 Online Python Console
Online Python Console One-time Donation
One-time Donation


14. IQ 文件与 SigMF¶
在前文的所有 Python 示例中,我们将信号存储为了类型为 “complex float” 的一维 NumPy 数组。 在这一章中,我们将学习如何将信号存储到文件以及如何读入到 Python 里,同时介绍 SigMF 标准。 将信号数据存储在文件中是非常有用的:有时你需要对信号做离线分析、与同事分享、或者打包成数据集。
二进制文件¶
回想一下,数字基带信号其实是就是一串复数。
比如:[0.123 + j0.512, 0.0312 + j0.4123, 0.1423 + j0.06512, …]
以上数据对应 [I+jQ, I+jQ, I+jQ, I+jQ, I+jQ, I+jQ, I+jQ, …]
当我们要将复数保存到文件中时,我们会使用 IQIQIQIQIQIQIQIQ 这样的格式进行保存。 也就是说,我们按顺序存储了一系列整数或浮点数。在读取它们时,我们必须将其重新分离成 [I+jQ, I+jQ, …] 的形式。
虽然我们可以将这一长串复数存储在文本文件或 CSV 文件中,但我们更倾向于将它们保存在所谓的 “二进制文件(Binary File)” 中以节省空间。
毕竟在高采样率下,你所记录的信号文件可能轻松超过多个 GB。
如果你直接在文本编辑器中打开一个二进制文件,它看起来可能和下面的截图差不多。
二进制文件包含了一系列字节,所以你必须自己按照约定的格式解析,但是二进制文件通常是存储数据最高效的方式(同时还有各种压缩算法可用)。
由于我们的信号通常是随机序列般的一串整数或浮点数,所以我们通常不会对其进行压缩。当然,二进制文件也被用于许多其他事情,例如编译过的程序。
用于保存信号时,我们称它们为二进制的 “IQ 文件”,使用文件扩展名 .iq 。

在 Python 中,默认的复数类型是 np.complex128,它使用两个 64 位浮点数('float64')来表示一个复数。
但是在 DSP/SDR 领域,我们倾向于使用 16 位整数或 32 位浮点数,
毕竟我们的 SDR 设备上的 ADC 硬件并不能提供高达 'float64' 的精度。
事实上,大多数 SDR 使用 12 位 ADC,因此我们可以通过存储为 16 位整数(Python 中的 np.int16)来最小化存储空间,
这意味着每个 IQ 采样点占用 4 字节,射频录制文件的大小(字节)将是采样率的 4 倍,这被称为 “Sean 的 4 倍法则”。
在下面的 Python 示例中,我们将使用 np.complex64 ,即用两个 'float32' 来表示一个复数,因为 Python 没有原生的复数整数类型(但这并不妨碍我们将 IQ 数据以整数格式保存到文件中,后文会有说明)。
其实在写代码处理信号时,复数到底是哪种类型并不重要。重要的是当你把数据保存到文件时,请确保它是以 np.complex64`(或交织 IQ 的 :code:`np.int16)类型的数组存储的。
Python 代码示例¶
在 Python 中,我们使用 tofile() 函数将 NumPy 数组存储到文件中。
以下是创建一个简单 QPSK(正交相移键控)信号加噪声并将其保存到同一目录下的文件的代码:
import numpy as np
import matplotlib.pyplot as plt
num_symbols = 10000
# x_symbols 是 QPSK 符号的复数数组:其中每个符号都是一个复数,幅度为 1,相位角对应于四个 QPSK 星座点之一(45, 135, 225 或 315 度)
x_int = np.random.randint(0, 4, num_symbols) # 0 到 3
x_degrees = x_int*360/4.0 + 45 # 45, 135, 225, 315 度
x_radians = x_degrees*np.pi/180.0 # sin() 和 cos() 以弧度为输入
x_symbols = np.cos(x_radians) + 1j*np.sin(x_radians) # 这里创建了 QSPK 复数符号
n = (np.random.randn(num_symbols) + 1j*np.random.randn(num_symbols))/np.sqrt(2) # 单位功率的 AWGN(加性高斯白噪声)
r = x_symbols + n * np.sqrt(0.01) # 叠加功率为 0.01 单位的噪声
print(r)
plt.plot(np.real(r), np.imag(r), '.')
plt.grid(True)
plt.show()
# 将数据保存到 IQ 文件中
print(type(r[0])) # 检查数据类型,发现是 np.complex128!
r = r.astype(np.complex64) # 转换为 np.complex64 类型
print(type(r[0])) # 确认一下类型是否转换成功
r.tofile('qpsk_in_noise.iq') # 保存到文件中
可以看看生成的文件包含多少字节。
理论上应该是 num_symbols * 8 ,因为我们使用的是 np.complex64 类型,每个采样点 8 字节(由 2 个 'float32' 构成,每个长 4 字节)。
我们可以使用 np.fromfile() 来读取这个文件,代码如下:
import numpy as np
import matplotlib.pyplot as plt
samples = np.fromfile('qpsk_in_noise.iq', np.complex64) # 读取文件,记得传入数据类型
print(samples)
# 绘制 IQ 图
plt.plot(np.real(samples), np.imag(samples), '.')
plt.grid(True)
plt.show()
一个常见的错误是忘记给 np.fromfile() 传入文件的数据类型。
由于二进制文件不包含格式信息,默认情况下,np.fromfile() 会认为它读入的是一个 'float64' 数组。
其他编程语言也都有各自读取二进制文件的方法,例如在 MATLAB 中,你可以使用 fread() 函数。
若你想对文件进行可视化分析,请阅读后文内容。
如果你需要处理的数据类型是 'int16' (也就是短整型)或任何其他 NumPy 并不能映射成复数的类型,那么即使它们真实意义是复数,
你也只能先以实数类型读取,然后将它们交错重组回 IQIQIQ… 形式,下面展示了两种不同的方法:
samples = np.fromfile('iq_samples_as_int16.iq', np.int16).astype(np.float32).view(np.complex64)
或者
samples = np.fromfile('iq_samples_as_int16.iq', np.int16)
samples /= 32768 # 转换到 -1 至 + 1 之间 (此步骤可选)
samples = samples[::2] + 1j*samples[1::2] # 转换为 IQIQIQ... 格式
从 MATLAB 迁移而来¶
如果你正在尝试从 MATLAB 迁移到 Python,你可能会想知道如何将 MATLAB 变量和 .mat 文件保存为二进制 IQ 文件。
首先我们需要选择一个数据类型。
例如,如果我们的采样点原始数据是介于 -127 和 +127 之间的整数,那么我们可以使用 8 位整数('int8')。
在这种情况下,我们可以使用以下 MATLAB 代码将采样点保存到二进制 IQ 文件中:
% 假设 IQ 采样点保存在变量 samples 中
disp(samples(1:20))
filename = 'samples.iq'
fwrite(fopen(filename,'w'), reshape([real(samples);imag(samples)],[],1), 'int8')
在 MATLAB 官方文档 中,你可以看到 fwrite() 的所有允许格式类型。
虽说这些格式都被允许,在这里最好还是只使用 'int8'、'int16' 或 'float32'。
在 Python 这边,你可以使用以下代码读取这个文件:
samples = np.fromfile('samples.iq', np.int8)
samples = samples[::2] + 1j*samples[1::2]
print(samples[0:20]) # 检查前 20 个采样点取值是否和 MATLAB 中看到的一致
对于 'float32' 类型的数据,你可以在 Python 中使用 np.complex64 (它的实部需部即依次交错的 'float32'),这样你就可以跳过 samples[::2] + 1j*samples[1::2] 这一步,因为 NumPy 会自动将浮点数两两组合为复数。
可视化分析 IQ 文件(RF 记录)¶
虽然我们在 频率域 章节学习了如何用代码绘制时频谱(瀑布图),但那肯定不如直接用现成的软件快捷简单。 如果你需要分析 RF 记录(IQ 文件)且不想安装任何软件,那么推荐你使用 IQEngine 网站,它是一个用于分析、处理和共享 RF 记录的完整工具包。
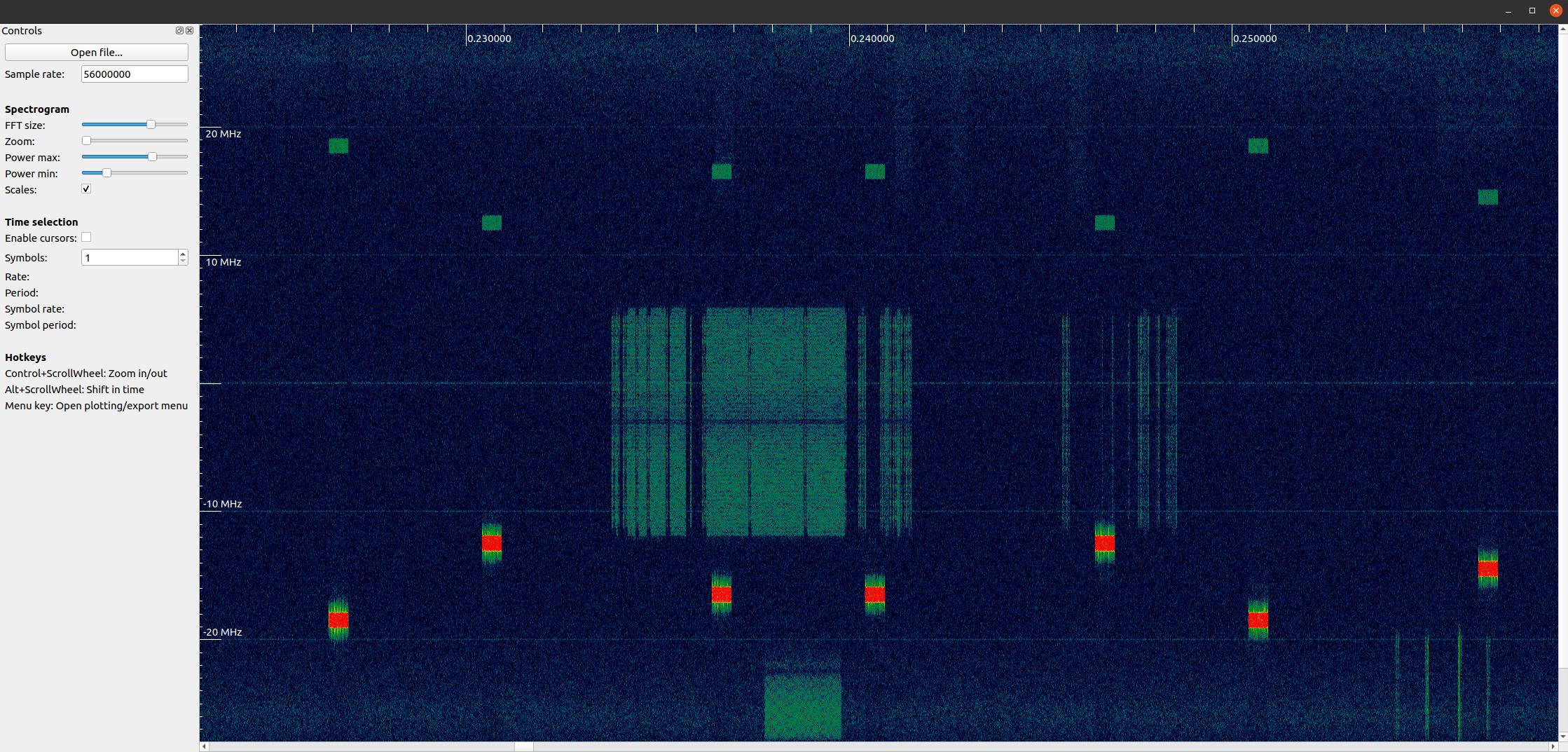
如果你想安装专门的应用程序,可以使用 inspectrum 。inspectrum 是一个相当简单但功能强大的 RF 可视化工具,可以调节色彩映射范围和 FFT 窗口大小。你可以按住 Alt 键并使用滚轮来在时间轴上进行移动。 还可以用内置的测量光标来定位信号之间的时间差,它还支持导出 RF 中的片段到新文件。在 Ubuntu/Debian 系统上,你可以按照以下步骤安装:
sudo apt-get install qt5-default libfftw3-dev cmake pkg-config libliquid-dev
git clone https://github.com/miek/inspectrum.git
cd inspectrum
mkdir build
cd build
cmake ..
make
sudo make install
inspectrum
最大值与饱和¶
当从 SDR 设备接收采样点数据时,你必须了解这些数据的最大值。
许多 SDR 设备默认最大值为 1.0,最小值为 -1.0,以浮点数类型输出。
还有一些 SDR 设备会以整数形式提供样本(通常是 'int16' ),在这种情况下,最大和最小值分别会是 +32767 和 -32768(除非另有说明),
你可以选择除以 32,768 将其归一化为 -1.0 到 1.0 之间的浮点数。
了解你的 SDR 输出的最大值非常重要:当接收到一个极端响亮的信号(或者接收增益设置得太高)时,接收器将会 “饱和(Saturate)”,此时,超越饱和值的采样点的值将全部被截断(毕竟 ADC 的硬件位数是有限的)。
在开发 SDR 应用时,请时刻警惕饱和的出现。
一个饱和的信号在时域内看起来就像锯齿一样不平滑:
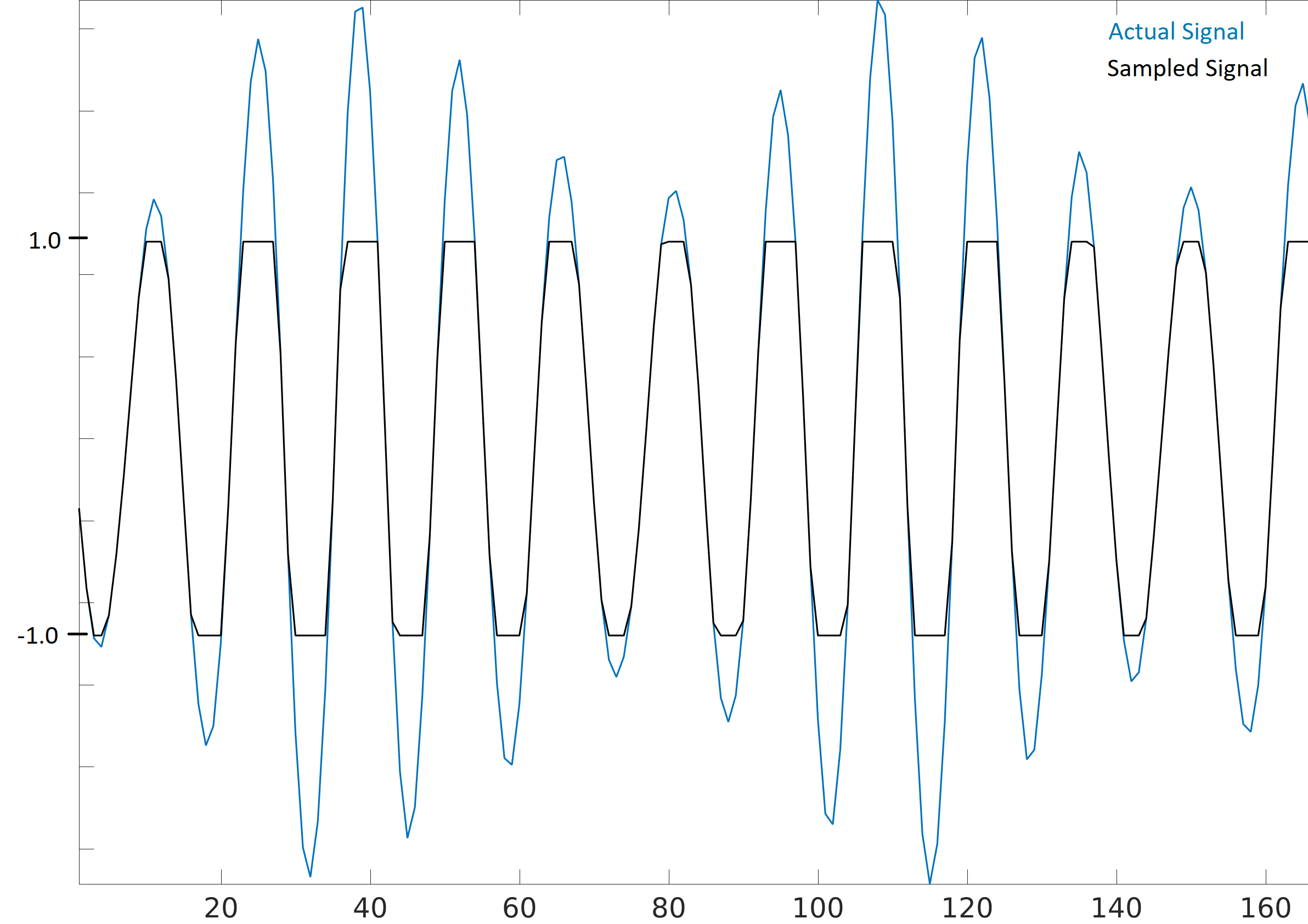
饱和导致的截断会在时域上制造突变,这会让频域看起来很糊。 换句话说,频域会包含由于截断而引入的错误特征,这些特征并不属于真实信号,并且可能会在我们后续分析信号时导致误解。
SigMF 与 IQ 文件标注¶
因为 IQ 文件本身并不包含任何元数据(metadata),所以常见的做法是顺便创建第二个文件(文件名相同但文件扩展名是 .txt 或其他类型),
让这个文件记录信号的相关信息,至少要包括收集信号的采样率,以及 SDR 设备的接收中心频率。
在分析信号之后,元数据文件还可以包含针对有趣特征采样点的索引范围,例如能量峰值点所在的位置。
索引是一个从 0 递增的整数,唯一对应到一个位置上递增的采样点(即一个复数)。
比如,假设你知道从第 492342 个样本点到第 528492 个样本点之间有能量,那么你可以读取文件后直接提取对应数组:samples[492342:528493]。
幸运的是,目前已经有了针对信号记录的元数据格式的开放标准,称为 SigMF 。 通过使用 SigMF 这样的开放标准,多方可以更轻松地共享 RF 记录,并使用不同的工具来操作相同的数据集,例如 IQEngine 。 它还可以防止 RF 数据集的 “位腐烂(Bitrot)”:随着时间的推移,由于一些细节没有与记录本身放在一起,这些细节就因为遗忘而丢失掉了,只能重新花力气和时间分析。
使用 SigMF 描述你的 IQ 文件的最简单的方式是:将 .iq 文件重命名为 .sigmf-data,
创建一个新文件,该文件具有相同的名称但扩展名为 .sigmf-meta,
确保这个元数据文件中的 datatype 字段与数据文件的二进制格式匹配。
这个元文件是一个 JSON 格式的纯文本文件,你可直接用文本编辑器打开它并手动填写(稍后我们将讨论如何以编程方式进行此操作)。
这里有一个 .sigmf-meta 文件的例子,你可以用它作为模板:
{
"global": {
"core:datatype": "cf32_le",
"core:sample_rate": 1000000,
"core:hw": "PlutoSDR with 915 MHz whip antenna",
"core:author": "Art Vandelay",
"core:version": "1.0.0"
},
"captures": [
{
"core:sample_start": 0,
"core:frequency": 915000000
}
],
"annotations": []
}
注意到 core:cf32_le 表示你的 .sigmf-data 文件是 32 位浮点数记录的 IQIQIQIQ… 数据,即上文所说的 np.complex64 复数采样点。
有关其他可用数据类型,请参考 SigMF 官方文档(例如你的数据是实数类型而不是复数类型,或者你使用的是 16 位整数而不是浮点数来节省空间)。
除了数据类型,最重要的元数据项是:core:sample_rate 和 core:frequency 。
最好也记录采集设备的硬件信息(core:hw),这包括 SDR 设备类型和天线信息。
你还可以在 core:description 中记录其他描述信息。
core:version 则表示创建元数据文件时所使用的 SigMF 标准的版本。
如果你喜欢用 Python 脚本来直接收集 RF 信号(比如一些 SDR 框架的 Python API), 那么你可以借助 SigMF Python 包来简化上文的步骤。 在 Ubuntu/Debian 系统上,你可以按照以下步骤安装:
pip install sigmf
借助这个包,为本章开头部分的例子(当时,我们把信号保存在了 qpsk_in_noise.iq 文件中)编写 .sigmf-meta 文件的 Python 代码如下:
import datetime as dt
import numpy as np
import sigmf
from sigmf import SigMFFile
# <来源于上文示例代码>
# r.tofile('qpsk_in_noise.iq')
r.tofile('qpsk_in_noise.sigmf-data') # 将上面一行替换为这一行
# 创建元数据
meta = SigMFFile(
data_file='qpsk_in_noise.sigmf-data', # extension is optional
global_info = {
SigMFFile.DATATYPE_KEY: 'cf32_le',
SigMFFile.SAMPLE_RATE_KEY: 8000000,
SigMFFile.AUTHOR_KEY: 'Your name and/or email',
SigMFFile.DESCRIPTION_KEY: 'Simulation of BPSK with noise',
SigMFFile.VERSION_KEY: sigmf.__version__,
}
)
# 在索引 0 号位记录一个标记信息
meta.add_capture(0, metadata={
SigMFFile.FREQUENCY_KEY: 915000000,
SigMFFile.DATETIME_KEY: dt.datetime.now(dt.timezone.utc).isoformat(),
})
# 检查错误后保存文件
meta.validate()
meta.tofile('qpsk_in_noise.sigmf-meta') # 这个后缀可以自定义
你仅需将上面代码中的 8000000 和 915000000 分别替换为你所使用的采样率和中心频率。
要在 Python 中读取 SigMF 文件请使用以下代码。
在这个例子中,两个 SigMF 文件命名为:qpsk_in_noise.sigmf-meta 和 qpsk_in_noise.sigmf-data。
from sigmf import SigMFFile, sigmffile
# 载入数据集
filename = 'qpsk_in_noise'
signal = sigmffile.fromfile(filename)
samples = signal.read_samples().view(np.complex64).flatten()
print(samples[0:10]) # 让我们看看前十个采样点
# 获取所需元数据
sample_rate = signal.get_global_field(SigMFFile.SAMPLE_RATE_KEY)
sample_count = signal.sample_count
signal_duration = sample_count / sample_rate
更多细节请参考 SigMF Python 官方文档.
谢谢你阅读到这,给你一个小彩蛋:SigMF 的 Logo 实际上是以 SigMF 文件存储的,当该信号的星座图(IQ 图)随时间变化时,它将产生以下动画:
如果你好奇的话,可以自己试试用下面这段 Python 代码读取它们的 Logo 文件 并生成以上的动画。
from pathlib import Path
from tempfile import TemporaryDirectory
import numpy as np
import matplotlib.pyplot as plt
import imageio.v3 as iio
from sigmf import SigMFFile, sigmffile
# 装载数据集
filename = 'sigmf_logo' # 假设这个文件和此脚本在同一目录下
signal = sigmffile.fromfile(filename)
samples = signal.read_samples().view(np.complex64).flatten()
# 在尾部补零,这样动画循环时会容易看出来
samples = np.concatenate((samples, np.zeros(50000)))
sample_count = len(samples)
samples_per_frame = 5000
num_frames = int(sample_count/samples_per_frame)
with TemporaryDirectory() as temp_dir:
filenames = []
output_dir = Path(temp_dir)
for i in range(num_frames):
print(f"frame {i} out of {num_frames}")
# 生成每一帧
fig, ax = plt.subplots(figsize=(5, 5))
samples_frame = samples[i*samples_per_frame:(i+1)*samples_per_frame]
ax.plot(np.real(samples_frame), np.imag(samples_frame), color="cyan", marker=".", linestyle="None", markersize=1)
ax.axis([-0.35,0.35,-0.35,0.35]) # 固定坐标轴和坐标点
ax.set_facecolor('black') # 背景颜色
# 将帧保存到文件中
filename = output_dir.joinpath(f"sigmf_logo_{i}.png")
fig.savefig(filename, bbox_inches='tight')
plt.close()
filenames.append(filename)
# 创建 gif 图
images = [iio.imread(f) for f in filenames]
iio.imwrite('sigmf_logo.gif', images, fps=20)
面向阵列记录的 SigMF Collection¶
如果你拥有相控阵(Phased Array)、MIMO 数字阵列、TDOA 传感器等设备,从而需要记录多通道的 RF 数据,那么你可能想知道如何使用 SigMF 将几个流(Stream)的原始 IQ 存储到文件中。
SigMF Collection 系统专为这些应用程序而设计。
一个 Collection 由一组 SigMF 记录(Recording)(如上文所介绍,每个都是一个元数据文件和一个数据文件)构成,其中使用顶层 .sigmf-collection JSON 文件对这个分组进行记录。
这个 JSON 文件非常简单:内部包含 SigMF 的版本、一个可选的描述,一个 “streams” 列表(集合中每个 SigMF 记录的基本名称)。
以下给出了一个 .sigmf-collection 文件的示例:
{
"collection": {
"core:version": "1.2.0",
"core:description": "a 4-element phased array recording",
"core:streams": [
{
"name": "channel-0"
},
{
"name": "channel-1"
},
{
"name": "channel-2"
},
{
"name": "channel-3"
}
]
}
}
SigMF 记录的名称不一定得是 channel-0 , channel-1 等等,只要它们是唯一的并且每个都包含一个数据文件和一个元数据文件即可。
在上面的示例中,这个 .sigmf-collection 文件可以命名为 4_element_recording.sigmf-collection ,它需要和元数据、数据文件在同一个目录下,此时这个目录内包含:
4_element_recording.sigmf-collectionchannel-0.sigmf-metachannel-0.sigmf-datachannel-1.sigmf-metachannel-1.sigmf-datachannel-2.sigmf-metachannel-2.sigmf-datachannel-3.sigmf-metachannel-3.sigmf-data
你可能注意到了,这样的 RF 记录会制造大量文件,比如一个 16 通道的阵列就会产生 33 个文件!
正因如此,SigMF 引入了 Archive 系统,其本质上就是由 SigMF 打包(Tarball-ing)这一组文件。
虽说是打包,但 SigMF Archive 文件使用扩展名 .sigmf,而不是常见的 .tar !
许多人默认 .tar 文件是压缩过的,但实际上它们并不是,.tar 只是一种将文件组合在一起的方式(本质上是文件串联,没有压缩)。
你可能也见过 .tar.gz 文件,这才一个已经用 gzip 压缩过的 tarball(打包文件)。
对于 SigMF Archive 文件,我们不会对其进行压缩,因为数据文件本身已是二进制的,压缩效果往往一般。
如果你想用 Python 创建一个 SigMF Archive,你可以像下面这样将一个目录中的所有文件打包(Tarball-ing)在一起:
import tarfile
import os
target_dir = '/mnt/c/Users/marclichtman/Downloads/exampletar/' # SigMF 文件目录
with tarfile.open(os.path.join(target_dir, '4_element_recording.sigmf'), 'x') as tar: # x 意味着创建新文件,如果已存在会报错
for file in os.listdir(target_dir):
tar.add(os.path.join(target_dir, file), arcname=file) # arcname 使得文件在 tar 包中不包含完整路径
这就是全部了!
尝试(暂时)将 .sigmf 重命名为 .tar 并在文件浏览器中查看文件。
要在 Python 中打开任何文件(而无需手动提取 tar),你可以使用:
import tarfile
import json
collection_file = '/mnt/c/Users/marclichtman/Downloads/exampletar/4_element_recording.sigmf'
tar_obj = tarfile.open(collection_file)
print(tar_obj.getnames()) # 列出 tar 中的文件名列表
channel_0_meta = tar_obj.extractfile('channel-0.sigmf-meta').read() # 作为例子,读取其中一个元数据文件
channel_0_dict = json.loads(channel_0_meta) # 转换为 Python dict
print(channel_0_dict)
如果要读取 tar 中的 IQ 数据,请使用 np.frombuffer() 而不是 np.fromfile() :
import tarfile
import numpy as np
collection_file = '/mnt/c/Users/marclichtman/Downloads/exampletar/4_element_recording.sigmf'
tar_obj = tarfile.open(collection_file)
channel_0_data_f = tar_obj.extractfile('channel-0.sigmf-data').read() # 数据类型为 bytes
samples = np.frombuffer(channel_0_data_f, dtype=np.int16)
samples = samples[::2] + 1j*samples[1::2] # 转换为 IQIQIQ...
samples /= 32768 # 归一化到 -1 与 1 之间
print(samples[0:10])
如果你想跳转到文件内的不同位置,你可以使用 tar_obj.extractfile('channel-0.sigmf-data').seek(offset) 。
然后,要读取特定数量的字节,你可以使用 .read(num_bytes) 。
请确保字节数是数据类型的字节长度的整数倍!
总结,创建一个新的 SigMF Collection Archive 需要执行以下步骤:
- 为每个通道的数据创建
.sigmf-meta和.sigmf-data文件 - 创建
.sigmf-collection文件 - 将所有文件打包到一个
.sigmf文件中 - (可选)与他人分享
.sigmf文件!
最后,如果想读取其中任何数据,只需记住你不必提取 tarball 而是可以直接在其中阅读。
Midas Blue 文件格式¶
Blue 文件,也称为 BLUEFILES 或 Midas Files,是一种可以表示多种数据结构的文件格式,包括一维和二维数据,并被某些组织用于将原始 RF 信号记录到文件中。
也就是说,在 RF/SDR 的背景下,Blue 文件可以被视为一种 IQ 文件格式。
Blue 文件用于 X-Midas 信号处理框架及其衍生产品 Midas 2k(C++),NeXtMidas(Java)和 XMPy(Python)中。
对于那些听说过 REDAWK 的人,NeXtMidas 的一部分嵌入在其中。
一些应用程序使用文件扩展名 .blue 生成 Blue 文件,而其他应用则使用 .cdif ,它们的底层格式是相同的。
Blue 文件是二进制文件,按以下顺序包含三个组成部分:
- 512 字节的头部(Header),包含文件的元数据;
- 数据,在我们的例子中是二进制 IQ(以 IQIQIQ 的形式表示的整数或浮点数);
- 可选的“扩展头”(也称为尾随字节),包含辅助元数据,以任意键/值对的形式。
头部中包含的字段在 此页面 上有描述。对我们来说重要的有:
- 字节 52:数据格式代码,两个字符。第一个字符表示是实数(S)还是复数(C)。第二个字符指定数据类型,其中
B是 8 位有符号整数,I是 16 位有符号整数,L是 32 位有符号整数,F是 32 位浮点数,D是 64 位浮点数。 - 字节 8:数据表示,四个字符,其中
IEEE表示大端序,EEEI表示小端序(最常见)。 - 字节 24:扩展头开始位置,一个 int32,以 512 字节块为单位。
- 字节 28:扩展头大小,一个 int32,以字节表示。
- 字节 264:采样之间的时间间隔,即 1/sample_rate,作为 float64 以秒表示。
例如,CI 相当于 SigMF 的 ci16_le , CF 是 SigMF 的 cf32_le 。
尽管扩展头(即尾随字节)的长度和起始位置已指定,偷懒的做法是直接忽略文件的最后几千个 IQ 样本,这样就肯定能避开扩展头,从而避免读取错误的 IQ 值。
读取上述字段以及 IQ 数据的 Python 代码如下:
import numpy as np
import os
import matplotlib.pyplot as plt
filename = 'yourfile.blue' # or cdif
filesize = os.path.getsize(filename)
print('File size', filesize, 'bytes')
with open(filename, 'rb') as f:
header = f.read(512)
# 解码头部
dtype = header[52:54].decode('utf-8') # eg 'CI'
endianness = header[8:12].decode('utf-8') # 最好是 'EEEI'!从此以后我们假设它是这样的
extended_header_start = int.from_bytes(header[24:28], byteorder='little') * 512 # in units of bytes
extended_header_size = int.from_bytes(header[28:32], byteorder='little')
if extended_header_size != filesize - extended_header_start:
print('Warning: extended header size seems wrong')
time_interval = np.frombuffer(header[264:272], dtype=np.float64)[0]
sample_rate = 1/time_interval
print('Sample rate', sample_rate/1e6, 'MHz')
# 读取 IQ 数据
if dtype == 'CI':
samples = np.fromfile(filename, dtype=np.int16, offset=512, count=(filesize-extended_header_size))
samples = samples[::2] + 1j*samples[1::2] # 转换为 IQIQIQ...
# 绘制每 1000 个数据点,确保没有错误读入非 IQ 数据部分
print(len(samples))
plt.plot(samples.real[::1000])
plt.show()
“扩展头”(也称为尾随字节),以任意键/值对的形式描述,这些格式在 Blue 文件格式规范 的第 3.3 节中有描述。 它通常包含 RF 频率、增益和接收器/SDR 等信息。下面是解码这些键/值对的 Python 代码,修改自 此代码 :
...
# 读取文件末尾的扩展头
with open(filename, 'rb') as f:
f.seek(filesize-extended_header_size)
ext_header = f.read(extended_header_size)
print("length of extended header", len(ext_header), '\n')
def parse_extended_header(idx):
next_offset = np.frombuffer(ext_header[idx:idx+4], dtype=np.int32)[0]
non_data_length = np.frombuffer(ext_header[idx+4:idx+6], dtype=np.int16)[0]
name_length = ext_header[idx+6]
dataStart = idx + 8
dataLength = dataStart + next_offset - non_data_length
midas_to_np = {'O' : np.uint8, 'B' : np.int8, 'I' : np.int16, 'L' : np.int32, 'X' : np.int64, 'F' : np.float32, 'D' : np.float64}
format_code = chr(ext_header[idx+7])
if format_code == 'A':
val = ext_header[dataStart:dataLength].decode('latin_1')
else:
val = np.frombuffer(ext_header[dataStart:dataLength], dtype=midas_to_np[format_code])[0]
key = ext_header[dataLength:dataLength+name_length].decode('latin_1')
print(key, ' ', val)
return idx + next_offset
next_idx = 0
while next_idx < extended_header_size:
next_idx = parse_extended_header(next_idx)
最后补充说明一点:Blue 文件和其他在同一文件中包含元数据和数据的二进制 IQ 格式是 SigMF 包含一种称为不合格数据集(Non-Conforming Datasets,NCDs)变体的原因,该变体允许在开始和/或结束处有额外字节(二进制 IQ 文件用于元数据)被强制转换为 SigMF 类型的格式。 有关更多信息,请参阅 SigMF 元数据字段:dataset、header_bytes、trailing_bytes。 也就是说,仅从数据读取的角度来看,我们可以将 Blue 文件视为普通的二进制 IQ 文件,只要我们忽略前 512 个字节和文件末尾的任何扩展头字节。
与 Blue 文件相关的外部资源:
- https://web.archive.org/web/20150413061156/http://nextmidas.techma.com/nm/nxm/sys/docs/MidasBlueFileFormat.pdf
- https://sigplot.lgsinnovations.com/html/doc/bluefile.html
- https://lgsinnovations.github.io/sigfile/bluefile.js.html
- http://nextmidas.com.s3-website-us-gov-west-1.amazonaws.com/
- https://web.archive.org/web/20181020012349/http://nextmidas.techma.com/nm/htdocs/usersguide/BlueFiles.html
- https://github.com/Geontech/XMidasBlueReader
