 Online Python Console
Online Python Console One-time Donation
One-time Donation


15. IQ файли та SigMF¶
У всіх наших попередніх прикладах на Python ми зберігали сигнали у вигляді 1D NumPy масивів типу “complex float”. У цій главі ми дізнаємося, як зберігати сигнали у файлі, а потім зчитувати їх назад у Python, а також познайомимося зі стандартом SigMF. Зберігання даних сигналів у файлі є надзвичайно корисним: ви можете записати сигнал у файл, щоб вручну проаналізувати його в автономному режимі, поділитися ним з колегою або створити цілий набір даних.
Двійкові файли¶
Нагадаємо, що цифровий сигнал у базовій смузі частот - це послідовність комплексних чисел.
Приклад: [0.123 + j0.512, 0.0312 + j0.4123, 0.1423 + j0.06512, …].
Ці числа відповідають [I+jQ, I+jQ, I+jQ, I+jQ, I+jQ, I+jQ, I+jQ, I+jQ, I+jQ, …].
Коли ми хочемо зберегти комплексні числа у файл, ми зберігаємо їх у форматі IQIQIQIQIQIQIQIQIQIQIQ. Тобто, ми зберігаємо купу цілих чисел або чисел з плаваючою комою підряд, а коли ми їх зчитуємо, ми повинні розділити їх назад на [I+jQ, I+jQ, …].
Хоча комплексні числа можна зберігати в текстовому файлі або csv-файлі, ми вважаємо за краще зберігати їх у так званому “двійковому файлі”, щоб заощадити місце. При високій частоті дискретизації ваші записи сигналів можуть легко займати кілька гігабайт, і ми хочемо бути максимально ефективними в плані використання пам’яті. Якщо ви коли-небудь відкривали файл у текстовому редакторі і він виглядав незрозуміло, як на скріншоті нижче, ймовірно, він був бінарним. Бінарні файли містять серію байтів, і вам доведеться самостійно відстежувати формат. Двійкові файли є найефективнішим способом зберігання даних, якщо припустити, що було виконано все можливе стиснення. Оскільки наші сигнали зазвичай виглядають як випадкова послідовність цілих чисел або чисел з плаваючою комою, ми зазвичай не намагаємося стискати дані. Двійкові файли використовуються для багатьох інших речей, наприклад, для компіляції програм (так званих “бінарників”). Коли вони використовуються для збереження сигналів, ми називаємо їх двійковими “IQ-файлами”, використовуючи розширення .iq.

У Python за замовчуванням комплексним типом є np.complex128, який використовує два 64-бітних числа з плаваючою комою на семпл. Але в DSP/SDR ми, як правило, використовуємо 16-бітні цілі числа або 32-бітні числа з плаваючою комою, тому що АЦП на наших SDR не мають такої точності, щоб гарантувати 64-бітні числа з плаваючою комою. Насправді більшість SDR мають 12-бітні АЦП, тому ми можемо мінімізувати використання сховища, зберігаючи як 16-бітні цілі числа (np.int16 у Python), що означає, що кожен IQ-семпл займатиме 4 байти, і наш RF-запис створюватиме файл розміром у байтах, що дорівнює частоті дискретизації, помноженій на 4, відомий як “правило 4x від Сіна”. У наведених нижче прикладах Python ми будемо використовувати np.complex64, який використовує два 32-бітних числа з плаваючою комою, оскільки Python не має власного комплексного цілочисельного типу (це не заважає нам зберігати IQ як цілі числа у файлі, як ви побачите). Коли ви просто обробляєте сигнал у Python, це не має значення, але коли ви збираєтеся зберегти 1d-масив у файл, ви хочете спочатку переконатися, що це масив np.complex64 (або np.int16 з інтерлівом IQ).
Приклади на Python¶
У Python, зокрема у numpy, ми використовуємо функцію tofile() для збереження масиву numpy у файл. Ось короткий приклад створення простого QPSK-сигналу з шумом і збереження його у файлі в тому ж каталозі, звідки ми запускали наш скрипт:
import numpy as np
import matplotlib.pyplot as plt
num_symbols = 10000
# Масив x_symbols міститиме комплексні числа, що представляють символи QPSK. Кожен символ буде комплексним числом
# з модулем 1 і фазовим кутом, що відповідає одній з чотирьох точок сузір'я QPSK (45, 135, 225 або 315 градусів)
x_int = np.random.randint(0, 4, num_symbols) # від 0 до 3
x_degrees = x_int*360/4.0 + 45 # 45, 135, 225, 315 градусів
x_radians = x_degrees*np.pi/180.0 # sin() та cos() приймають радіани
x_symbols = np.cos(x_radians) + 1j*np.sin(x_radians) # це створює наші комплексні символи QPSK
n = (np.random.randn(num_symbols) + 1j*np.random.randn(num_symbols))/np.sqrt(2) # AWGN з одиничною потужністю
r = x_symbols + n * np.sqrt(0.01) # потужність шуму 0.01
print(r)
plt.plot(np.real(r), np.imag(r), '.')
plt.grid(True)
plt.show()
# Тепер зберігаємо у IQ-файл
print(type(r[0])) # Перевіряємо тип даних. Упс, 128, а не 64!
r = r.astype(np.complex64) # Переводимо в 64
print(type(r[0])) # Переконатись, що це 64
r.tofile('qpsk_in_noise.iq') # Зберегти у файл
Тепер подивіться на деталі створеного файлу і перевірте, скільки у ньому байт. Він має бути num_symbols * 8, тому що ми використовували np.complex64, який має 8 байт на семпл, 4 байти на число з плаваючою комою (2 числа з плаваючою комою на семпл).
Використовуючи новий скрипт Python, ми можемо прочитати цей файл за допомогою np.fromfile(), наприклад, так:
import numpy as np
import matplotlib.pyplot as plt
samples = np.fromfile('qpsk_in_noise.iq', np.complex64) # Читаємо у файл. Треба вказати, у якому він форматі
print(samples)
# Побудуємо сузір'я, щоб переконатися, що воно виглядає правильно
plt.plot(np.real(samples), np.imag(samples), '.')
plt.grid(True)
plt.show()
Велика помилка - забути вказати np.fromfile() формат файлу. Двійкові файли не містять жодної інформації про свій формат. За замовчуванням np.fromfile() припускає, що він читає у форматі масиву float64.
Більшість інших мов мають методи для читання у двійкових файлах, наприклад, у MATLAB ви можете використовувати fread(). Для візуального аналізу RF-файлу дивіться розділ нижче.
Якщо ви коли-небудь матимете справу з int16 (так званими короткими int) або будь-яким іншим типом даних, для якого numpy не має комплексного еквівалента, ви будете змушені читати приклади як справжні, навіть якщо вони насправді є комплексними. Хитрість полягає у тому, щоб прочитати їх як дійсні, але потім перетворити їх назад у формат IQIQIQ… самостійно, кілька різних способів зробити це показано нижче:
samples = np.fromfile('iq_samples_as_int16.iq', np.int16).astype(np.float32).view(np.complex64)
або
samples = np.fromfile('iq_samples_as_int16.iq', np.int16)
samples /= 32768 # конвертуємо в -1 до +1 (необов'язково)
samples = samples[::2] + 1j*samples[1::2] # конвертувати в IQIQIQ...
Перехід з MATLAB¶
Якщо ви намагаєтеся перейти з MATLAB на Python, ви можете поцікавитися, як зберегти змінні MATLAB і файли .mat як двійкові IQ-файли. Спочатку нам потрібно обрати тип формату. Наприклад, якщо наші семпли є цілими числами між -127 і +127, ми можемо використати 8-бітні цілі числа. У такому випадку ми можемо скористатися наступним кодом MATLAB, щоб зберегти семпли у двійковий IQ-файл:
% припустимо, що наші IQ-семпли містяться у змінній samples
disp(samples(1:20))
filename = 'samples.iq'
fwrite(fopen(filename,'w'), reshape([real(samples);imag(samples)],[],1), 'int8')
Ви можете переглянути всі допустимі типи форматів для fwrite() в документації MATLAB. Проте найкраще дотримуватися форматів 'int8', 'int16' або 'float32'.
З боку Python ви можете завантажити цей файл за допомогою:
samples = np.fromfile('samples.iq', np.int8)
samples = samples[::2] + 1j*samples[1::2]
print(samples[0:20]) # переконайтеся, що перші 20 семплів збігаються з MATLAB
Для 'float32', збереженого в MATLAB, ви можете використати np.complex64 у Python, що відповідає інтерлівним float32, і тоді можна пропустити частину samples[::2] + 1j*samples[1::2], тому що numpy автоматично інтерпретує інтерлівні числа з плаваючою комою як комплексні.
Візуальний аналіз радіочастотного файлу¶
Хоча ми навчилися створювати власні графіки спектрограм у розділі Частотна область, ніщо не зрівняється з використанням вже створеного програмного забезпечення. Коли справа доходить до аналізу радіочастотних записів без необхідності нічого встановлювати, найкращим сайтом є IQEngine, який є цілим інструментарієм для аналізу, обробки та обміну радіочастотними записами.
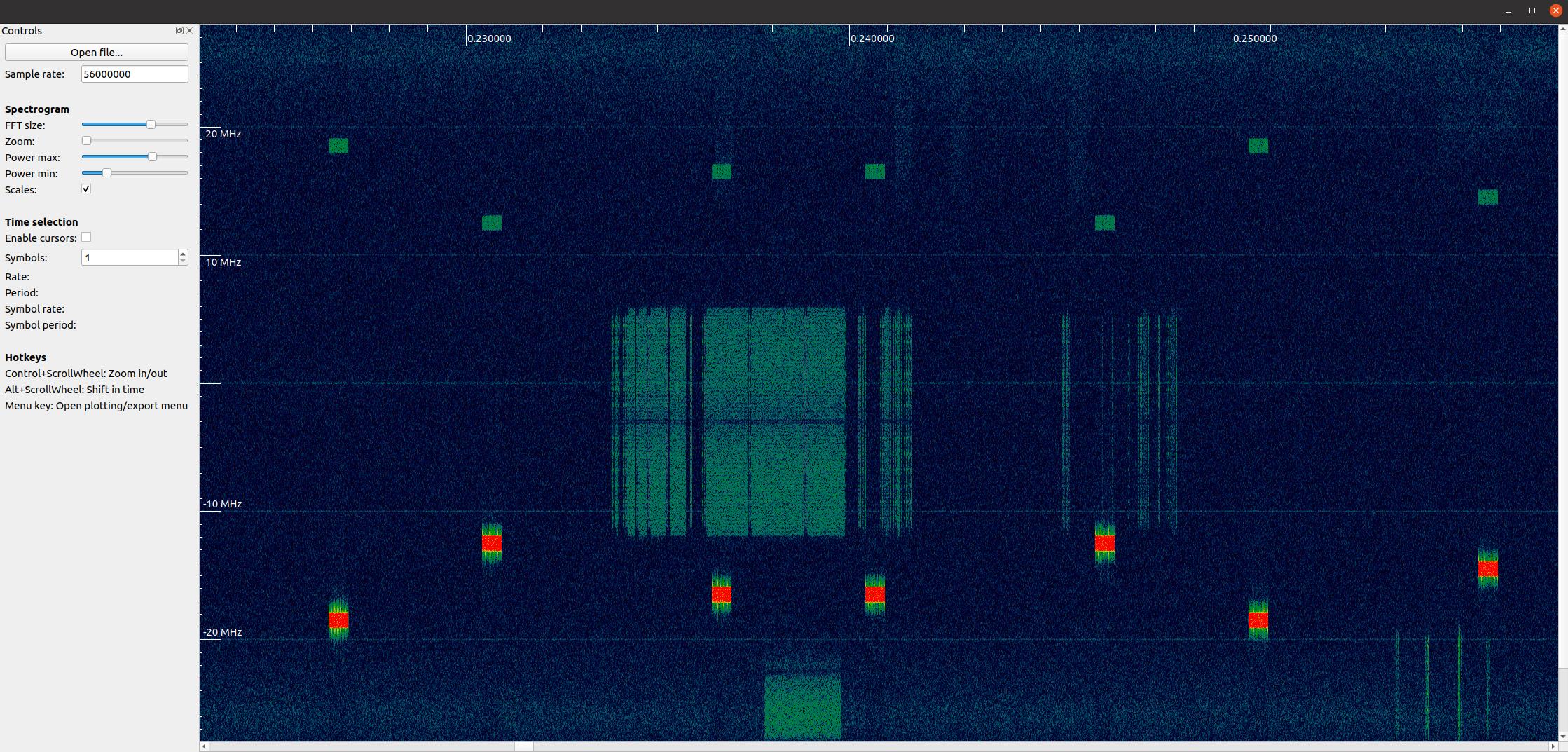
Для тих, кому потрібен десктопний додаток, є також inspectrum. Inspectrum - це досить простий, але потужний графічний інструмент для візуального сканування радіочастотного файлу з тонким контролем діапазону кольорової карти і розміру БПФ (масштабу). Ви можете утримувати клавішу Alt і використовувати колесо прокрутки для переміщення в часі. Програма має додаткові курсори для вимірювання дельта-часу між двома сплесками енергії, а також можливість експортувати фрагмент радіочастотного файлу до нового файлу. Для встановлення на платформах на основі Debian, таких як Ubuntu, скористайтеся наступними командами:
sudo apt-get install qt5-default libfftw3-dev cmake pkg-config libliquid-dev
git clone https://github.com/miek/inspectrum.git
cd inspectrum
mkdir build
cd build
cmake ..
зробити
sudo make install
inspectrum
Максимальні значення та насиченість¶
При отриманні семплів з SDR важливо знати максимальне значення семплу. Багато SDR виводять семпли як числа з плаваючою комою з максимальним значенням 1.0 і мінімальним -1.0. Інші SDR надають вам вибірки як цілі числа, зазвичай 16-розрядні, в цьому випадку максимальне і мінімальне значення буде +32767 і -32768 (якщо не вказано інше), і ви можете розділити на 32,768, щоб перетворити їх у значення з плаваючою комою від -1.0 до 1.0. Причина, по якій необхідно знати максимальне значення для вашого SDR, полягає в насиченні: при отриманні дуже гучного сигналу (або якщо коефіцієнт підсилення встановлено занадто високим), приймач “насититься” і обріже високі значення до того, яким би не було максимальне значення дискретизації. АЦП на наших SDR мають обмежену кількість бітів. При створенні SDR-додатків доцільно завжди перевіряти насичення, і коли це відбувається, ви повинні якось позначити це.
Сигнал, який є насиченим, буде виглядати нестабільним у часовій області, як це показано нижче:
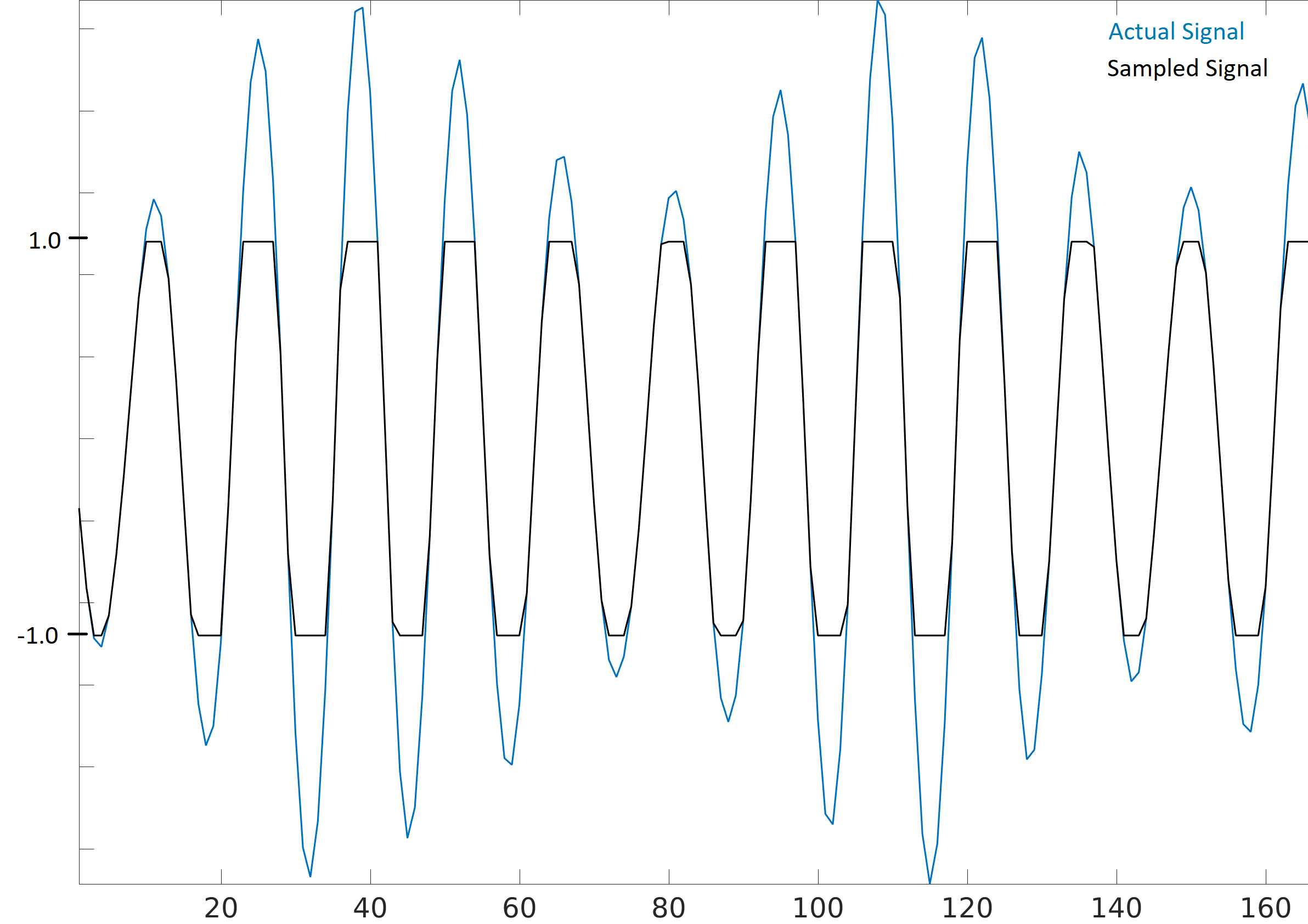
Через різкі зміни в часовій області, спричинені усіченням, частотна область може виглядати розмазаною. Іншими словами, частотна область буде включати помилкові особливості; особливості, які є результатом насичення і насправді не є частиною сигналу, що може збити людей з пантелику при аналізі сигналу.
SigMF та анотування IQ файлів¶
Оскільки сам IQ-файл не має жодних метаданих, пов’язаних з ним, зазвичай створюють 2-й файл, що містить інформацію про сигнал, з тим самим іменем, але з розширенням .txt або іншим. Він повинен містити, як мінімум, частоту дискретизації, яка використовувалася для збору сигналу, і частоту, на яку було налаштовано SDR. Після аналізу сигналу файл метаданих може містити інформацію про діапазони дискретизації цікавих особливостей, таких як сплески енергії. Індекс вибірки - це просто ціле число, яке починається з 0 і збільшується з кожною складною вибіркою. Якби ви знали, що є енергія від зразка 492342 до 528492, то ви могли б прочитати файл і витягнути цю частину масиву: samples[492342:528493].
На щастя, зараз існує відкритий стандарт, який визначає формат метаданих для опису записів сигналів, відомий як SigMF. Використовуючи відкритий стандарт, такий як SigMF, різні сторони можуть легше обмінюватися записами радіосигналів і використовувати різні інструменти для роботи з тими самими наборами даних, такі як IQEngine. Це також запобігає “бітротству” наборів радіочастотних даних, коли деталі захоплення втрачаються з часом через те, що деталі запису не співпадають із самим записом.
Найпростіший (і мінімальний) спосіб використання стандарту SigMF для опису створеного вами бінарного IQ-файлу - перейменувати файл .iq на .sigmf-data і створити новий файл з тим самим ім’ям, але з розширенням .sigmf-meta, і переконатися, що поле типу даних у метафайлі відповідає бінарному формату вашого файлу даних. Цей метафайл є звичайним текстовим файлом, заповненим json, тому ви можете просто відкрити його за допомогою текстового редактора і заповнити вручну (пізніше ми обговоримо, як зробити це програмно). Ось приклад .sigmf-meta файлу, який ви можете використовувати як шаблон:
{
"global": {
"core:datatype": "cf32_le",
"core:sample_rate": 1000000,
"core:hw": "PlutoSDR з 915 МГц штирьовою антеною",
"core:author": "Art Vandelay",
"core:version": "1.0.0"
},
"captures": [
{
"core:sample_start": 0,
"core:frequency": 915000000
}
],
"annotations": []
}
Зверніть увагу, що core:cf32_le вказує на те, що ваші .sigmf-дані мають тип IQIQIQIQ… з 32-бітними числами з плаваючою комою, тобто np.complex64, як ми використовували раніше. Зверніться до специфікацій інших доступних типів даних, наприклад, якщо ви використовуєте дійсні дані замість комплексних, або використовуєте 16-розрядні цілі числа замість плаваючих для економії місця.
Окрім типу даних, найважливішими рядками для заповнення є core:sample_rate та core:frequency. Належною практикою є також введення інформації про апаратне забезпечення (core:hw), яке було використано для захоплення запису, наприклад, тип SDR та антени, а також опис того, що відомо про сигнал(и) у записі у core:description. Поле core:version - це просто версія стандарту SigMF, яка використовувалася на момент створення файлу метаданих.
Якщо ви записуєте радіосигнал з Python, наприклад, використовуючи API Python для SDR, ви можете уникнути необхідності створювати ці файли метаданих вручну, скориставшись пакетом SigMF Python. Його можна встановити на ОС на базі Ubuntu/Debian наступним чином:
pip install sigmf
Нижче наведено код Python для написання файлу .sigmf-meta для прикладу на початку цієї глави, куди ми зберегли qpsk_in_noise.iq:
import datetime as dt
import numpy as np
import sigmf
from sigmf import SigMFFile
# <код з прикладу
# r.tofile('qpsk_in_noise.iq')
r.tofile('qpsk_in_noise.sigmf-data') # замінити рядок вище на цей
# створюємо метадані
meta = SigMFFile(
data_file='qpsk_in_noise.sigmf-data', # extension is optional
global_info = {
SigMFFile.DATATYPE_KEY: 'cf32_le',
SigMFFile.SAMPLE_RATE_KEY: 8000000,
SigMFFile.AUTHOR_KEY: 'Your name and/or email',
SigMFFile.DESCRIPTION_KEY: 'Simulation of qpsk with noise',
SigMFFile.VERSION_KEY: sigmf.__version__,
}
)
# створити ключ захоплення з часовим індексом 0
meta.add_capture(0, metadata={
SigMFFile.FREQUENCY_KEY: 915000000,
SigMFFile.DATETIME_KEY: dt.datetime.now(dt.timezone.utc).isoformat(),
})
# перевірка на помилки та запис на диск
meta.validate()
meta.tofile('qpsk_in_noise.sigmf-meta') # розширення не обов'язкове
Просто замініть 8000000 та 915000000 на змінні, які ви використовували для зберігання частоти дискретизації та центральної частоти відповідно.
Щоб прочитати запис у форматі SigMF у Python, скористайтеся наступним кодом. У цьому прикладі два SigMF-файли слід назвати qpsk_in_noise.sigmf-meta і qpsk_in_noise.sigmf-data.
from sigmf import SigMFFile, sigmffile
# Завантажити набір даних
filename = 'qpsk_in_noise'
signal = sigmffile.fromfile(filename)
samples = signal.read_samples().view(np.complex64).flatten()
print(samples[0:10]) # виводимо перші 10 зразків
# отримуємо метадані та всі анотації
sample_rate = signal.get_global_field(SigMFFile.SAMPLE_RATE_KEY)
sample_count = signal.sample_count
signal_duration = sample_count / sample_rate
За більш детальною інформацією зверніться до документації SigMF Python.
Невеликий бонус для тих, хто дочитав до цього місця: логотип SigMF фактично зберігається як сам запис SigMF, і коли сигнал будується у вигляді сузір’я (IQ-діаграма) у часі, він створює наступну анімацію:
Код на Python, який використовується для зчитування файлу логотипу (розташованого тут) і створення анімованого gif-файлу, показано нижче, для тих, кому цікаво:
from pathlib import Path
from tempfile import TemporaryDirectory
import numpy as np
import matplotlib.pyplot as plt
import imageio.v3 as iio
from sigmf import SigMFFile, sigmffile
# Завантажуємо набір даних
filename = 'sigmf_logo' # вважаємо, що він знаходиться у тому ж каталозі, що і цей скрипт
signal = sigmffile.fromfile(filename)
samples = signal.read_samples().view(np.complex64).flatten()
# Додаємо нулі в кінці, щоб було зрозуміло, коли анімація повторюється
samples = np.concatenate((samples, np.zeros(50000)))
sample_count = len(samples)
samples_per_frame = 5000
num_frames = int(sample_count/samples_per_frame)
with TemporaryDirectory() as temp_dir:
filenames = []
output_dir = Path(temp_dir)
for i in range(num_frames):
print(f"frame {i} out of {num_frames}")
# Побудувати графік кадру
fig, ax = plt.subplots(figsize=(5, 5))
samples_frame = samples[i*samples_per_frame:(i+1)*samples_per_frame]
ax.plot(np.real(samples_frame), np.imag(samples_frame), color="cyan", marker=".", linestyle="None", markersize=1)
ax.axis([-0.35,0.35,-0.35,0.35]) # зберігаємо вісь постійною
ax.set_facecolor('black') # колір фону
# Зберегти графік у файл
filename = output_dir.joinpath(f"sigmf_logo_{i}.png")
fig.savefig(filename, bbox_inches='tight')
plt.close()
filenames.append(filename)
# Створюємо анімований gif
images = [iio.imread(f) for f in filenames]
iio.imwrite('sigmf_logo.gif', images, fps=20)
Колекція SigMF для масивних записів¶
Якщо у вас є фазована антена, цифрова решітка MIMO, датчики TDOA або будь-яка інша ситуація, коли ви записуєте кілька каналів синхронізованих радіоданих, ви, мабуть, замислюєтеся, як зберігати сирі IQ кількох потоків у файлі за допомогою SigMF. Система Колекцій SigMF була розроблена саме для таких випадків; колекція - це просто група записів SigMF (кожен складається з одного метафайлу та одного файлу даних), об’єднаних разом за допомогою верхнього рівня JSON-файлу з розширенням .sigmf-collection. Цей JSON-файл досить простий; він повинен містити версію SigMF, необов’язковий опис, а також список “потоків”, що насправді є базовими назвами кожного запису SigMF у колекції. Ось приклад файлу .sigmf-collection:
{
"collection": {
"core:version": "1.2.0",
"core:description": "a 4-element phased array recording",
"core:streams": [
{
"name": "channel-0"
},
{
"name": "channel-1"
},
{
"name": "channel-2"
},
{
"name": "channel-3"
}
]
}
}
Назви записів необов’язково мають бути channel-0, channel-1, …, вони можуть бути будь-якими, лише б були унікальними і щоб кожна назва відповідала одному файлу даних і одному метафайлу. У наведеному вище прикладі цей файл .sigmf-collection, який ми могли б назвати, наприклад, 4_element_recording.sigmf-collection, повинен бути в тому самому каталозі, що й файли метаданих і даних, тобто в тому ж каталозі ми матимемо:
4_element_recording.sigmf-collectionchannel-0.sigmf-metachannel-0.sigmf-datachannel-1.sigmf-metachannel-1.sigmf-datachannel-2.sigmf-metachannel-2.sigmf-datachannel-3.sigmf-metachannel-3.sigmf-data
Можливо, ви подумаєте, що це призведе до величезної кількості файлів, наприклад, масив із 16 елементів створить 33 файли! Саме з цієї причини SigMF запровадив систему Архівів, яка насправді є терміном SigMF для упаковування набору файлів у tar-архів. Файл архіву SigMF використовує розширення .sigmf, а не .tar! Багато людей вважають, що файли .tar стиснені, але це не так; це просто спосіб об’єднати файли разом (це фактично конкатенація файлів без стиснення). Можливо, ви бачили файл .tar.gz; це tar-архів, який було стиснено за допомогою gzip. Для наших архівів SigMF ми не будемо їх стискати, оскільки файли даних уже є двійковими і не сильно стискаються, особливо якщо використовувалося автоматичне керування підсиленням. Якщо ви хочете створити архів SigMF у Python, ви можете запакувати всі файли в каталозі разом таким чином:
import tarfile
import os
target_dir = '/mnt/c/Users/marclichtman/Downloads/exampletar/' # SigMF файли тут
with tarfile.open(os.path.join(target_dir, '4_element_recording.sigmf'), 'x') as tar: # x означає створити, але помилитись, якщо вже існує
for file in os.listdir(target_dir):
tar.add(os.path.join(target_dir, file), arcname=file) # arcname не дозволяє включати повний шлях у tar
І все! Спробуйте (тимчасово) перейменувати .sigmf на .tar і перегляньте файли у файловому менеджері. Щоб відкривати будь-які файли безпосередньо (без ручного розпакування tar) у Python, ви можете використати:
import tarfile
import json
collection_file = '/mnt/c/Users/marclichtman/Downloads/exampletar/4_element_recording.sigmf'
tar_obj = tarfile.open(collection_file)
print(tar_obj.getnames()) # список рядків із назвами всіх файлів у tar
channel_0_meta = tar_obj.extractfile('channel-0.sigmf-meta').read() # читаємо один з метафайлів як приклад
channel_0_dict = json.loads(channel_0_meta) # перетворюємо на словник Python
print(channel_0_dict)
Для зчитування IQ-семплів безпосередньо з tar замість np.fromfile() ми використаємо np.frombuffer():
import tarfile
import numpy as np
collection_file = '/mnt/c/Users/marclichtman/Downloads/exampletar/4_element_recording.sigmf'
tar_obj = tarfile.open(collection_file)
channel_0_data_f = tar_obj.extractfile('channel-0.sigmf-data').read() # тип bytes
samples = np.frombuffer(channel_0_data_f, dtype=np.int16)
samples = samples[::2] + 1j*samples[1::2] # конвертувати в IQIQIQ...
samples /= 32768 # конвертувати в -1 до +1
print(samples[0:10])
Якщо ви хочете перейти до іншої частини файлу, використовуйте tar_obj.extractfile('channel-0.sigmf-data').seek(offset).
Потім, щоб прочитати конкретну кількість байтів, скористайтеся .read(num_bytes). Переконайтеся, що кількість байтів є кратною вашому типу даних!
Підсумуємо: при створенні нового архіву колекції SigMF слід виконати такі кроки:
- Створити файл .sigmf-meta та .sigmf-data для кожного каналу
- Створити файл .sigmf-collection
- Упакувати всі файли разом у файл .sigmf
- (За бажанням) Поділитися файлом .sigmf з іншими!
