbeeld¶
Om zelf met een CFAR-detector te experimenteren, simuleren we eerst een scenario met herhaalde QPSK-pakketten met bekende preamble over een kanaal met tijdsvariërende ruisvloer. Daarna implementeren we een eenvoudige Cell-Averaging CFAR (CA-CFAR)-detector om preambles in het ontvangen signaal te vinden. De volgende Python-code genereert het ontvangen signaal:
import numpy as np
import matplotlib.pyplot as plt
from scipy.signal import correlate
def generate_qpsk_packets(num_packets, sps, preamble):
"""Generates repeating QPSK packets with gaps and varying noise."""
qpsk_map = np.array([1+1j, -1+1j, -1-1j, 1-1j]) / np.sqrt(2)
data_len = 200
gap_len = 100
full_signal = []
# Pre-calculate preamble upsampled for correlation
upsampled_preamble = np.repeat(preamble, sps)
for _ in range(num_packets):
data = qpsk_map[np.random.randint(0, 4, data_len)]
packet = np.concatenate([preamble, data])
full_signal.extend(np.repeat(packet, sps))
full_signal.extend(np.zeros(gap_len * sps))
return np.array(full_signal), upsampled_preamble
# Setup Parameters
sps = 4
preamble_syms = np.array([1+1j, 1+1j, -1-1j, -1-1j, 1-1j, -1+1j]) / np.sqrt(2)
tx_signal, ref_preamble = generate_qpsk_packets(5, sps, preamble_syms)
# Channel: Time-Varying Noise Floor
t = np.arange(len(tx_signal))
noise_env = 0.05 + 0.3 * np.sin(2 * np.pi * 0.0003 * t)**2
noise = (np.random.randn(len(tx_signal)) + 1j*np.random.randn(len(tx_signal))) * noise_env
rx_signal = tx_signal + noise
De eerste stap is één correlatie van het ontvangen signaal met de bekende preamble. In de praktijk gebeurt dit vaak in batches, maar hier doen we het in één batch:
# Preamble-correlatie, een correlatiepiek ontstaat wanneer referentie en ontvangen segment matchen
corr_out = correlate(rx_signal, ref_preamble, mode='same')
corr_power = np.abs(corr_out)**2
TODO: kijk naar de ruwe output van alleen deze stap
Nu implementeren we de CFAR-detector, passen die toe op de correlatoruitgang en visualiseren de resultaten:
# CFAR Detection on Correlator Output
def ca_cfar_adaptive(data, num_train, num_guard, pfa):
num_cells = len(data)
thresholds = np.zeros(num_cells)
alpha = num_train * (pfa**(-1/num_train) - 1) # Scaling factor
half_window = (num_train + num_guard) // 2
guard_half = num_guard // 2
for i in range(half_window, num_cells - half_window):
# Extract training cells (excluding guard cells and CUT)
lagging_win = data[i - half_window : i - guard_half]
leading_win = data[i + guard_half + 1 : i + half_window + 1]
noise_floor_est = np.mean(np.concatenate([lagging_win, leading_win]))
thresholds[i] = alpha * noise_floor_est
return thresholds
# Detect on correlator power
cfar_thresholds = ca_cfar_adaptive(corr_power, num_train=60, num_guard=20, pfa=1e-5)
detections = np.where(corr_power > cfar_thresholds)[0]
# Filter detections to only include those where threshold is non-zero (avoid edges)
detections = detections[cfar_thresholds[detections] > 0]
# Subplot 1: Received Signal and Raw Power
plt.figure(figsize=(14, 8))
plt.subplot(2, 1, 1)
plt.plot(np.abs(rx_signal)**2, color='gray', alpha=0.4, label='Rx Signal Power ($|r(t)|^2$)')
plt.title("Time-Domain Received Signal")
plt.ylabel("Power")
plt.legend()
plt.grid(True, alpha=0.3)
# Subplot 2: Correlator Output vs Adaptive Threshold
plt.subplot(2, 1, 2)
plt.plot(corr_power, label='Correlator Output $|r(t) * p^*(-t)|^2$', color='blue')
plt.plot(cfar_thresholds, label='CFAR Adaptive Threshold', color='red', linestyle='--', linewidth=1.5)
if len(detections) > 0: # Overlay detections
plt.scatter(detections, corr_power[detections], color='lime', edgecolors='black', label='Detections (Preamble Found)', zorder=5)
plt.title("Preamble Correlator Output with Adaptive CFAR Threshold")
plt.xlabel("Sample Index")
plt.ylabel("Correlation Power")
plt.legend()
plt.grid(True, alpha=0.3)
plt.show()

Frequentie-offset-robuuste Preamble-correlators¶
Het detecteren van een preamble wordt een meerdimensionaal zoekprobleem wanneer de middenfrequentie onbekend is. In een perfect gesynchroniseerd systeem werkt een coherente correlator als matched filter en maximaliseert die de SNR. Frequentie-offset introduceert echter een tijdsafhankelijke faserotatie die het signaal loskoppelt van het lokale sjabloon, met potentieel dramatisch verlies van detectiegevoeligheid als gevolg.
De impact van frequentie-offset \(\Delta f\) hangt af van de grootte ervan ten opzichte van de preambleduur (\(T_{p}\)):
Licht verschoven (Doppler/clock drift): meestal veroorzaakt door ppm-onnauwkeurigheid van de lokale oscillator (LO) of beweging met lage snelheid. Hier geldt \(\Delta f \cdot T_{p} \ll 1\). De correlatiepiek verzwakt iets, maar de timing is nog steeds terug te winnen.
In gevallen waar de frequentie-offset volledig onbekend is, zoals bij “cold start”-satellietacquisitie of sterk dynamische UAV-links, kan de coherente som zelfs naar nul uitdoven als de fase over de preamble meer dan \(180^{\circ}\) roteert (\(\Delta f > 1/(2T_{p})\)). Detectie wordt dan praktisch onmogelijk, ongeacht de SNR.
Het verlies in correlatiemagnitude door frequentie-offset wordt beschreven door de Dirichlet-kern (de periodieke sinc-functie). Naarmate de frequentie-offset toeneemt, volgt de coherente som van geroteerde vectoren deze sinc-achtige afrol.
Het verlies in dB door frequentie-offset kan benaderd worden met:
\(L_{dB}(\Delta f) = 20 \log_{10} \left| \frac{\sin(\pi \Delta f N T_{s})}{N \sin(\pi \Delta f T_{s})} \right|\)
Waarbij:
- \(N\): aantal symbolen in de preamble.
- \(T_{s}\): symboolperiode.
- \(\Delta f\): frequentie-offset in Hz.
Als \(\Delta f\) toeneemt, oscilleert de teller terwijl de noemer groeit, waardoor “nullen” in de gevoeligheid ontstaan. Voor een standaard correlator ligt de eerste nul bij \(\Delta f = 1/(N T_{s})\). Zit je offset op een halve binbreedte, dan verlies je ongeveer 3,9 dB, wat je effectieve SNR en \(P_{d}\) merkbaar verslechtert.
Methoden voor Robuustheid tegen Frequentie-offset¶
- Coherente Gesegmenteerde Correlator
De preamble met lengte \(N\) wordt opgesplitst in \(M\) segmenten van lengte \(L = N/M\). Elk segment wordt coherent gecorreleerd, waarna de resultaten worden gecombineerd met compensatie voor de fasedrift tussen segmenten.
\(Y_{coh} = \sum_{m=0}^{M-1} \left( \sum_{k=0}^{L-1} r[k+mL] \cdot p^{*}[k] \right) e^{-j \hat{\phi}_m}\)
Hierbij is \(\hat{\phi}_m\) een schatting van de faserotatie voor dat segment. Dit behoudt de SNR-gain van een preamble over volledige lengte, maar vraagt een nauwkeurige frequentieschatting om fasen goed uit te lijnen.
- Niet-coherente Gesegmenteerde Correlator
Segmenten worden coherent gecorreleerd, maar de magnitudes worden opgeteld, waarbij fase-informatie wordt weggegooid.
\(Y_{non-coh} = \sum_{m=0}^{M-1} \left| \sum_{k=0}^{L-1} r[k+mL] \cdot p^{*}[k] \right|^{2}\)
Deze aanpak is zeer robuust tegen frequentie-offset (tot ongeveer \(1/(L T_{s})\)). Nadeel is Non-Coherent Integration Loss. Door magnitudes op te tellen in plaats van complexe waarden stapelt ruis sneller op dan signaal, wat de “post-detection” SNR effectief verlaagt.
- Brute-force Frequentiezoektocht
De ontvanger draait meerdere parallelle correlators, elk verschoven met een discrete frequentie \(\Delta f_{i}\).
Deze methode biedt de beste SNR-prestatie (volledige coherente gain), maar is ook het meest rekentechnisch kostbaar. De “bin spacing” moet klein genoeg zijn (volgens de Dirichlet-formule) zodat het worst-case verlies tussen bins acceptabel blijft (bijv. < 1 dB).
Bij time-domain tapping worden samples geconvolueerd met een vaste set gewichten. Voor een frequentiezoekactie heb je dan een aparte FIR-bank per frequentiebin nodig. Dat is efficiënt voor korte preambles op FPGA’s met Xilinx DSP48-slices. Frequentiedomeinverwerking (FFT): voor een zoekactie neem je de FFT van het inkomende signaal en de preamble. Vermenigvuldiging in het frequentiedomein is equivalent aan correlatie. De “frequency shift trick”: om verschillende frequentie-offsets te testen heb je geen meerdere FFT’s nodig. Je kunt de FFT-bins van de preamble circulair verschuiven ten opzichte van het signaal vóór puntsgewijze vermenigvuldiging en IFFT. Voor continue stromen gebruik je chunkmethoden zoals Overlap-Save of Overlap-Add, zodat correlatiepieken aan de randen van FFT-vensters niet verloren gaan.
Robuustheid tegen frequentie-offset is een afruil tussen processing gain en rekentechnische complexiteit. Niet-coherente gesegmenteerde correlatie is het meest robuust in omgevingen met veel onzekerheid, maar vraagt een hogere linkmarge. Coherente segmentmethoden en brute-force FFT-zoekacties bieden betere gevoeligheid, maar vereisen aanzienlijk meer hardwarebronnen. Begrijpen hoe het Dirichlet-verlies werkt is cruciaal om de benodigde “bin density” van een frequentiezoekende ontvanger te bepalen.
TODO: Licht deze figuur toe en voeg een relevant stuk Python toe aan deze sectie

21.4. DSSS-signalen (Direct Sequence Spread Spectrum) Detecteren¶
In een DSSS-systeem is de correlator-detector de vitale schakel die een bruikbaar signaal uit schijnbaar willekeurige ruis haalt. Met een chipsequentie op hoge snelheid (“chipping code”) spreidt het systeem de signaalenergie over een veel bredere band dan de oorspronkelijke data nodig heeft. Omdat het totale vermogen gelijk blijft, daalt de vermogensspectrale dichtheid (PSD) sterk. Dit “spectraal verdunnen” kan het signaal onder de thermische ruisvloer brengen, waardoor het voor klassieke smalbandontvangers bijna onzichtbaar wordt. Voor buitenstaanders lijkt het op achtergrondruis, maar de bedoelde ontvanger gebruikt dezelfde chipsequentie om te “ontspreiden”, waardoor de energie terug samenkomt in de oorspronkelijke smalle band en smalbandinterferentie juist uitgesmeerd wordt. Dat maakt betrouwbare detectie mogelijk, zelfs in zeer ruisrijke omstandigheden.
De Rol van Autocorrelatie-eigenschappen¶
De juiste sequentie kiezen is cruciaal voor synchronisatie en multipad-onderdrukking. Idealiter heeft een sequentie perfecte autocorrelatie: een hoge piek bij perfecte uitlijning en bijna nul op alle andere tijdsverschuivingen. Scherpe autocorrelatiepieken laten de ontvanger locken met sub-chip timingnauwkeurigheid. Als een signaal via een reflectie later binnenkomt, zorgt goede autocorrelatie dat de ontvanger die vertraagde kopie als ongecorreleerde ruis behandelt in plaats van destructieve interferentie.
Veelgebruikte Spreidingssequenties¶
Verschillende toepassingen vragen verschillende wiskundige eigenschappen van hun sequenties. Voorbeelden zijn:
- Barker-codes, bekend om de best mogelijke autocorrelatie bij korte lengtes (tot 13), en klassiek gebruikt in 802.11b-wifi.
- M-sequenties (maximale lengte), opgewekt met linear-feedback shift registers (LFSR’s), bieden uitstekende pseudo-willekeurigheid en autocorrelatie over lange periodes.
- Gold-codes, afgeleid van paren m-sequenties, leveren een grote set sequenties met gecontroleerde kruiscorrelatie, en zijn daarom standaard in GPS en CDMA met meerdere gelijktijdige signalen.
- Zadoff-Chu (ZC)-sequenties, complexwaardig met constante amplitude en nul autocorrelatie voor alle niet-nul shifts, zijn nu een hoeksteen van LTE en 5G-synchronisatie.
- Kasami-codes, vergelijkbaar met Gold-codes maar vaak met nog lagere kruiscorrelatie bij gegeven lengte, nuttig in hoge-dichtheidsomgevingen.
Chip-timing-synchronisatie in DSSS¶
In een DSSS-systeem hangt het kunnen terughalen van data volledig af van synchronisatie met de inkomende chipsequentie. Omdat chips veel korter zijn dan databits kan zelfs een kleine fractionele timingfout, waarbij de ontvanger “tussen” chips samplet, de correlatiepiek sterk verlagen. We verkennen dit effect met een simpele DSSS-simulatie en plotten de correlatie-output terwijl we de timing-offset variëren van 0 tot 1 chip. Let op: we doen hier geen volledige correlatie, maar een dotproduct bij lag 0, omdat we weten dat daar de piek hoort te zitten.
import numpy as np
import matplotlib.pyplot as plt
# Barker 11 sequence: +1, -1, +1, +1, -1, +1, +1, +1, -1, -1, -1
barker11 = np.array([1, -1, 1, 1, -1, 1, 1, 1, -1, -1, -1])
samples_per_chip = 100
# Upsample the sequence to simulate continuous-ish time
sig = np.repeat(barker11, samples_per_chip)
offsets = np.linspace(-1.5, 1.5, 500) # Fractional chip offsets
peaks = []
for offset in offsets:
# Shift the signal by a fractional number of chips (converted to samples)
shift_samples = int(offset * samples_per_chip)
if shift_samples > 0:
shifted_sig = np.pad(sig, (shift_samples, 0))[:len(sig)]
elif shift_samples < 0:
shifted_sig = np.pad(sig, (0, abs(shift_samples)))[abs(shift_samples):]
else:
shifted_sig = sig
# Compute normalized correlation at zero lag for this specific offset
correlation = np.vdot(sig, shifted_sig) / np.vdot(sig, sig)
peaks.append(np.abs(correlation))
plt.figure(figsize=(10, 5))
plt.plot(offsets, peaks, label='Normalized Correlation', color='blue', linewidth=2)
plt.axvline(0, color='red', linestyle='--', alpha=0.5, label='Perfect Alignment')
plt.title('DSSS Correlation Peak vs. Fractional Chip Timing Offset')
plt.xlabel('Offset (Fraction of a Chip)')
plt.ylabel('Normalized Correlation Peak Magnitude')
plt.grid(True, which='both', linestyle='--', alpha=0.6)
plt.legend()
plt.savefig('../_images/detection_dsss.svg', bbox_inches='tight')
plt.show()

De piek ligt zoals verwacht bij offset nul en daalt ongeveer lineair; bij een halve chip-offset zit je rond de helft van de piekwaarde. Na meer dan één chip-offset kan het lijken alsof de correlatie weer stijgt, maar de echte piek blijft laag omdat de uitlijning met de sequentie dan weg is.
21.5. Realtime Pakketdetectie in Continue IQ-stromen¶
Tot nu toe hebben we de theoretische basis van signaaldetectie verkend, van correlators via CFAR-detectors tot spread-spectrumsystemen. Nu brengen we alles samen voor een veelvoorkomend praktijkprobleem: pakketten detecteren in een continue stroom IQ-samples van een SDR. Stel je dit scenario voor: een modem of IoT-apparaat verstuurt eens per seconde (of onregelmatig) een datapakket. Je SDR ontvangt continu samples, bijvoorbeeld op 1 MHz. Pakketten komen op onvoorspelbare momenten binnen, verborgen in ruis en interferentie. Je moet:
- Detecteren wanneer een pakket aankomt
- De exacte sample-index bepalen waar het start
- Het pakket uitknippen voor verdere verwerking (demodulatie, decodering, enz.)
- Dit realtime doen zonder pakketten te missen
Dit is fundamenteel anders dan een vooraf opgenomen IQ-bestand verwerken, waarbij je het hele signaal in één keer kunt analyseren. Hier komen samples continu binnen en moet je met beperkte rekenmiddelen realtime beslissingen nemen. We combineren hiervoor meerdere technieken uit dit hoofdstuk:
- Kruiscorrelatie: om het bekende preamblepatroon te vinden
- CFAR-detectie: om drempels adaptief te zetten bij variërende ruis
- Bufferbeheer: om continue streamdata af te handelen
- Piekdetectie: om precieze pakkettiming te bepalen
Om realtime te kunnen werken verzamelen we samples in buffers (bijvoorbeeld chunks van 100.000 samples), draaien de detector op elke buffer en houden toestand bij over buffergrenzen heen, zodat pakketten die twee buffers overspannen niet gemist worden.
Implementatie¶
Onze detector volgt deze workflow:
flowchart TD
A("Continue IQ-stroom van SDR <br/>(1 MHz sample rate)")
B("Buffer-opbouw <br/> (bijv. 100k samples = 0,1 s)")
C("Kruiscorrelatie met bekende preamble")
D("CFAR-drempelberekening")
E("Piekdetectie<br/>(correlatie > drempel)")
F("Pakketextractie & validatie")
A --> B --> C --> D --> E --> F
Om pakketten die over buffergrenzen gaan niet te missen gebruiken we een overlap-save-aanpak, waarbij elke buffer de laatste N_preamble samples van de vorige buffer bevat. Zo zit elk pakket dat aan het einde van buffer i start volledig in buffer i+1. Dat kost iets extra rekentijd, maar voorkomt gemiste pakketten op buffergrenzen.
Laten we stap voor stap een complete pakketdetector in Python bouwen. We gebruiken een Zadoff-Chu-preamble zoals eerder, maar korter, en implementeren een adaptieve CFAR-detector.
Stap 1: Definieer de Preamble en Parameters¶
import numpy as np
import matplotlib.pyplot as plt
from scipy.signal import correlate
# Preamble: Zadoff-Chu sequence (excellent correlation properties)
N_zc = 63 # ZC sequence length (typically prime or power of 2 - 1)
u = 5 # ZC root
t = np.arange(N_zc)
preamble = np.exp(-1j * np.pi * u * t * (t + 1) / N_zc)
# System parameters
sample_rate = 1e6
buffer_size = 100000
overlap_size = len(preamble) # Overlap to catch boundary packets
# CFAR parameters
cfar_guard = 10
cfar_train = 50
pfa_target = 1e-6
# Packet parameters (for simulation)
packet_length = 500 # Total packet length in samples (preamble + data)
snr_db = -5
Stap 2: CFAR-detectorfunctie¶
We gebruiken de Cell-Averaging CFAR (CA-CFAR) van eerder, licht geoptimaliseerd:
def ca_cfar_1d(signal, num_train, num_guard, pfa):
"""
1D Cell-Averaging CFAR detector.
Args:
signal: Input signal (typically correlation magnitude)
num_train: Number of training cells (on each side)
num_guard: Number of guard cells (on each side)
pfa: Target probability of false alarm
Returns:
threshold: Adaptive threshold array
"""
n = len(signal)
threshold = np.zeros(n)
alpha = num_train * (pfa**(-1/num_train) - 1)
for i in range(n):
# Define training window indices
train_start_left = max(0, i - num_guard - num_train)
train_end_left = max(0, i - num_guard)
train_start_right = min(n, i + num_guard + 1)
train_end_right = min(n, i + num_guard + num_train + 1)
# Collect training cells (avoid guard cells and CUT)
train_cells = np.concatenate([
signal[train_start_left:train_end_left],
signal[train_start_right:train_end_right]
])
if len(train_cells) > 0:
noise_est = np.mean(train_cells)
threshold[i] = alpha * noise_est
return threshold
Stap 3: Pakketdetectiefunctie¶
def detect_packets(buffer, preamble, cfar_guard, cfar_train, pfa,
min_spacing=None):
"""
Detect packets in a buffer of IQ samples.
Args:
buffer: Complex IQ samples
preamble: Known preamble sequence
cfar_guard: CFAR guard cells
cfar_train: CFAR training cells
pfa: Target false alarm probability
min_spacing: Minimum samples between detections (prevents duplicates)
Returns:
detections: List of sample indices where packets start
"""
# Correlate buffer with preamble
corr = correlate(buffer, preamble, mode='same')
corr_power = np.abs(corr)**2
# Compute adaptive threshold
threshold = ca_cfar_1d(corr_power, cfar_train, cfar_guard, pfa)
# Find peaks above threshold
detections_raw = np.where(corr_power > threshold)[0]
# Compensate for correlation offset (peak occurs at len(preamble)//2 after true start)
half_preamble = len(preamble) // 2
detections_raw = detections_raw - half_preamble
# Remove edge detections (unreliable)
half_preamble = len(preamble) // 2
detections_raw = detections_raw[
(detections_raw > half_preamble) &
(detections_raw < len(buffer) - half_preamble)
]
# Remove duplicate detections (peaks close together)
if min_spacing is None:
min_spacing = len(preamble)
detections = []
if len(detections_raw) > 0:
detections.append(detections_raw[0])
for det in detections_raw[1:]:
if det - detections[-1] > min_spacing:
detections.append(det)
return detections, corr_power, threshold
Stap 4: Simulatie - Genereer Testsignaal¶
def generate_packet_stream(preamble, packet_length, num_packets,
sample_rate, snr_db):
"""
Generate a simulated IQ stream with intermittent packets.
Returns:
signal: Complex IQ samples
true_starts: Ground truth packet start indices
"""
# Calculate noise power from SNR
signal_power = 1.0 # Normalized preamble power
noise_power = signal_power / (10**(snr_db/10))
noise_std = np.sqrt(noise_power / 2) # Complex noise
# Generate QPSK data (random payload after preamble)
qpsk_map = np.array([1+1j, -1+1j, -1-1j, 1-1j]) / np.sqrt(2)
# Time between packets (1 second +/- 20% jitter)
packets_per_sec = 1
avg_gap = int(sample_rate / packets_per_sec)
signal = []
true_starts = []
for i in range(num_packets):
# Add gap (noise only)
if i == 0:
gap_length = np.random.randint(avg_gap//2, avg_gap)
else:
gap_length = np.random.randint(int(avg_gap*0.8), int(avg_gap*1.2))
noise = noise_std * (np.random.randn(gap_length) +
1j*np.random.randn(gap_length))
signal.extend(noise)
# Record true packet start
true_starts.append(len(signal))
# Add packet (preamble + data)
data_length = packet_length - len(preamble)
data = qpsk_map[np.random.randint(0, 4, data_length)]
packet = np.concatenate([preamble, data])
# Add noise to packet
packet_noisy = packet + noise_std * (np.random.randn(len(packet)) +
1j*np.random.randn(len(packet)))
signal.extend(packet_noisy)
# Add final gap
gap_length = np.random.randint(avg_gap//2, avg_gap)
noise = noise_std * (np.random.randn(gap_length) +
1j*np.random.randn(gap_length))
signal.extend(noise)
return np.array(signal), true_starts
# Generate 5 seconds of signal with ~5 packets
signal, true_starts = generate_packet_stream(
preamble, packet_length, num_packets=5,
sample_rate=sample_rate, snr_db=snr_db
)
print(f"Generated {len(signal)} samples ({len(signal)/sample_rate:.1f} sec)")
print(f"True packet starts: {true_starts}")
Stap 5: Detectie in Streaming-modus¶
Nu verwerken we het signaal in stukken en simuleren daarmee realtime streaming:
def process_stream(signal, preamble, buffer_size, overlap_size,
cfar_guard, cfar_train, pfa):
"""
Process continuous IQ stream in buffers (simulates real-time).
Returns:
all_detections: List of detected packet starts (global indices)
"""
all_detections = []
n_samples = len(signal)
current_pos = 0
while current_pos < n_samples:
# Define buffer with overlap
buffer_start = max(0, current_pos - overlap_size)
buffer_end = min(n_samples, current_pos + buffer_size)
buffer = signal[buffer_start:buffer_end]
# Detect packets in this buffer
detections, corr_power, threshold = detect_packets(
buffer, preamble, cfar_guard, cfar_train, pfa
)
# Convert buffer-relative indices to global indices
for det in detections:
global_idx = buffer_start + det
# Avoid duplicate detections from overlap region
if len(all_detections) == 0 or \
global_idx - all_detections[-1] > len(preamble):
all_detections.append(global_idx)
current_pos += buffer_size
return all_detections
detected_starts = process_stream(
signal, preamble, buffer_size, overlap_size,
cfar_guard, cfar_train, pfa_target
)
print(f"\nDetection Results:")
print(f"True packets: {len(true_starts)}")
print(f"Detected packets: {len(detected_starts)}")
print(f"Detected starts: {detected_starts}")
Stap 6: Evalueer Prestaties¶
# Calculate detection statistics
tolerance = len(preamble)
matched_detections = []
false_alarms = []
for det in detected_starts:
# Check if detection matches any true packet
matched = False
for true_start in true_starts:
if abs(det - true_start) <= tolerance:
matched_detections.append(det)
matched = True
break
if not matched:
false_alarms.append(det)
missed_packets = len(true_starts) - len(matched_detections)
print(f"\nPerformance Metrics:")
print(f" Correct detections: {len(matched_detections)}/{len(true_starts)}")
print(f" Missed packets: {missed_packets}")
print(f" False alarms: {len(false_alarms)}")
# Calculate timing errors
timing_errors = []
for det in matched_detections:
errors = [abs(det - ts) for ts in true_starts]
timing_errors.append(min(errors))
if len(timing_errors) > 0:
print(f" Timing error (avg): {np.mean(timing_errors):.1f} samples")
print(f" Timing error (max): {np.max(timing_errors):.1f} samples")
Stap 7: Visualiseer Resultaten¶
# Process one buffer for detailed visualization
buffer_start = max(0, true_starts[0] - 5000)
buffer_end = min(len(signal), true_starts[0] + 20000)
viz_buffer = signal[buffer_start:buffer_end]
detections_viz, corr_viz, thresh_viz = detect_packets(
viz_buffer, preamble, cfar_guard, cfar_train, pfa_target
)
# Convert to global indices for plotting
detections_viz_global = [d + buffer_start for d in detections_viz]
# Create visualization
fig, axes = plt.subplots(3, 1, figsize=(14, 10))
time_axis = (np.arange(len(viz_buffer)) + buffer_start) / sample_rate * 1000 # ms
# Subplot 1: Received signal power
axes[0].plot(time_axis, np.abs(viz_buffer)**2, 'gray', alpha=0.6, linewidth=0.5)
axes[0].set_ylabel('Power')
axes[0].set_title('Received IQ Signal Power')
axes[0].grid(True, alpha=0.3)
# Mark true packet locations
for ts in true_starts:
if buffer_start <= ts <= buffer_end:
t_ms = ts / sample_rate * 1000
axes[0].axvline(t_ms, color='green', linestyle='--', alpha=0.7,
label='True Packet' if ts == true_starts[0] else '')
axes[0].legend()
# Subplot 2: Correlation output
axes[1].plot(time_axis, corr_viz, 'blue', linewidth=1, label='Correlation')
axes[1].plot(time_axis, thresh_viz, 'red', linestyle='--', linewidth=1.5,
label='CFAR Threshold')
axes[1].set_ylabel('Correlation Power')
axes[1].set_title('Preamble Correlation with Adaptive CFAR Threshold')
axes[1].grid(True, alpha=0.3)
axes[1].legend()
# Subplot 3: Detections
detection_mask = np.zeros(len(viz_buffer))
for det in detections_viz:
detection_mask[det] = corr_viz[det]
axes[2].plot(time_axis, corr_viz, 'blue', alpha=0.4, linewidth=0.8)
axes[2].scatter(time_axis[detection_mask > 0], detection_mask[detection_mask > 0],
color='lime', edgecolors='black', s=100, zorder=5,
label='Detected Packets')
axes[2].set_xlabel('Time (ms)')
axes[2].set_ylabel('Correlation Power')
axes[2].set_title('Detected Packet Locations')
axes[2].grid(True, alpha=0.3)
axes[2].legend()
plt.tight_layout()
plt.show()
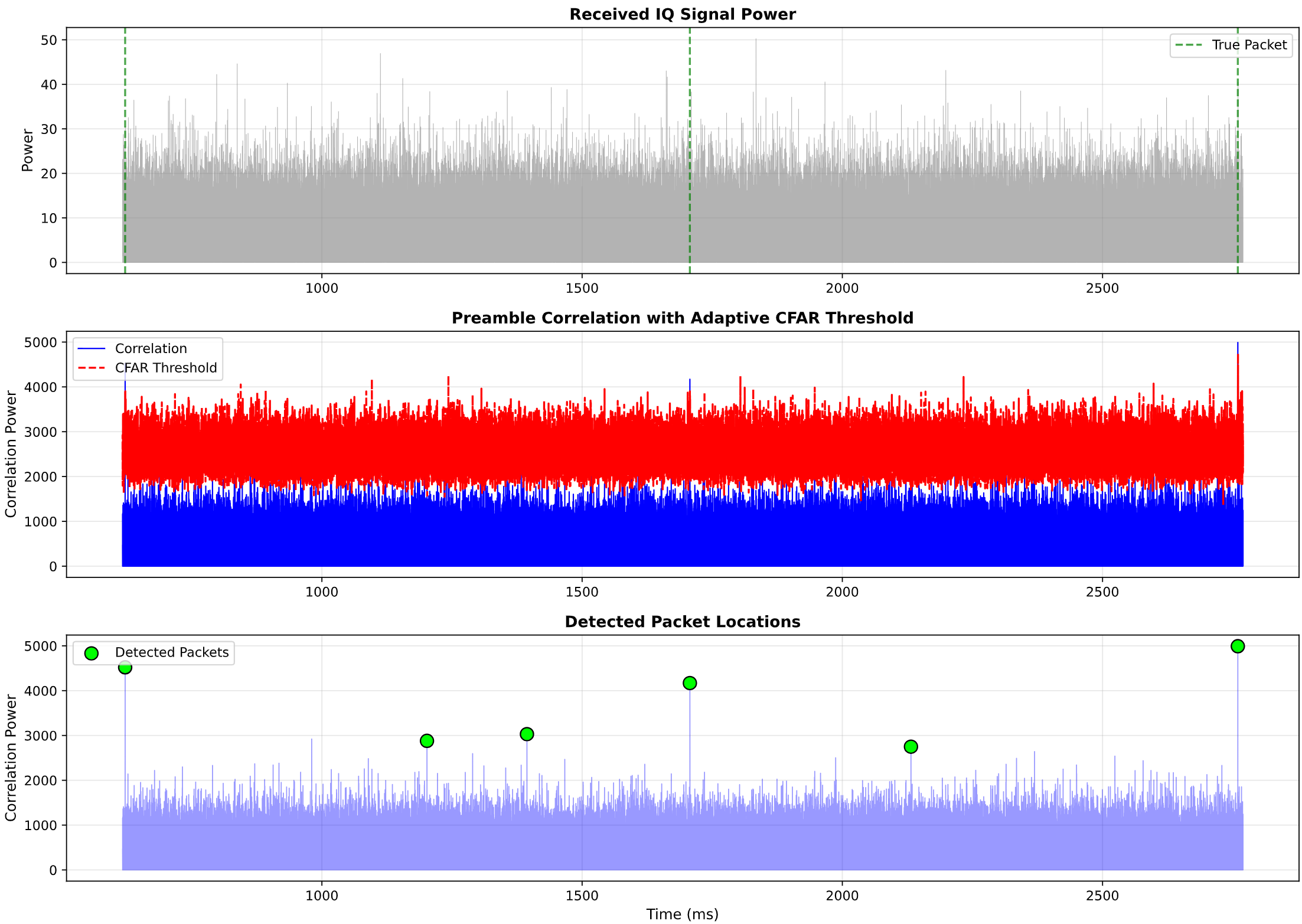
De visualisatie zou het volgende moeten laten zien:
- Bovenste plot: ruwe signaalpower met gemarkeerde echte pakketlocaties
- Middelste plot: correlatie-output met adaptieve CFAR-drempel die de ruisvloer volgt
- Onderste plot: gedetecteerde pakketten gemarkeerd als pieken boven de drempel
Praktische Overwegingen en Tuning¶
Afweging op basis van buffergrootte¶
Grotere buffers (bijv. 1M samples):
- ✅ Betere CFAR-ruisschatting (meer trainingscellen)
- ✅ Lagere rekentechnische overhead (minder functie-aanroepen)
- ❌ Hogere latency (buffer moet eerst gevuld worden)
- ❌ Meer geheugen nodig
Kleinere buffers (bijv. 10k samples):
- ✅ Lagere latency (snellere respons)
- ✅ Minder geheugengebruik
- ❌ CFAR-prestatie verslechtert (minder trainingscellen)
- ❌ Hoger CPU-gebruik (vaker verwerken)
Aanbeveling: begin met buffergrootte = 10× tot 100× je preamblelengte. Voor een preamble van 63 samples bij 1 Msps kun je 10k-100k samples proberen.
CFAR-parametertuning¶
De drie CFAR-parameters bepalen het detectorgedrag:
num_guard (guard-cellen):
- Doel: voorkomt dat signaalenergie in de ruisschatting lekt
- Te klein: signaal lekt in trainingsregio → hogere drempel → gemiste detecties
- Te groot: minder trainingscellen → slechtere ruisschatting
- Vuistregel: zet op ongeveer 0,5 tot 1,0× de preamblelengte
num_train (training-cellen):
- Doel: schat de lokale ruisvloer
- Te klein: ruisachtige drempel → valse alarmen of gemiste detecties
- Te groot: drempel past zich te traag aan ruisveranderingen aan
- Vuistregel: zet op ongeveer 3 tot 5× de preamblelengte
pfa (kans op vals alarm):
- Doel: regelt de detectiegevoeligheid
- Te hoog (bijv. 1e-2): veel valse alarmen
- Te laag (bijv. 1e-10): zwakke pakketten worden gemist
- Vuistregel: start met 1e-5 voor per-lag PFA en stuur bij op basis van vals-alarmkans op systeemniveau
Onthoud de relatie tussen per-lag en systeemniveau vals-alarmkansen uit het eerdere deel van dit hoofdstuk.
