 Online Python Console
Online Python Console One-time Donation
One-time Donation


3. IQ Sampling¶
In this chapter we introduce a concept called IQ sampling, a.k.a. complex sampling or quadrature sampling. We also cover Nyquist sampling, complex numbers, RF carriers, downconversion, and power spectral density. IQ sampling is the form of sampling that an SDR performs, as well as many digital receivers (and transmitters). It’s a slightly more complex version of regular digital sampling (pun intended), so we will take it slow and with some practice the concept is sure to click!
Sampling Basics¶
Before jumping into IQ sampling, let’s discuss what sampling actually means. You may have encountered sampling without realizing it by recording audio with a microphone. The microphone is a transducer that converts sound waves into an electric signal (a voltage level). That electric signal is transformed by an analog-to-digital converter (ADC), producing a digital representation of the sound wave. To simplify, the microphone captures sound waves that are converted into electricity, and that electricity in turn is converted into numbers. The ADC acts as the bridge between the analog and digital domains. SDRs are surprisingly similar. Instead of a microphone, however, they utilize an antenna, although they also use ADCs. In both cases, the voltage level is sampled with an ADC. For SDRs, think radio waves in, numbers out.
Whether we are dealing with audio or radio frequencies, we must sample if we want to capture, process, or save a signal digitally. Sampling might seem straightforward, but there is a lot to it. A more technical way to think of sampling a signal is grabbing values at moments in time and saving them digitally. Let’s say we have some random function, \(S(t)\), which could represent anything, and it’s a continuous function that we want to sample:

We record the value of \(S(t)\) at regular intervals of \(T\) seconds, known as the sample period. The frequency at which we sample, i.e., the number of samples taken per second, is simply \(\frac{1}{T}\). We call this the sample rate, and it’s the inverse of the sample period. For example, if we have a sample rate of 10 Hz, then the sample period is 0.1 seconds; there will be 0.1 seconds between each sample. In practice our sample rates will be on the order of hundreds of kHz to tens of MHz or even higher. When we sample signals, we need to be mindful of the sample rate, it’s a very important parameter.
For those who prefer to see the math; let \(S_n\) represent sample \(n\), usually an integer starting at 0. Using this convention, the sampling process can be represented mathematically as \(S_n = S(nT)\) for integer values of \(n\). I.e., we evaluate the analog signal \(S(t)\) at these intervals of \(nT\).
Nyquist Sampling¶
For a given signal, the big question often is how fast must we sample? Let’s examine a signal that is just a sine wave, of frequency f, shown in green below. Let’s say we sample at a rate Fs (samples shown in blue). If we sample that signal at a rate equal to f (i.e., Fs = f), we will get something that looks like:

The red dashed line in the above image reconstructs a different (incorrect) function that could have led to the same samples being recorded. It indicates that our sample rate was too low because the same samples could have come from two different functions, leading to ambiguity. If we want to accurately reconstruct the original signal, we can’t have this ambiguity.
Let’s try sampling a little faster, at Fs = 1.2f:

Once again, there is a different signal that could fit these samples. This ambiguity means that if someone gave us this list of samples, we could not distinguish which signal was the original one based on our sampling.
How about sampling at Fs = 1.5f:

Still not fast enough! According to a piece of DSP theory we won’t dive into, you have to sample at twice the frequency of the signal in order to remove the ambiguity we are experiencing:

There’s no incorrect signal this time because we sampled fast enough that no signal exists that fits these samples other than the one you see (unless you go higher in frequency, but we will discuss that later).
In the above example our signal was just a simple sine wave, most actual signals will have many frequency components to them. To accurately sample any given signal, the sample rate must be “at least twice the frequency of the maximum frequency component”. Here’s a visualization using an example frequency domain plot, note that there will always be a noise floor so the highest frequency is usually an approximation:

We must identify the highest frequency component, then double it, and make sure we sample at that rate or faster. The minimum rate in which we can sample is known as the Nyquist Rate. In other words, the Nyquist Rate is the minimum rate at which a (finite bandwidth) signal needs to be sampled to retain all of its information. It is an extremely important piece of theory within DSP and SDR that serves as a bridge between continuous and discrete signals.
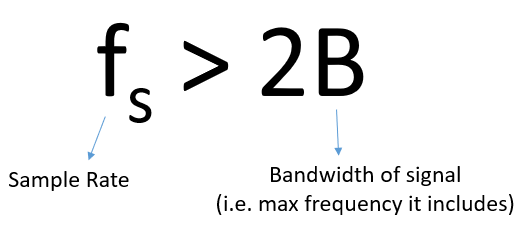
If we don’t sample fast enough we get something called aliasing, which we will learn about later, but we try to avoid it at all costs. What our SDRs do (and most receivers in general) is filter out everything above Fs/2 right before the sampling is performed. If we attempt to receive a signal with too low a sample rate, that filter will chop off part of the signal. Our SDRs go to great lengths to provide us with samples free of aliasing and other imperfections. Because the SDR’s anti-aliasing filter doesn’t go from passband to stopband instantly (it needs a small transition band), the rule of thumb is to assume only the center 4/5 of your sample rate is usable bandwidth, known as “Sean’s 4/5 rule”.
Quadrature Sampling¶
The term “quadrature” has many meanings, but in the context of DSP and SDR it refers to two waves that are 90 degrees out of phase. Why 90 degrees out of phase? Consider how two waves that are 180 degrees out of phase are essentially the same wave with one multiplied by -1. By being 90 degrees out of phase they become orthogonal, and there’s a lot of cool stuff you can do with orthogonal functions. For the sake of simplicity, we use sine and cosine as our two sine waves that are 90 degrees out of phase.
Next let’s assign variables to represent the amplitude of the sine and cosine. We will use \(I\) for the cos() and \(Q\) for the sin():
We can see this visually by plotting I and Q equal to 1:
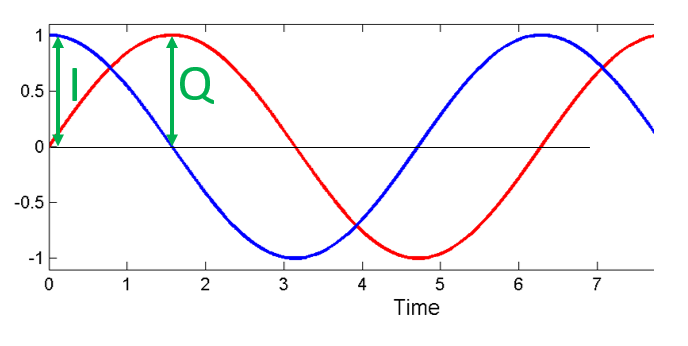
We call the cos() the “in phase” component, hence the name I, and the sin() is the 90 degrees out of phase or “quadrature” component, hence Q. Although if you accidentally mix it up and assign Q to the cos() and I to the sin(), it won’t make a difference for most situations.
IQ sampling is more easily understood by using the transmitter’s point of view. Consider the task of transmitting an RF signal through the air at a certain frequency \(f\) (in Hz). We want to take this sine wave of frequency \(f\) and control its amplitude \(A\) and phase \(\phi\):
The negative sign is purely convention and isn’t important for understanding the concept. At any given moment in time there may be a different amplitude and phase we want to transmit, so we can represent them as a function of time to be more formal:
It turns out that in RF circuitry, controlling the amplitude of a sine wave is easy but controlling the phase is hard, so what we can do is take advantage of the trig identity: \(a \cos(x) + b \sin(x) = A \cos(x - \phi)\) which tells us that a sum of a cos() and sin() of the same frequency, each with a phase of 0, is equivalent to a single cos() with an amplitude \(A\) and phase \(\phi\). Using I and Q instead of \(a\) and \(b\), and adding back in our \(2 \pi f t\), we get:
where
Using this I and Q approach, we can transmit any magnitude and phase we want, using a circuit that looks something like this:
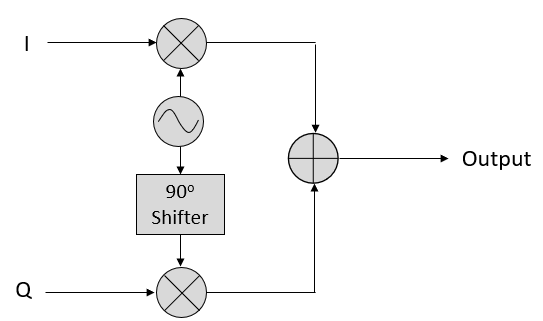
Let’s say we have an IQ sample, which is the single complex number \(I + jQ\). We can modulate that IQ sample onto a sine wave; the amplitude and phase are determined by the IQ sample:
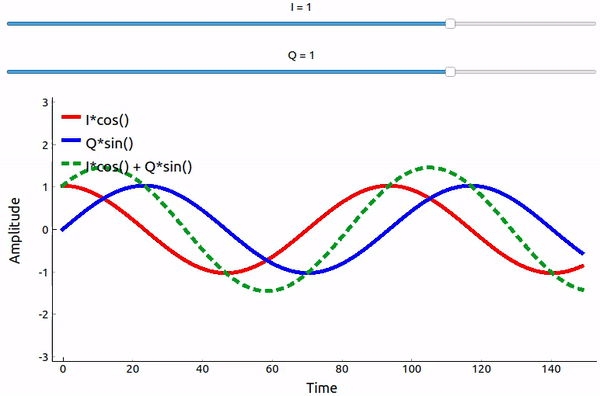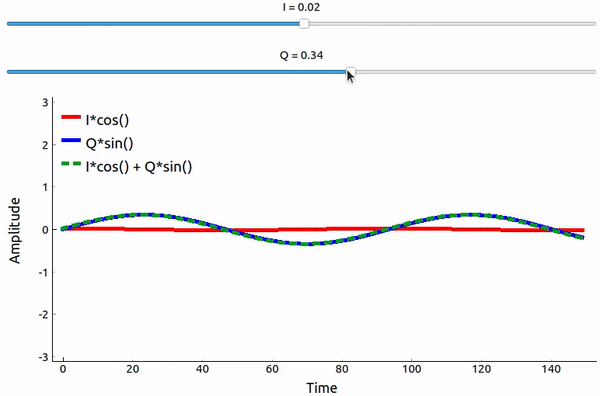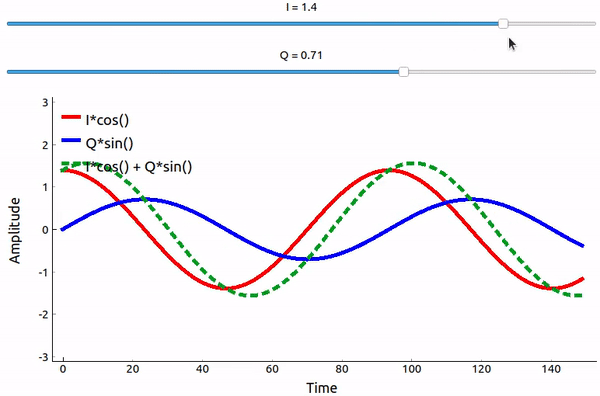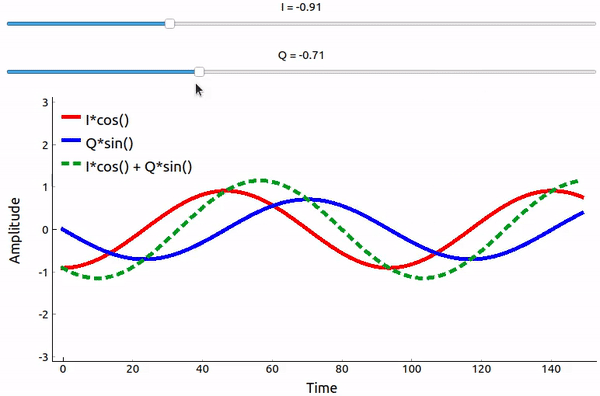
Even though we saw the math, let’s play around with adding two sinusoids that are 90 degrees out of phase. In the video below, there is a slider for adjusting I and another for adjusting Q, the amplitude of the cosine and sine. What is plotted are the cosine (red), sine (blue), and the sum of the two (green).
The code used for this pyqtgraph-based Python app can be found here.
The important takeaways are that when we add the cos() and sin(), we get another pure sine wave of the same frequency but with a different phase and amplitude. Also, the phase shifts as we slowly remove or add one of the two parts (the amplitude also changes). This is all a result of the trig identity: \(a \cos(x) + b \sin(x) = A \cos(x-\phi)\). The “utility” of this behavior is that we can control the phase and amplitude of a resulting sine wave by adjusting the amplitudes I and Q (we don’t have to adjust the phase of the cosine or sine). For example, we could adjust I and Q in a way that keeps the amplitude constant and makes the phase whatever we want. As a transmitter this ability is extremely useful because we know that we need to transmit a sinusoidal signal in order for it to fly through the air as an electromagnetic wave. And it’s much easier to adjust two amplitudes and perform an addition operation compared to adjusting an amplitude and a phase. It also allows us to represent baseband signals more conveniently, keeping them agnostic of the carrier.
Complex Numbers¶
Ultimately, the IQ convention is an alternative way to represent magnitude and phase, which leads us to complex numbers and the ability to represent them on a complex plane. You may have seen complex numbers before in other classes. Take the complex number 0.7-0.4j as an example:
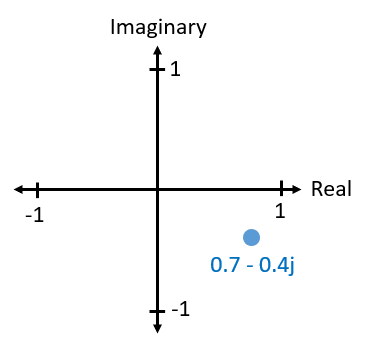
A complex number is really just two numbers together, a real and an imaginary portion. A complex number also has a magnitude and phase, which makes more sense if you think about it as a vector instead of a point. Magnitude is the length of the line between the origin and the point (i.e., length of the vector), while phase is the angle between the vector and 0 degrees, which we define as the positive real axis:
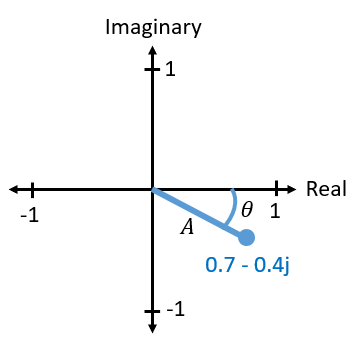
This representation of a sinusoid is known as a “phasor diagram”. It’s simply plotting complex numbers and treating them as vectors. Now what is the magnitude and phase of our example complex number 0.7-0.4j? For a given complex number where \(a\) is the real part and \(b\) is the imaginary part:
In Python you can use np.abs(x) and np.angle(x) for the magnitude and phase. The input can be a complex number or an array of complex numbers, and the output will be a real number(s) (of the data type float).
You may have figured out by now how this vector or phasor diagram relates to IQ convention: I is real and Q is imaginary. From this point on, when we draw the complex plane, we will label it with I and Q instead of real and imaginary. They are still complex numbers!
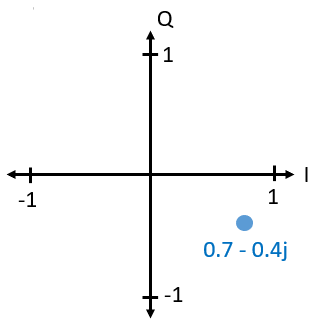
Now let’s say we want to transmit our example point 0.7-0.4j. We will be transmitting:
We can use trig identity \(a \cos(x) + b \sin(x) = A \cos(x-\phi)\) where \(A\) is our magnitude found with \(\sqrt{I^2 + Q^2}\) and \(\phi\) is our phase, equal to \(\tan^{-1} \left( Q/I \right)\). The above equation now becomes:
Even though we started with a complex number, what we are transmitting is a real signal with a certain magnitude and phase; you can’t actually transmit something imaginary with electromagnetic waves. We just use imaginary/complex numbers to represent what we are transmitting. We will talk about the \(f\) shortly.
Complex Numbers in FFTs¶
The above complex numbers were assumed to be time domain samples, but you will also run into complex numbers when you take an FFT. When we covered Fourier series and FFTs last chapter, we had not dived into complex numbers yet. When you take the FFT of a series of samples, it finds the frequency domain representation. We talked about how the FFT figures out which frequencies exist in that set of samples (the magnitude of the FFT indicates the strength of each frequency). But what the FFT also does is figure out the delay (time shift) needed to apply to each of those frequencies, so that the set of sinusoids can be added up to reconstruct the time-domain signal. That delay is simply the phase of the FFT. The output of an FFT is an array of complex numbers, and each complex number gives you the magnitude and phase, and the index of that number gives you the frequency. If you generate sinusoids at those frequencies/magnitudes/phases and sum them together, you’ll get your original time domain signal (or something very close to it, and that’s where the Nyquist sampling theorem comes into play).
Receiver Side¶
Now let’s take the perspective of a radio receiver that is trying to receive a signal (e.g., an FM radio signal). Using IQ sampling, the diagram now looks like:
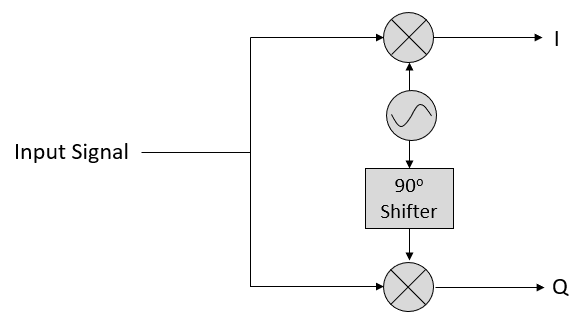
What comes in is a real signal received by our antenna, and those are transformed into IQ values. What we do is sample the I and Q branches individually, using two ADCs, and then we combine the pairs and store them as complex numbers. In other words, at each time step, you will sample one I value and one Q value and combine them in the form \(I + jQ\) (i.e., one complex number per IQ sample). There will always be a “sample rate”, the rate at which sampling is performed. Someone might say, “I have an SDR running at 2 MHz sample rate.” What they mean is that the SDR receives two million IQ samples per second.
If someone gives you a bunch of IQ samples, it will look like a 1D array/vector of complex numbers. This point, complex or not, is what this entire chapter has been building to, and we finally made it.
Throughout this textbook you will become very familiar with how IQ samples work, how to receive and transmit them with an SDR, how to process them in Python, and how to save them to a file for later analysis.
One last important note: the figure above shows what’s happening inside of the SDR. We don’t actually have to generate a sine wave, shift by 90, multiply or add–the SDR does that for us. We tell the SDR what frequency we want to sample at, or what frequency we want to transmit our samples at. On the receiver side, the SDR will provide us the IQ samples. For the transmitting side, we have to provide the SDR the IQ samples. In terms of data type, they will either be complex ints or floats.
Carrier and Downconversion¶
Until this point we have not discussed frequency, but we saw there was an \(f\) in the equations involving the cos() and sin(). This frequency is the center frequency of the signal we actually send through the air (the electromagnetic wave’s frequency). We refer to it as the “carrier” because it carries our signal on a certain RF frequency. When we tune to a frequency with our SDR and receive samples, our information is stored in I and Q; this carrier does not show up in I and Q.
For reference, radio signals such as FM radio, WiFi, Bluetooth, LTE, GPS, etc., usually use a frequency (i.e., a carrier) between 100 MHz and 6 GHz. These frequencies travel really well through the air, but they don’t require super long antennas or a ton of power to transmit or receive. Your microwave cooks food with electromagnetic waves at 2.4 GHz. If there is a leak in the door then your microwave will jam WiFi signals and possibly also burn your skin. Another form of electromagnetic waves is light. Visible light has a frequency of around 500 THz. It’s so high that we don’t use traditional antennas to transmit light. We use methods like LEDs that are semiconductor devices. They create light when electrons jump in between the atomic orbits of the semiconductor material, and the color depends on how far they jump. Technically, radio frequency (RF) is defined as the range from roughly 3 kHz to 300 GHz. These are the frequencies at which energy from an oscillating electric current can radiate off a conductor (an antenna) and travel through space. The 100 MHz to 6 GHz range are the more useful frequencies, at least for most modern applications. Frequencies above 6 GHz have been used for radar and satellite communications for decades, and are now being used in 5G “mmWave” (24 - 29 GHz) to supplement the lower bands and increase speeds.
When we change our IQ values quickly and transmit our carrier, it’s called “modulating” the carrier (with data or whatever we want). When we change I and Q, we change the phase and amplitude of the carrier. Another option is to change the frequency of the carrier, i.e., shift it slightly up or down, which is what FM radio does. It is easy to get confused between the signal we want to transmit (which typically contains many frequency components), and the frequency we transmit it on (our carrier frequency). This will hopefully get cleared up when we cover baseband vs. bandpass signals.
Now back to sampling for a second. Instead of receiving samples by multiplying what comes off the antenna by a cos() and sin() then recording I and Q, what if we fed the signal from the antenna straight into a single ADC? Say the carrier frequency is 2.4 GHz, like WiFi or Bluetooth. That means we would have to sample at 4.8 GHz, as we learned. That’s extremely fast! An ADC that samples that fast costs thousands of dollars. Instead, we “downconvert” the signal so that the signal we want to sample is centered around DC or 0 Hz. This downconversion happens before we sample. We go from:
to just I and Q.
Let’s visualize downconversion in the frequency domain:

When we are centered around 0 Hz, the maximum frequency is no longer 2.4 GHz but is based on the signal’s characteristics since we removed the carrier. Most signals are around 100 kHz to 40 MHz wide in bandwidth, so through downconversion we can sample at a much lower rate. Both the B2X0 USRPs and PlutoSDR contain an RF integrated circuit (RFIC) that can sample up to 56 MHz, which is high enough for most signals we will encounter.
Just to reiterate, the downconversion process is performed by our SDR; as a user of the SDR we don’t have to do anything other than tell it which frequency to tune to. Downconversion (and upconversion) is done by a component called a mixer, usually represented in diagrams as a multiplication symbol inside a circle. The mixer takes in a signal, outputs the down/up-converted signal, and has a third port which is used to feed in an oscillator. The frequency of the oscillator determines the frequency shift applied to the signal, and the mixer is essentially just a multiplication function (recall that multiplying by a sinusoid causes a frequency shift).
Lastly, you may be curious how fast signals travel through the air. Recall from high school physics class that radio waves are just electromagnetic waves at low frequencies (between roughly 3 kHz to 300 GHz). Visible light is also electromagnetic waves, at much higher frequencies (400 THz to 700 THz). All electromagnetic waves travel at the speed of light, which is about 3e8 m/s, at least when traveling through air or a vacuum. Now because they always travel at the same speed, the distance the wave travels in one full oscillation (one full cycle of the sine wave) depends on its frequency. We call this distance the wavelength, denoted as \(\lambda\). You have probably seen this relationship before:
where \(c\) is the speed of light, typically set to 3e8 when \(f\) is in Hz and \(\lambda\) is in meters. In wireless communications this relationship becomes important when we get to antennas, because to receive a signal at a certain carrier frequency, \(f\), you need an antenna that matches its wavelength, \(\lambda\), usually the antenna is \(\lambda/2\) or \(\lambda/4\) in length. However, regardless of the frequency/wavelength, information carried in that signal will always travel at the speed of light, from the transmitter to the receiver. When calculating this delay through the air, a rule of thumb is that light travels approximately one foot in one nanosecond. Another rule of thumb: a signal traveling to a satellite in geostationary orbit and back will take roughly 0.25 seconds for the entire trip.
Receiver Architectures¶
The figure in the “Receiver Side” section demonstrates how the input signal is downconverted and split into I and Q. This arrangement is called “direct conversion”, or “zero IF”, because the RF frequencies are being directly converted down to baseband. Another option is to not downconvert at all and sample so fast to capture everything from 0 Hz to 1/2 the sample rate. This strategy is called “direct sampling” or “direct RF”, and it requires an extremely expensive ADC chip. A third architecture, one that is popular because it’s how old radios worked, is known as “superheterodyne”. It involves downconversion but not all the way to 0 Hz. It places the signal of interest at an intermediate frequency, known as “IF”. A low-noise amplifier (LNA) is simply an amplifier designed for extremely low power signals at the input. Here are the block diagrams of these three architectures, note that variations and hybrids of these architectures also exist:

Baseband and Bandpass Signals¶
We refer to a signal centered around 0 Hz as being at “baseband”. Conversely, “bandpass” refers to when a signal exists at some RF frequency nowhere near 0 Hz, that has been shifted up for the purpose of wireless transmission. There is no notion of a “baseband transmission”, because you can’t transmit something imaginary. A signal at baseband may be perfectly centered at 0 Hz like the right-hand portion of the figure in Section Carrier and Downconversion. It might be near 0 Hz, like the two signals shown below. Those two signals are still considered baseband. Also shown is an example bandpass signal, centered at a very high frequency denoted \(f_c\).
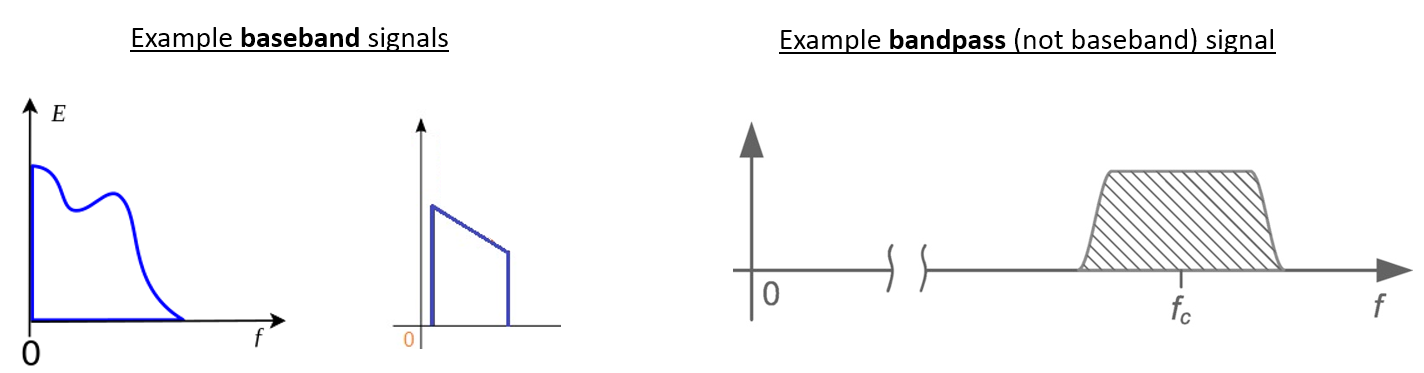
You may also hear the term intermediate frequency, or IF, which is an intermediate conversion step within a radio between baseband and bandpass/RF.
We tend to create, record, or analyze signals at baseband because we can work at a lower sample rate (for reasons discussed in the previous subsection). It is important to note that baseband RF signals are complex signals, while signals at bandpass (e.g., signals we actually transmit over RF) are real. Any signal fed through an antenna must be real, as you cannot directly transmit a complex/imaginary signal. You will know a signal is definitely a complex signal if the negative frequency and positive frequency portions of the signal are not exactly the same. Complex numbers let us represent negative frequencies. In reality there are no negative frequencies; it’s just the portion of the signal below the carrier frequency.
If we do not have any imaginary component in our signal, then we don’t have any Q values (or you can think of all Q values equal to zero). This, in turn, means that we only have cosine signals without any phase shift. A sum of cosine signals without any phase shift will be symmetrical around the y-axis when plotting the frequency domain due to having the same positive and negative components.
In the earlier section where we played around with the complex point 0.7 - 0.4j, that was essentially one sample in a baseband signal. Most of the time you see complex samples (IQ samples), you are at baseband. Signals are rarely represented or stored digitally at RF, because of the amount of data it would take, and the fact we are usually only interested in a small portion of the RF spectrum.
DC Spike and Offset Tuning¶
Once you start working with SDRs, you will often find a large spike in the center of the FFT. It is called a “DC offset” or “DC spike” or sometimes “LO leakage”, where LO stands for local oscillator.
Here’s an example of a DC spike:
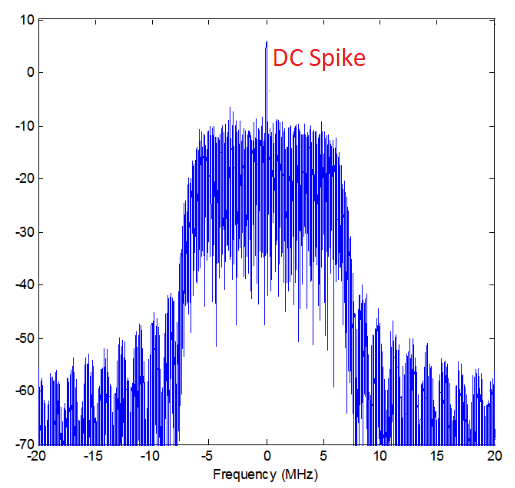
Because the SDR tunes to a center frequency, the 0 Hz portion of the FFT corresponds to the center frequency. That being said, a DC spike doesn’t necessarily mean there is energy at the center frequency. If there is only a DC spike, and the rest of the FFT looks like noise, there is most likely not actually a signal present where it is showing you one.
A DC offset is a common artifact in direct conversion receivers, which is the architecture used for SDRs like the PlutoSDR, RTL-SDR, LimeSDR, and many Ettus USRPs. In direct conversion receivers, an oscillator, the LO, downconverts the signal from its actual frequency to baseband. As a result, leakage from this LO appears in the center of the observed bandwidth. LO leakage is additional energy created through the combination of frequencies. Removing this extra noise is difficult because it is close to the desired output signal. Many RF integrated circuits (RFICs) have built-in automatic DC offset removal, but it typically requires a signal to be present to work. That is why the DC spike will be very apparent when no signals are present.
A quick way to handle the DC offset is to oversample the signal and off-tune it. This technique is called offset tuning. As an example, let’s say we want to view 5 MHz of spectrum at 100 MHz. Instead what we can do is sample at 20 MHz at a center frequency of 95 MHz.
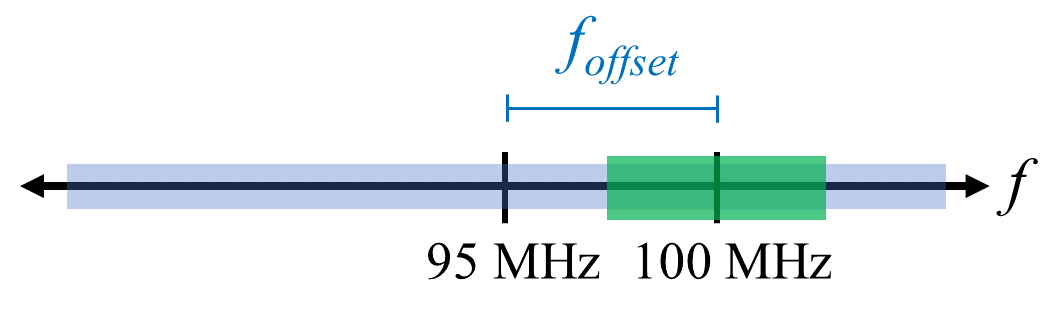
The blue box above shows what is actually sampled by the SDR, and the green box displays the portion of the spectrum we want. Our LO will be set to 95 MHz because that is the frequency to which we ask the SDR to tune. Since 95 MHz is outside of the green box, we won’t get any DC spike.
There is one problem: if we want our signal to be centered at 100 MHz and only contain 5 MHz, we will have to perform a frequency shift, filter, and downsample the signal ourselves (something we will learn how to do later). Fortunately, this process of offtuning, a.k.a applying an LO offset, is often built into the SDRs, where they will automatically perform offtuning and then shift the frequency to your desired center frequency. We benefit when the SDR can do it internally: we don’t have to send a higher sample rate over our USB or Ethernet connection, which bottleneck how high a sample rate we can use.
This subsection regarding DC offsets is a good example of where this textbook differs from others. Your average DSP textbook will discuss sampling, but it tends not to include implementation hurdles such as DC offsets despite their prevalence in practice.
Sampling Using our SDR¶
For SDR-specific information about performing sampling, see one of the following chapters:
- PlutoSDR in Python Chapter
- USRP in Python Chapter
Calculating Average Power¶
In RF DSP, we often like to calculate the power of a signal, such as detecting the presence of the signal before attempting to do further DSP. For a discrete complex signal, i.e., one we have sampled, we can find the average power by taking the magnitude of each sample, squaring it, and then finding the mean:
Remember that the absolute value of a complex number is just the magnitude, i.e., \(\sqrt{I^2+Q^2}\)
In Python, calculating the average power will look like:
avg_pwr = np.mean(np.abs(x)**2)
Here is a very useful trick for calculating the average power of a sampled signal. If your signal has roughly zero mean–which is usually the case in SDR (we will see why later)–then the signal power can be found by taking the variance of the samples. In these circumstances, you can calculate the power this way in Python:
avg_pwr = np.var(x) # (signal should have roughly zero mean)
The reason why the variance of the samples calculates average power is quite simple: the equation for variance is \(\frac{1}{N}\sum^N_{n=1} |x[n]-\mu|^2\) where \(\mu\) is the signal’s mean. That equation looks familiar! If \(\mu\) is zero then the equation to determine variance of the samples becomes equivalent to the equation for power. You can also subtract out the mean from the samples in your window of observation, then take variance. Just know that if the mean value is not zero, the variance and the power are not equal.
Calculating Power Spectral Density¶
Last chapter we learned that we can convert a signal to the frequency domain using an FFT, and the result is called the Power Spectral Density (PSD). The PSD is an extremely useful tool for visualizing signals in the frequency domain, and many DSP algorithms are performed in the frequency domain. But to actually find the PSD of a batch of samples and plot it, we do more than just take an FFT. We must do the following six operations to calculate PSD:
- Take the FFT of our samples. If we have x samples, the FFT size will be the length of x by default. Let’s use the first 1024 samples as an example to create a 1024-size FFT. The output will be 1024 complex floats.
- Take the magnitude of the FFT output, which provides us 1024 real floats.
- Square the resulting magnitude to get power.
- Normalize: divide by the FFT size (\(N\)) and sample rate (\(Fs\)).
- Convert to dB using \(10 \log_{10}()\); we always view PSDs in log scale.
- Perform an FFT shift, covered in the previous chapter, to move “0 Hz” in the center and negative frequencies to the left of center.
Those six steps in Python are:
Fs = 1e6 # lets say we sampled at 1 MHz
# assume x contains your array of IQ samples
N = 1024
x = x[0:N] # we will only take the FFT of the first 1024 samples, see text below
PSD = np.abs(np.fft.fft(x))**2 / (N*Fs)
PSD_log = 10.0*np.log10(PSD)
PSD_shifted = np.fft.fftshift(PSD_log)
Optionally we can apply a window, like we learned about in the Frequency Domain chapter. Windowing would occur right before the line of code with fft().
# add the following line after doing x = x[0:1024]
x = x * np.hamming(len(x)) # apply a Hamming window
To plot this PSD we need to know the values of the x-axis. As we learned last chapter, when we sample a signal, we only “see” the spectrum between -Fs/2 and Fs/2 where Fs is our sample rate. The resolution we achieve in the frequency domain depends on the size of our FFT, which by default is equal to the number of samples on which we perform the FFT operation. In this case our x-axis is 1024 equally spaced points between -0.5 MHz and 0.5 MHz. If we had tuned our SDR to 2.4 GHz, our observation window would be between 2.3995 GHz and 2.4005 GHz. In Python, shifting the observation window will look like:
center_freq = 2.4e9 # frequency we tuned our SDR to
f = np.arange(Fs/-2.0, Fs/2.0, Fs/N) # start, stop, step. centered around 0 Hz
f += center_freq # now add center frequency
plt.plot(f, PSD_shifted)
plt.show()
We should be left with a beautiful PSD!
If you want to find the PSD of millions of samples, don’t do a million-point FFT because it will probably take forever. It will give you an output of a million “frequency bins”, after all, which is too much to show in a plot. Instead I suggest doing multiple smaller PSDs and averaging them together or displaying them using a spectrogram plot. Alternatively, if you know your signal is not changing fast, it’s adequate to use a few thousand samples and find the PSD of those; within that time-frame of a few thousand samples you will likely capture enough of the signal to get a nice representation.
Here is a full code example that includes generating a signal (complex exponential at 50 Hz) and noise. Note that N, the number of samples to simulate, becomes the FFT length because we take the FFT of the entire simulated signal.
import numpy as np
import matplotlib.pyplot as plt
Fs = 300 # sample rate
Ts = 1/Fs # sample period
N = 2048 # number of samples to simulate
t = Ts*np.arange(N)
x = np.exp(1j*2*np.pi*50*t) # simulates sinusoid at 50 Hz
n = (np.random.randn(N) + 1j*np.random.randn(N))/np.sqrt(2) # complex noise with unity power
noise_power = 2
r = x + n * np.sqrt(noise_power)
PSD = np.abs(np.fft.fft(r))**2 / (N*Fs)
PSD_log = 10.0*np.log10(PSD)
PSD_shifted = np.fft.fftshift(PSD_log)
f = np.arange(Fs/-2.0, Fs/2.0, Fs/N) # start, stop, step
plt.plot(f, PSD_shifted)
plt.xlabel("Frequency [Hz]")
plt.ylabel("Magnitude [dB]")
plt.grid(True)
plt.show()
Output:

