 Online Python Console
Online Python Console One-time Donation
One-time Donation


10. 噪声与随机变量¶
本章将详细讨论噪声的相关主题,特别是噪声在无线通信系统中的建模和处理方式。 涉及的概念包括加性高斯白噪声(AWGN)、复数噪声、信噪比(SNR)、信干噪比(SINR)。 同时,我们还会介绍在无线通信和软件定义无线电(SDR)中广泛使用的分贝(dB)单位。 最后,我们将深入探讨随机变量和随机过程的基本概念,这些概念对于理解噪声、信道效应以及无线通信中的许多信号处理技术至关重要。 我们将涵盖概率分布、期望、方差,以及随机过程如何随时间演变。 这些概念构成了分析噪声以及 SDR 和 DSP 中许多其他主题的数学基础。
高斯噪声¶
噪音的本质是指那些不需要的信号波动,它们会干扰我们所追求的信号,它看起来可能是这样:
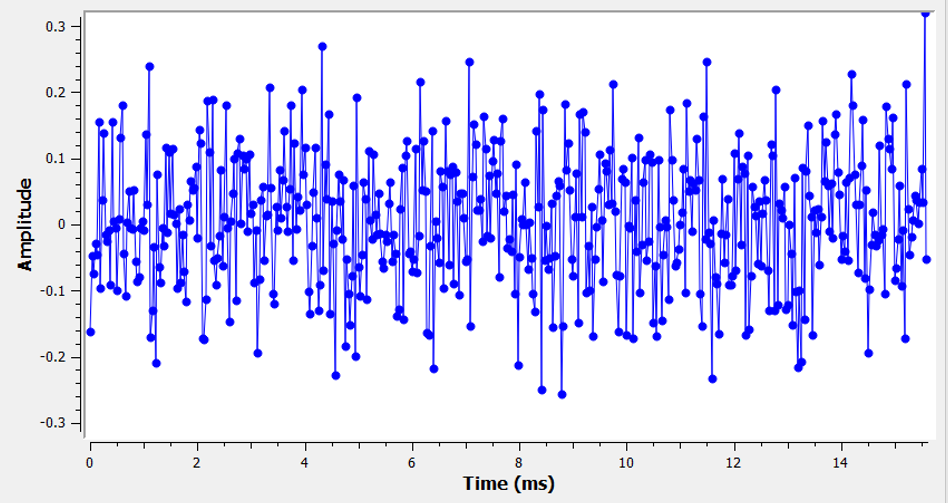
在时间域中,图上的纵坐标的平均值为零。 如果平均值不为零,我们可以减去平均值来得到一个偏置,从而使剩余部分的平均值为零。 此外,需要注意的是图中的各个点 并不是 均匀随机分布的。大多数点接近零,而远离零的点较少。
这种类型的噪声被称为 “高斯噪声”(Gaussian Noise),它是许多自然噪声的良好模型。 例如,在接收机射频组件中,硅原子的热振动可以用高斯噪声来描述。 根据 中心极限定理,多个随机过程的加和结果往往近似服从高斯分布,即便某些过程可能采用其他分布。 对于大量随机事件也是同理,其结果的分布趋近于高斯分布,即便各个事件本身的分布并不是高斯分布。

高斯分布也被称为 “正态” 分布(回想一下钟形曲线)。
高斯分布有两个参数:均值和方差。 上文已经提到均值可以视为零,因为哪怕实际上不为零,你也可以将其视为恒定偏差并减去。 方差则决定了噪声的 “强度”,因为方差越大,越有可能出现较大的数。因此,我们可以说高斯噪声的强度是由方差定义的。
方差等于标准差的平方( \(\sigma^2\) )。
分贝(dB)¶
我们将简要介绍一下分贝(dB)。如果你已经熟悉这个概念,可以跳过这一部分。
当我们需要同时处理小数和大数,或者只是一组非常大的数时,使用分贝是极其有用的。想象一下,在示例 1 和示例 2 中使用相应规模的数字是多么繁琐:
示例1:信号 1 的接收功率为 2 瓦特,底噪为 0.0000002 瓦特。
示例2:垃圾处理器的噪声是安静的农村地区环境噪声的 100,000 倍,链锯的声音甚至比垃圾处理器还大 10,000 倍(以声波功率为单位)。
如果我们不使用 dB,而是用 “线性” 方式来表示这些值,我们需要很大的数值范围来表示示例 1 和示例 2 中的值。 假设我们要绘制信号 1 的接收功率随时间变化的图像,并将 y 轴刻度选为 0 到 3 瓦特,那么噪声的值将远低于可见范围。 因此,为了在同一张图中同时表示差异如此悬殊的两种值,我们需要使用对数坐标。
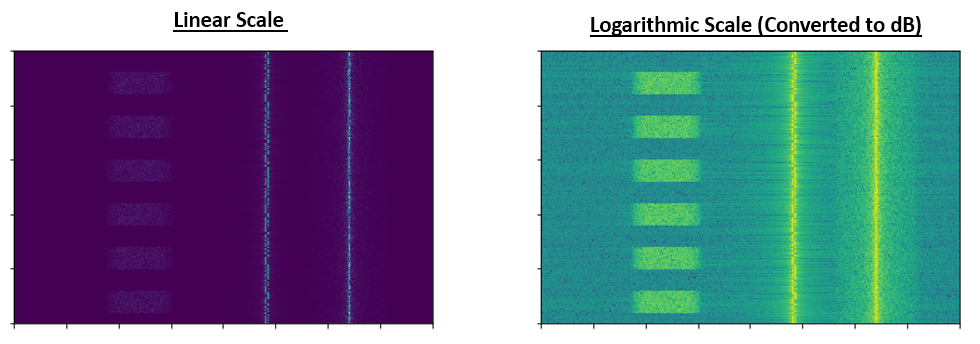
为了进一步说明信号处理中的规模问题造成的影响,下面绘制了两张瀑布图,它们包含了相同的三种信号,且使用了相同的颜色映射(蓝色为最低值,黄色为最高值)。 唯一的区别是,左图使用的是线性坐标,右图使用的是对数坐标(dB)。你会发现,左图对信号的表现能力差很多。
给定一个值 x,我们可以使用以下公式将 x 转换为 dB:
Python 代码:
x_db = 10.0 * np.log10(x)
你可能会发现在其他领域中,表达式中的 10 * 可能需要改为 20 * 。
当处理代表功率的量时,常用系数 10,但当处理代表非功率量如电压或电流时,更适合使用系数 20。
在 DSP 领域,我们通常处理代表功率的量。
我们使用以下方法将 dB 转换回线性数值(普通数值):
Python 代码:
x = 10.0 ** (x_db / 10.0)
为了理解 dB,请不要陷在数学公式里,而是抓住它的核心作用。 在 DSP 中,我们常常需要同时处理非常大和非常小的数,例如信号强度与噪声强度的比较。 dB 的对数刻度使我们能够在表达数字或绘制图形时拥有更大的动态范围。 它还提供了一些便利,比如在通常需要乘法的情况下,我们可以使用加法(正如我们将在 链路预算 章节中看到的那样)。
这里有人们初次接触 dB 时常犯的一些错误:
- 使用自然对数而不是以 10 为底的对数,这个错误很容易犯,因为很多编程语言中,
log()函数实际上是自然对数。 - 在表达数字或标记坐标轴时忘记包含 dB。如果我们使用的是 dB,我们需要在某处标识它。
- 当你使用 dB 时,你需要加减值,而不是乘除,例如:
还需要记住,dB 并不是严格意义上的 “单位”。 一个 dB 的数值本身是无单位的,就像说某物体是 “2 倍大” 一样,在上下文告诉你单位之前,它本身是没有单位的。 dB 是一个相对的概念。在音频处理中,当人们说 dB 时,他们实际上是指 dBA 这个单位(其中 A 是某物理单位)。 在无线电领域,我们通常使用瓦特来表示实际功率。因此,你可能会看到 dBW 这个单位,它其实表示相对于 1 W 的大小。 你也会见到 dBmW(简写为 dBm),它表示相对于 1 mW 的大小。 例如,人们可能会说 “我们的发射机功率设置为 3 dBW”(其实就是 2 瓦)。 有时候人们也会就说 xx dB,这时候表示相对大小,没有单位,比如 “我们接收到了相对于底噪 20 dB 的信号”。 此外,0 dBm = -30 dBW,记住它对你也许会有帮助。
这里还有更多的对照,我建议你也一并记住:
| 线性 | dB |
|---|---|
| 1x | 0 dB |
| 2x | 3 dB |
| 10x | 10 dB |
| 0.5x | -3 dB |
| 0.1x | -10 dB |
| 100x | 20 dB |
| 1000x | 30 dB |
| 10000x | 40 dB |
最后,为了更直观地展示这些数字,以下是一些功率水平示例,以 dBm 为单位:
| 80 dBm | 乡村地区调频广播(FM)电台的发射功率 |
| 62 dBm | 业余无线电(HAM)发射机的最大发射功率 |
| 60 dBm | 家用微博炉的功率 |
| 37 dBm | 典型手持对讲机或无线电发射机的最大发射功率 |
| 27 dBm | 典型的手机发射功率 |
| 15 dBm | 典型的 WiFi 发射功率 |
| 10 dBm | 蓝牙 4.x 最大传输功率 |
| -10 dBm | WiFi 的最大接收功率 |
| -70 dBm | 业余无线电(HAM)可能的接收功率 |
| -100 dBm | WiFi 的最小接收功率 |
| -127 dBm | 典型的 GPS 卫星信号接收功率 |
频域角度看噪声¶
在 频率域 章节中我们讨论了 “傅里叶变换对”(Fourier Pairs),即某个信号在时域及对应频域的样子。 那么,高斯噪声在频域中是什么样子呢?下面的图显示了时域中的一些模拟噪声(图的上部)以及该噪声的功率谱密度(PSD)的图(图的下部)。 这些图是从 GNU Radio 中截取的。
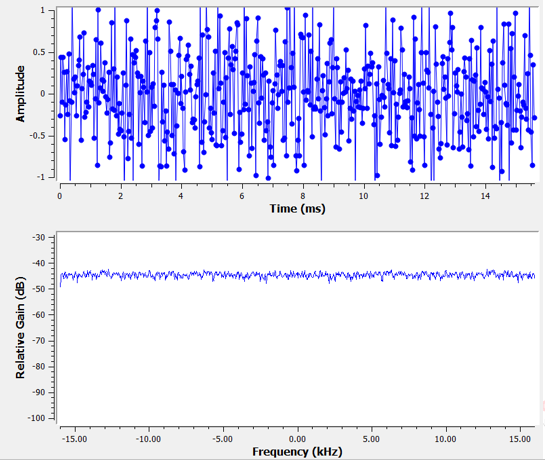
从下方的频谱图可以看到,所有频率上的功率谱密度都大致相同且相对平坦。 这证明,高斯噪声在频域中也是呈高斯分布的。 上面的两个图看起来还是有区别,一方面是因为频谱图显示的是 FFT 的幅度,所以只会有正数, 另一方面是因为它使用对数刻度(dB) 显示幅度。否则,它们两张图看起来会差不多。 我们可以自行用 Python 在时域生成一些噪声,然后进行 FFT 来证明这一点。
import numpy as np
import matplotlib.pyplot as plt
N = 1024 # 选择样本数量用于模拟,可自定义
x = np.random.randn(N)
plt.plot(x, '.-')
plt.show()
X = np.fft.fftshift(np.fft.fft(x))
X = X[N//2:] # 只看正频率,// 表示取整除法
plt.plot(np.real(X), '.-')
plt.show()
请注意,默认情况下, randn() 函数生成的数据符合标准正态分布(均值为 0,方差为 1)。
代码生成的两张图像看起来都会类似这样:
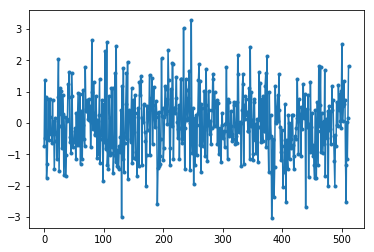
只需对上面的 FFT 输出取对数并进行平均,你就可以复现上文来自 GNU Radio 的那张平坦的 PSD 图像。 我们生成并进行 FFT 的信号是实信号(而不是复信号),任何实信号的 FFT 都会有相抵的负数和正数部分,所以我们只保存了 FFT 输出的正部分(第二部分)。 你可能会问,为什么?难道不能生成复数噪声吗?诶,别急,马上见分晓。
复数噪声¶
“复高斯噪声” 指的是基于基带信号的高斯噪声,其特点是噪声功率在实部和虚部上均匀分布。 同时,重要的是实部和虚部是相互独立的,知道其中一个并不能确定另一个的值。
生成复高斯噪声的 Python 代码是这样的:
n = np.random.randn() + 1j * np.random.randn()
诶,等等!上面的等式在功率上并不能产生与 np.random.randn() 相同 “大小” 的噪声(相同的功率)。
我们可以使用以下方法计算零均值信号(或噪声)的平均功率:
power = np.var(x)
尽管 np.var() 计算的是方差,但是和平均功率是等价的。
对于上文的信号 n 而言,算出来是 2。
为了产生具有 “单位功率” 的复数噪声,即功率为 1(这样便于操作),我们必须使用:
n = (np.random.randn(N) + 1j*np.random.randn(N))/np.sqrt(2) # AWGN with unity power
要在时域中绘制复数噪声,与任何复数信号一样,我们需要两条线:
n = (np.random.randn(N) + 1j*np.random.randn(N))/np.sqrt(2)
plt.plot(np.real(n),'.-')
plt.plot(np.imag(n),'.-')
plt.legend(['real','imag'])
plt.show()
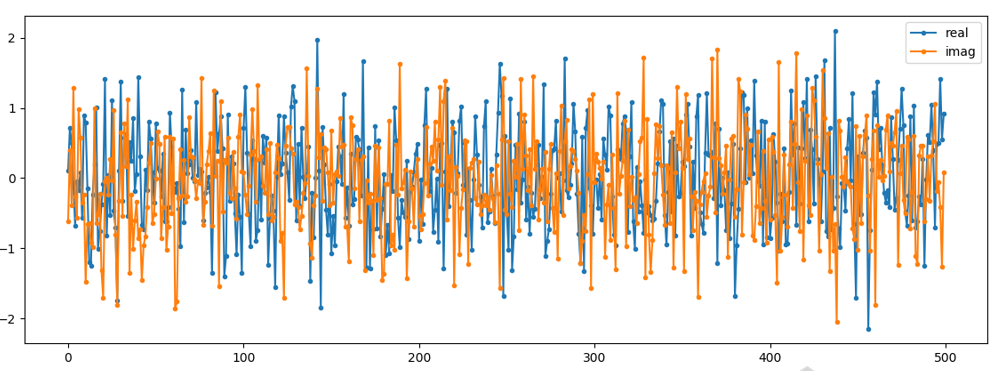
从上图可以看出来,实部和虚部是互相独立的。
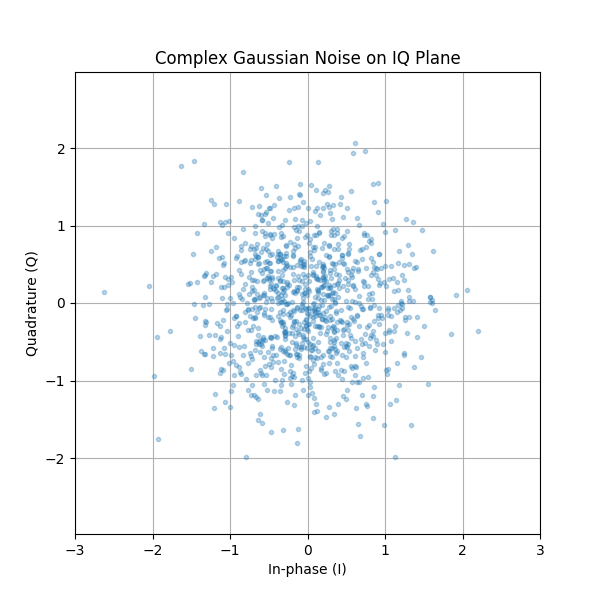
复高斯噪声在 IQ 图上呈现什么样子?在 IQ 图上,实部表示在水平轴上,虚部表示在垂直轴上,它们都是独立的随机高斯分布:
plt.plot(np.real(n),np.imag(n),'.')
plt.grid(True, which='both')
plt.axis([-2, 2, -2, 2])
plt.show()
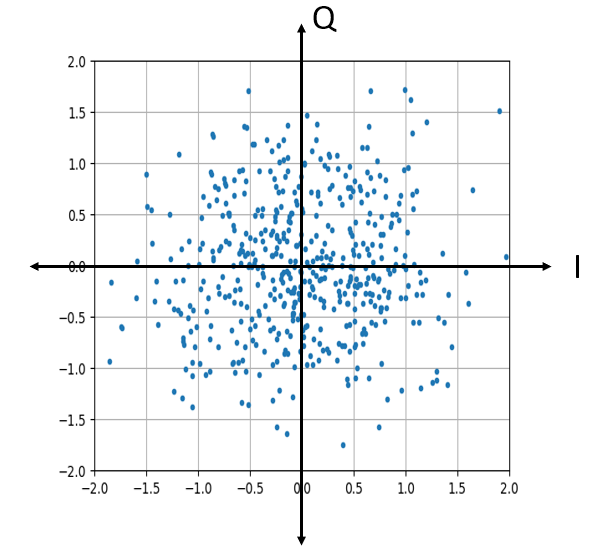
它的形状符合预期:一个以原点为中心的随机斑点分布,即 0+0j。为了增加趣味性,让我们尝试在一个 QPSK 信号中引入噪声,并观察 IQ 图的变化。
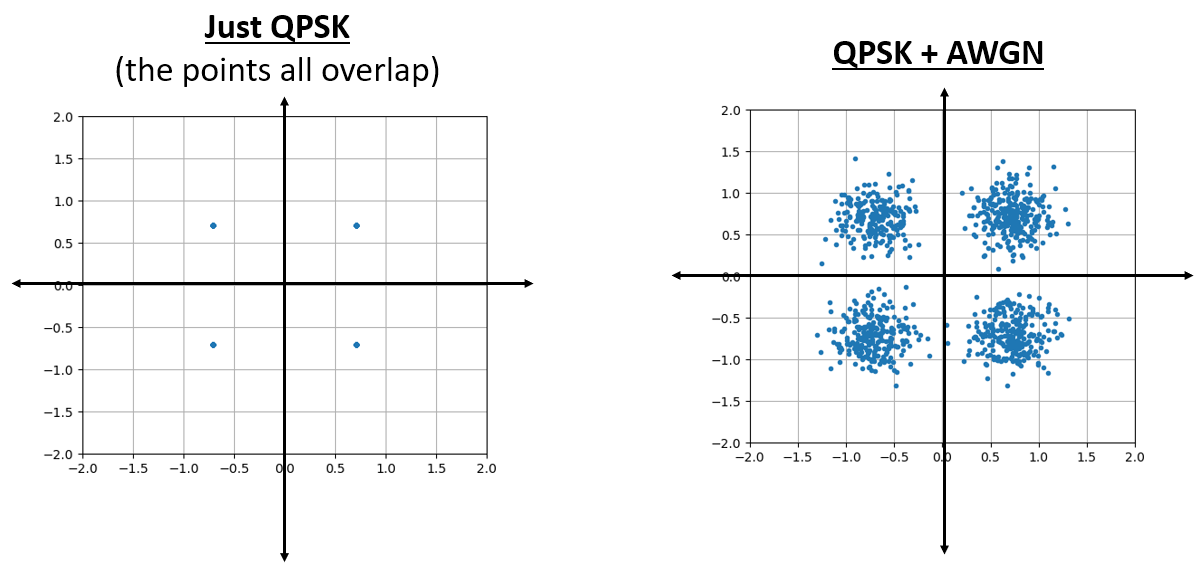
当噪声更强时,会发生什么呢?
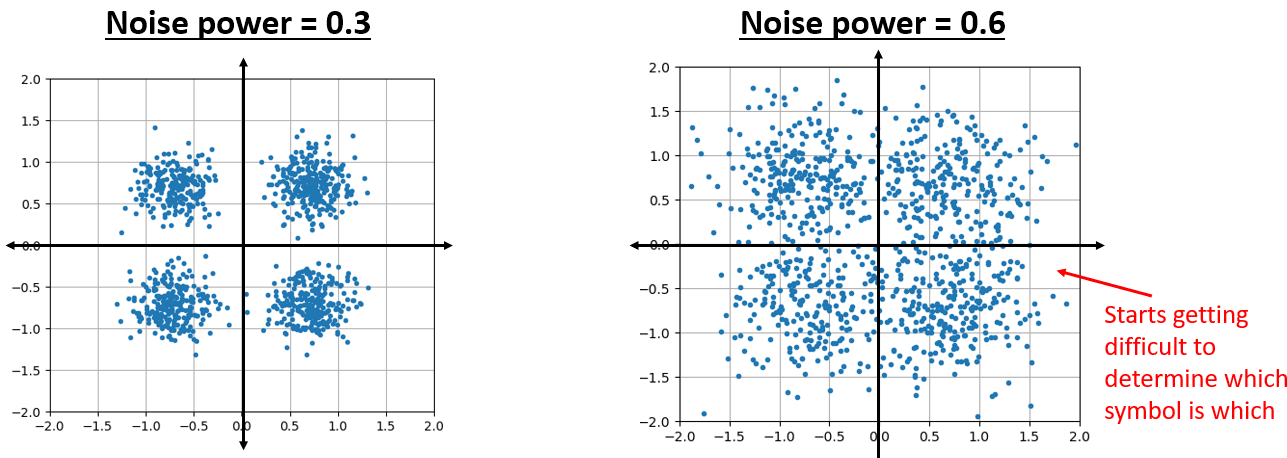
我们逐渐领悟到了无线数据传输的复杂性。 在追求高效率的同时,我们也不得不面对噪声干扰所带来的问题。 我们的目标是在每个数据符号中尽可能地传输更多的比特,但当噪声过高时,接收端很容易收到错误的比特。
AWGN¶
AWGN (Additive White Gaussian Noise,加性高斯白噪声)是 DSP 和 SDR 领域中经常能听到的缩写。 GN 指的是高斯噪声,我们之前已经讨论过了。Additive (加性)表示噪声是被添加到接收信号中的。 White (白)在频域上意味着我们整个观测频带上的频谱是平坦的,在实践中,它几乎总是白噪声,或者近似白噪声。 在本教材中,当处理通信链路和链路预算等问题时,我们将只考虑 AWGN 作为唯一形式的噪声。 非 AWGN 噪声往往是一个专门的课题。
SNR 和 SINR¶
信噪比(Signal-to-Noise Ratio,缩写为 SNR)用于比较信号强度和噪声水平的差异,它是一个无单位的量(表示一个比例)。 SNR 在实践中通常以分贝(dB)表示。在无线通信的模拟实验中,我们经常编码使得信号满足单位功率(即等于 1)。 这样,通过调整生成噪声的方差,我们可以产生 -10 dB 功率的噪声,从而创建 10 dB 的 SNR。
当你看到 “SNR = 0 dB” 时,这意味着信号和噪声功率相等。 正的信噪比意味着信号的功率比噪声大,而负的信噪比意味着噪声的功率比信号大。 负信噪比下检测信号通常相当困难。
像我们之前提到的那样,信号的功率等于信号的方差。因此,我们可以将信噪比表示为信号方差与噪声方差的比率。
信干噪比(Signal-to-Interference-plus-Noise Ratio,缩写为 SINR) 与信噪比(SNR)基本相同,只是在分母上加入了干扰的部分。
干扰的构成取决于具体应用和场景,但通常是另一个信号干扰了我们感兴趣的信号(Signal Of Interest,缩写为 SOI), 并且在频率上与 SOI 重叠、或者由于某种原因无法被滤除。
深入理解随机变量¶
到目前为止,我们一直避免过于数学化,但现在我们需要退后一步,介绍随机变量的概念以及它们在无线通信和 SDR 中的应用。 随机变量 是一个数学概念,它将随机实验的结果映射到数值上。随机变量表示那些在被观察或测量之前其值是不确定的量,比如我们的噪声采样点。设想掷一个六面骰子,在掷之前你不知道会出现什么数字。我们可以定义一个随机变量 \(X\) 来表示掷骰子的结果。 \(X\) 的值是 {1, 2, 3, 4, 5, 6} 中的一个,但在实际掷之前我们不知道是哪一个。
在无线通信和 SDR 的场景中,随机变量无处不在:
- 接收机中的热噪声在每个时刻都可以建模为随机变量
- 受多径衰落影响的接收信号的幅度是随机的
- 变化信道引入的相位偏移可以建模为 \(0\) 到 \(2\pi\) 之间的随机变量
- 甚至我们传输的数据比特也可以被视为随机变量
单个样本 vs. 多个样本
这是一个至关重要的区别,经常引起混淆:
- 随机变量的 单次实现 或 单个样本 只是一个数字——随机实验的一个结果
- 要描述一个随机变量的特征(找到其均值、分布范围等),我们需要 大量实现 ——即多个结果
例如,如果你在 Python 中调用 np.random.randn() 不带任何参数,它返回一个从高斯分布中抽取的随机数。这单个数字几乎无法告诉你分布本身的任何信息。但如果你调用 np.random.randn(10000) 生成 10,000 个样本,你就可以估计分布的均值和方差等属性了。
import numpy as np
# 单个样本 - 只是一个数字
x_single = np.random.randn()
print(x_single) # 可能是 0.534, -1.23, 或其他任何值
# 大量样本 - 现在我们可以描述分布的特征
x_many = np.random.randn(10000)
print(np.mean(x_many)) # 会接近 0
print(np.var(x_many)) # 会接近 1
联合分布¶
到目前为止,我们关注的是单个随机变量。当同时处理两个或更多随机变量时,我们使用 联合分布(Joint Distribution) 。
对于连续随机变量 \(X\) 和 \(Y\) ,联合分布由 联合概率密度函数(Joint PDF) 描述:
联合概率密度函数告诉我们 \(X\) 取值 \(x\) 同时 \(Y\) 取值 \(y\) 的可能性。
从联合概率密度函数中,我们可以计算:
- 边缘概率密度函数(例如 \(f_X(x)\) 或 \(f_Y(y)\) )
- 期望值,如 \(E[XY]\)
- 协方差和相关性
- 涉及两个变量的概率
例如,\(X\) 的边缘概率密度函数可以通过对 \(Y\) 积分得到:
联合分布是理解随机变量之间依赖性、相关性和独立性的数学基础。
概率分布¶
概率分布 描述了随机变量取不同值的可能性。对于连续随机变量,我们使用 概率密度函数(Probability Density Function,PDF) ,记为 \(f_X(x)\) 。PDF 告诉我们随机变量取不同值的相对可能性。
在 SDR 和通信中最重要的分布是 高斯(正态)分布 。均值为 \(\mu\) 、方差为 \(\sigma^2\) 的高斯随机变量 \(X\) 的 PDF 为:
这就是你可能见过的著名 “钟形曲线”。该分布完全由两个参数确定:
- 均值 \(\mu\) :分布的中心
- 方差 \(\sigma^2\) :分布的展宽程度(标准差 \(\sigma\) 是方差的平方根)
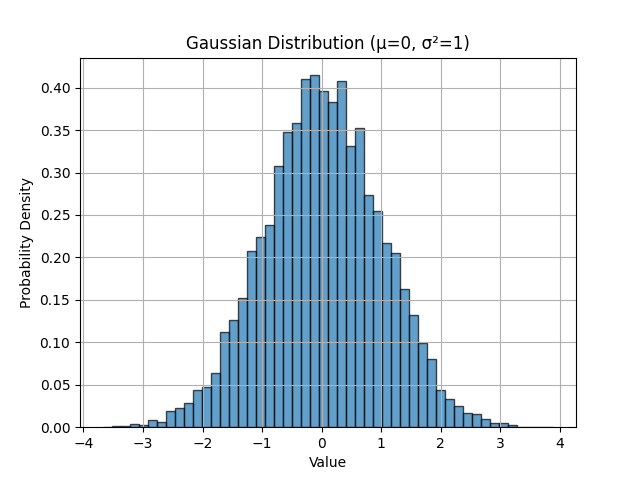
在 Python 中,np.random.randn() 生成的样本来自 \(\mu = 0\) 、 \(\sigma^2 = 1\) 的 标准高斯 分布。我们可以这样可视化:
import numpy as np
import matplotlib.pyplot as plt
# 从标准高斯分布生成 10,000 个样本
x = np.random.randn(10000)
# 创建直方图以可视化分布
plt.hist(x, bins=50, density=True, alpha=0.7, edgecolor='black')
plt.xlabel('Value')
plt.ylabel('Probability Density')
plt.title('Gaussian Distribution (μ=0, σ²=1)')
plt.grid(True)
plt.show()
期望(即均值)¶
随机变量的 期望 或 期望值 ,记为 \(E[X]\) 或 \(\mu\) ,表示其在大量实现中的平均值。对于具有 PDF \(f_X(x)\) 的连续随机变量,期望为:
在实践中,当我们有从分布中抽取的 \(N\) 个样本 \(x_1, x_2, \ldots, x_N\) 时,我们使用 样本均值 来估计期望:
期望是一个 线性算子 ,这意味着:
- \(E[aX + b] = aE[X] + b\) (其中 \(a\) 和 \(b\) 为常数)
- \(E[X + Y] = E[X] + E[Y]\) (对于任意两个随机变量)
这种线性性质在信号处理中非常有用!
方差与标准差¶
随机变量的 方差 ,记为 \(\text{Var}(X)\) 或 \(\sigma^2\) ,衡量其值围绕均值的分散程度。它被定义为偏离均值的平方的期望值:
当我们有 \(N\) 个样本时,我们使用以下公式估计方差:
标准差 \(\sigma\) 就是方差的平方根:\(\sigma = \sqrt{\sigma^2}\) 。
请注意上面公式中 \(\sigma\) 和样本均值上方的 \(\enspace \hat{} \enspace\) 符号(称为 “hat”)。这个帽子符号表示我们是在 估计 均值/方差,估计值不一定精确等于真实的均值/方差,但随着样本数量的增加,它会越来越接近真实值。
关键性质: 如果 \(X\) 是方差为 \(\sigma^2\) 的随机变量,则:
- 缩放:\(\text{Var}(aX) = a^2 \text{Var}(X)\)
- 平移:\(\text{Var}(X + b) = \text{Var}(X)\) (加上常数不改变分散程度)
相应地,标准差 \(\sigma\) 的性质为:
- 缩放:\(\sigma(aX) = a\sigma(X)\)
- 平移:\(\sigma(X+b) = \sigma(X)\)
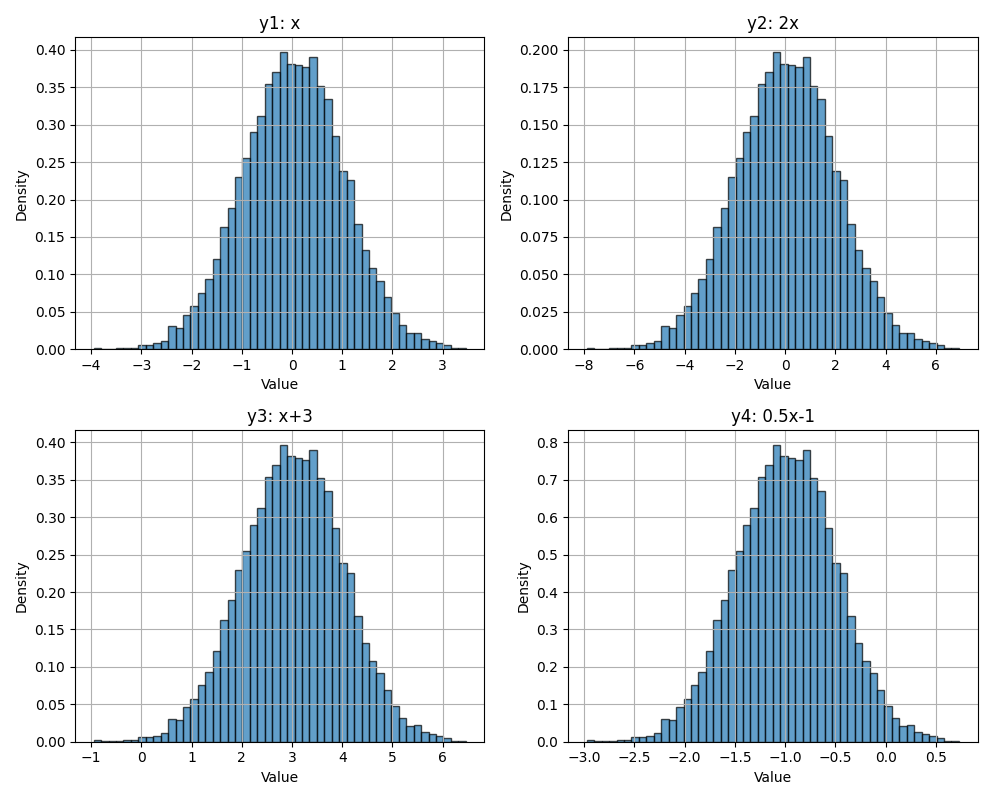
对高斯分布进行缩放和平移(注意 x 轴和 y 轴的刻度变化)
方差与功率
在信号处理中,对于 零均值 信号(均值约为 0),方差等于 平均功率 。这就是为什么我们经常交替使用这两个术语:
这个关系对于分析噪声功率、信噪比(SNR)和链路预算至关重要。
noise_power = 2.0
n = np.random.randn(N) * np.sqrt(noise_power)
print(np.var(n)) # 会约等于 2.0
协方差¶
两个随机变量 \(X\) 和 \(Y\) 之间的 协方差(Covariance) 定义为:
一个等价且通常更方便的形式是:
协方差衡量两个变量如何共同变化:
- 正协方差:它们趋向于一起增大或一起减小
- 负协方差:一个趋向于在另一个减小时增大
- 零协方差:它们是不相关的
如果两个变量都是零均值的,则简化为:
协方差有单位(它不是归一化的),这就是为什么在实践中我们经常使用 相关系数 (Correlation Coefficient):
相关系数是一个介于 -1 和 +1 之间的无量纲值。
变量之和的方差¶
在信号处理中,我们经常处理随机变量之和,比如信号加噪声:
这个和的方差取决于 \(X\) 和 \(Y\) 是否独立(或更一般地说,是否相关)。
完整的一般形式为:
其中 \(\text{Cov}(X,Y)\) 是 \(X\) 和 \(Y\) 之间的 协方差 。
独立的情况
如果 \(X\) 和 \(Y\) 是独立的(或仅仅是不相关的),则表达式简化为:
这个结果在通信中极其重要。例如,如果接收信号为:
其中 \(S\) 是信号,\(N\) 是独立的噪声,那么总功率就是信号功率和噪声功率之和。
这就是为什么 SNR 计算如此简单直接。
复数随机变量¶
在 SDR 中,我们大量使用 复数值信号 ,这意味着我们也需要处理复数随机变量。复数随机变量的形式为:
其中 \(X\) 和 \(Y\) 都是实数值随机变量,分别代表同相(I)和正交(Q)分量。
复高斯噪声
在无线通信中最常见的复数随机变量是 复高斯噪声 ,其中 \(X\) 和 \(Y\) 都是具有相同方差的独立高斯随机变量。
例如,如果 \(X \sim \mathcal{N}(\alpha_1, \sigma_1^2)\) 和 \(Y \sim \mathcal{N}(\alpha_2, \sigma_2^2)\) 是独立的,那么复数随机变量 \(Z = X + jY\) 具有:
- 均值:\(E[Z] = E[X] + jE[Y] = \alpha_1 + j\alpha_2\)
- 方差(功率):\(\text{Var}(Z) = \text{Var}(X) + \text{Var}(Y) = \sigma_1^2 + \sigma_2^2\)
这就是为什么当我们创建单位功率(方差 = 1)的复高斯噪声时,我们使用:
N = 10000
n = (np.random.randn(N) + 1j*np.random.randn(N)) / np.sqrt(2)
print(np.var(n)) # ~ 1
除以 \(\sqrt{2}\) 确保了总功率(I 和 Q 方差之和)等于 1。
# 不做归一化的情况:
n_raw = np.random.randn(N) + 1j*np.random.randn(N)
print(np.var(np.real(n_raw))) # ~ 1
print(np.var(np.imag(n_raw))) # ~ 1
print(np.var(n_raw)) # ~ 2 (总功率)
# 做归一化的情况:
n_norm = n_raw / np.sqrt(2)
print(np.var(n_norm)) # ~ 1 (单位功率)
随机过程¶
到目前为止我们讨论的是随机变量——某个单一时刻的随机值。 随机过程 (也称为 随机过程 ,Stochastic Process)是一组按时间索引的随机变量:
在每个时刻 \(t\) ,\(X(t)\) 都是一个随机变量。可以把随机过程想象成一个随时间随机演变的信号。
在无线通信中的例子:
- 接收机处的噪声:\(N(t)\) 或 \(N[n]\)
- 经历时变衰落的信号:\(H(t)S(t)\)
- 来自 SDR 的采样数据:每批数据都是随机过程的一次实现
平稳过程
如果一个随机过程的统计特性不随时间变化,则称其为 平稳 的。特别地,一个 广义平稳(Wide-Sense Stationary,WSS) 过程具有:
- 恒定均值:对所有 \(t\) ,\(E[X(t)] = \mu\)
- 自相关仅依赖于时间差:\(E[X(t)X(t+\tau)]\) 仅依赖于 \(\tau\) ,而不依赖于 \(t\)
无线系统中的许多噪声源近似为平稳的,这大大简化了分析过程。
白噪声
白噪声 是一种在不同时刻的样本之间不相关的随机过程,且其功率谱密度在所有频率上是恒定的。加性高斯白噪声(AWGN)同时具有以下两个特性:
- 白 :时间上不相关,频谱平坦
- 高斯 :每个样本都服从高斯分布
当我们在 Python 中使用 np.random.randn(N) 生成噪声时,\(N\) 个样本中的每一个都是独立的高斯随机变量,共同构成一个白噪声过程。
独立性与相关性¶
如果知道一个随机变量的值不能提供关于另一个的任何信息,则这两个随机变量 \(X\) 和 \(Y\) 是 独立 的。数学上,它们的联合 PDF 可以分解为:
独立性是一个很强的条件。一个较弱的条件是 不相关 ,即:
对于高斯随机变量,不相关意味着独立(这是高斯分布的一个特殊性质)。
在复高斯噪声中,I 和 Q 分量是独立的:
N = 10000
I = np.random.randn(N)
Q = np.random.randn(N)
# 通过相关性检验独立性
correlation = np.corrcoef(I, Q)[0, 1]
print(f"Correlation between I and Q: {correlation:.4f}") # ~ 0
拓展阅读¶
- Papoulis, A., & Pillai, S. U. (2002). Probability, Random Variables, and Stochastic Processes. McGraw-Hill.
- Kay, S. M. (2006). Intuitive Probability and Random Processes using MATLAB®. Springer.
- https://en.wikipedia.org/wiki/Random_variable
- https://en.wikipedia.org/wiki/Normal_distribution
- https://en.wikipedia.org/wiki/Stochastic_process
- https://en.wikipedia.org/wiki/Additive_white_Gaussian_noise
- https://en.wikipedia.org/wiki/Signal-to-noise_ratio
